🚀 醫學mT5:醫療領域的開源多語言文本到文本大語言模型
醫學mT5是首個面向醫療領域的開源文本到文本多語言模型。它基於公開可用的mT5檢查點,在英語、西班牙語、法語和意大利語的醫療領域數據上繼續訓練而成,能有效提升多語言醫療文本處理能力。
🚀 快速開始
你可以使用以下代碼加載模型:
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("HiTZ/Medical-mT5-large")
model = AutoModelForSeq2SeqLM.from_pretrained("HiTZ/Medical-mT5-large")
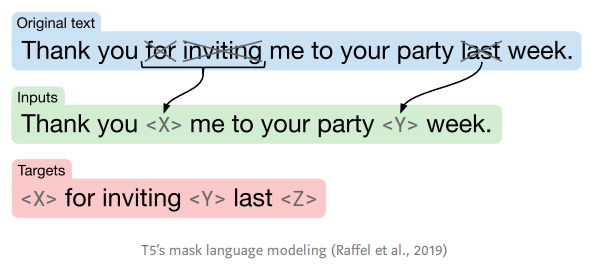
該模型使用T5掩碼語言建模任務進行訓練,你需要針對自己的任務對模型進行微調。
✨ 主要特性
- 多語言支持:支持英語、西班牙語、法語和意大利語,適用於不同語言背景的醫療文本處理。
- 開源模型:開放源代碼和模型,方便研究人員和開發者進行二次開發和應用。
📦 安裝指南
文檔未提及具體安裝步驟,可參考transformers庫的安裝方式,使用pip install transformers進行安裝。
📚 詳細文檔
模型描述
- 開發者:Iker García - Ferrero、Rodrigo Agerri、Aitziber Atutxa Salazar、Elena Cabrio、Iker de la Iglesia、Alberto Lavelli、Bernardo Magnini、Benjamin Molinet、Johana Ramirez - Romero、German Rigau、Jose Maria Villa - Gonzalez、Serena Villata和Andrea Zaninello
- 聯繫方式:[Iker García - Ferrero](https://ikergarcia1996.github.io/Iker - Garcia - Ferrero/) 和 Rodrigo Agerri
- 項目網站:[https://univ - cotedazur.eu/antidote](https://univ - cotedazur.eu/antidote)
- 資助來源:CHIST - ERA XAI 2019 call。Antidote (PCI2020 - 120717 - 2) 由MCIN/AEI /10.13039/501100011033和歐盟NextGenerationEU/PRTR資助
- 模型類型:文本到文本生成
- 支持語言:英語、西班牙語、法語、意大利語
- 許可證:apache - 2.0
- 微調基礎模型:mT5
預訓練設置
| 屬性 |
詳情 |
| 模型類型 |
文本到文本生成 |
| 支持語言 |
英語、西班牙語、法語、意大利語 |
| 許可證 |
apache - 2.0 |
| 微調基礎模型 |
mT5 |
MedMT5預訓練設置
|
Medical mT5 - Large (HiTZ/Medical-mT5-large) |
Medical mT5 - XL (HiTZ/Medical-mT5-xl) |
| 參數數量 |
7.38億 |
30億 |
| 序列長度 |
1024 |
480 |
| 每步令牌數 |
65536 |
30720 |
| 訓練輪數 |
1 |
1 |
| 總令牌數 |
45億 |
45億 |
| 優化器 |
Adafactor |
Adafactor |
| 學習率 |
0.001 |
0.001 |
| 調度器 |
常數 |
常數 |
| 硬件 |
4xA100 |
4xA100 |
| 訓練時間(小時) |
10.5 |
20.5 |
| CO₂等效排放量(千克) |
2.9 |
5.6 |
訓練數據
按語言劃分的數據來源和單詞計數
| 語言 |
數據來源 |
單詞數 |
| 英語 |
ClinicalTrials |
12740萬 |
| 英語 |
EMEA |
1200萬 |
| 英語 |
PubMed |
9.684億 |
| 西班牙語 |
EMEA |
1360萬 |
| 西班牙語 |
PubMed |
840萬 |
| 西班牙語 |
Medical Crawler |
9.18億 |
| 西班牙語 |
SPACC |
35萬 |
| 西班牙語 |
UFAL |
1050萬 |
| 西班牙語 |
WikiMed |
520萬 |
| 法語 |
PubMed |
140萬 |
| 法語 |
Science Direct |
1520萬 |
| 法語 |
Wikipedia - Médecine |
500萬 |
| 法語 |
EDP |
4.8萬 |
| 法語 |
Google Patents |
6.54億 |
| 意大利語 |
Medical Commoncrawl - IT |
6700萬 |
| 意大利語 |
Drug instructions |
3050萬 |
| 意大利語 |
Wikipedia - Medicina |
1330萬 |
| 意大利語 |
E3C Corpus - IT |
1160萬 |
| 意大利語 |
Medicine descriptions |
630萬 |
| 意大利語 |
Medical theses |
580萬 |
| 意大利語 |
Medical websites |
400萬 |
| 意大利語 |
PubMed |
230萬 |
| 意大利語 |
Supplement description |
130萬 |
| 意大利語 |
Medical notes |
97.5萬 |
| 意大利語 |
Pathologies |
15.7萬 |
| 意大利語 |
Medical test simulations |
2.6萬 |
| 意大利語 |
Clinical cases |
2萬 |
評估
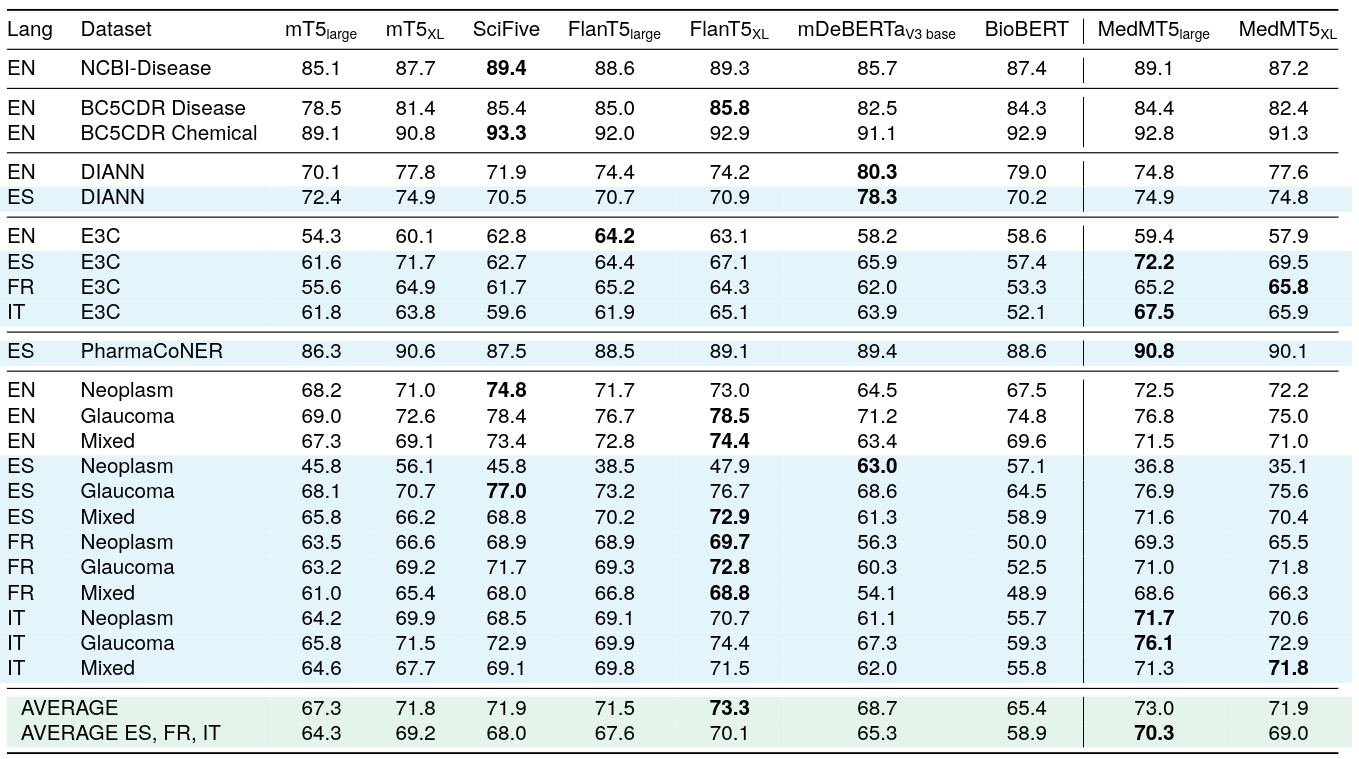
用於序列標註的Medical mT5
已發佈兩個針對多語言序列標註進行微調的Medical mT5模型:
序列標註的單任務監督F1分數
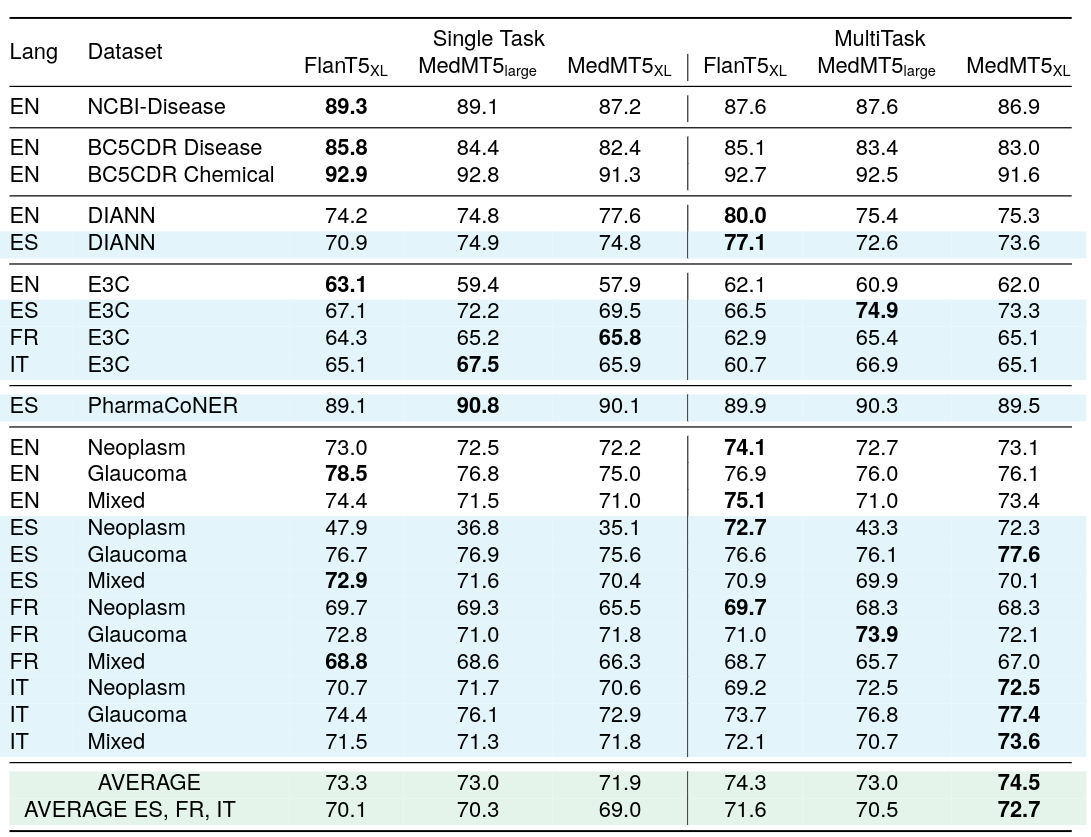
序列標註的多任務監督F1分數
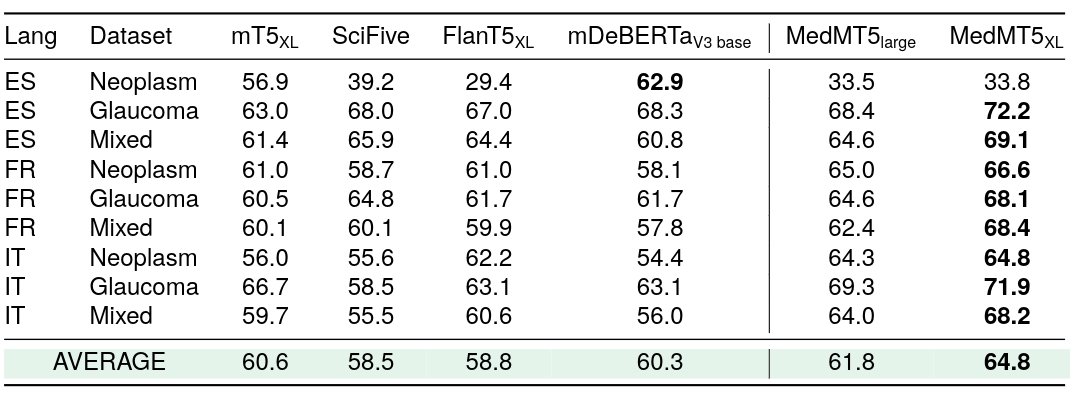
論點挖掘的零樣本F1分數(模型在英語上訓練,在西班牙語、法語和意大利語上評估)
倫理聲明
在開發醫療領域的多語言文本到文本模型Medical mT5的研究中,我們認識到其存在倫理影響。一方面,這項工作的廣泛影響在於它有潛力改善跨語言的醫療溝通和理解,從而提高不同語言社區的醫療服務可及性和質量。另一方面,它也引發了與隱私和數據安全相關的倫理考量。
為創建多語言語料庫,我們採取了措施對敏感患者信息進行匿名化和保護,遵守每種語言管轄區域的數據保護法規,或從明確按照隱私和安全法規及指南處理此問題的來源獲取數據。此外,我們致力於在模型的開發和評估過程中保持透明度和公平性。我們努力確保基準測試具有代表性且無偏差,並將在未來繼續監測和解決任何潛在的偏差。最後,我們強調對開源的承諾,將數據、代碼和模型公開提供,以促進研究社區的合作。
引用
@misc{garcíaferrero2024medical,
title={Medical mT5: An Open-Source Multilingual Text-to-Text LLM for The Medical Domain},
author={Iker García-Ferrero and Rodrigo Agerri and Aitziber Atutxa Salazar and Elena Cabrio and Iker de la Iglesia and Alberto Lavelli and Bernardo Magnini and Benjamin Molinet and Johana Ramirez-Romero and German Rigau and Jose Maria Villa-Gonzalez and Serena Villata and Andrea Zaninello},
year={2024},
eprint={2404.07613},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
相關鏈接

%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多種語言
Transformers 支持多種語言