🚀 Medical mT5: 医療分野向けのオープンソース多言語テキスト生成LLM
Medical mT5は、医療分野向けの初のオープンソース多言語テキスト生成モデルです。英語、スペイン語、フランス語、イタリア語の医療分野データで公開されているmT5チェックポイントを継続学習することで開発されました。
🚀 クイックスタート
モデルの読み込み
以下のコードを使用してモデルを読み込むことができます。
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("HiTZ/Medical-mT5-large")
model = AutoModelForSeq2SeqLM.from_pretrained("HiTZ/Medical-mT5-large")
このモデルはT5のマスク言語モデリングタスクで学習されています。独自のタスクに合わせてモデルを微調整する必要があります。
✨ 主な機能
- 多言語対応:英語、スペイン語、フランス語、イタリア語に対応しています。
- テキスト生成:医療分野のテキスト生成タスクに適用できます。
📦 インストール
モデルを使用するには、transformersライブラリが必要です。以下のコマンドでインストールできます。
pip install transformers
💻 使用例
基本的な使用法
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("HiTZ/Medical-mT5-large")
model = AutoModelForSeq2SeqLM.from_pretrained("HiTZ/Medical-mT5-large")
input_text = "The best cough medicine is <extra_id_0> because <extra_id_1>"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
output_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(output_text)
📚 ドキュメント
モデルの説明
- 開発者:Iker García-Ferrero, Rodrigo Agerri, Aitziber Atutxa Salazar, Elena Cabrio, Iker de la Iglesia, Alberto Lavelli, Bernardo Magnini, Benjamin Molinet, Johana Ramirez-Romero, German Rigau, Jose Maria Villa-Gonzalez, Serena Villata and Andrea Zaninello
- 連絡先:Iker García-Ferrero と Rodrigo Agerri
- ウェブサイト:https://univ-cotedazur.eu/antidote
- 資金提供:CHIST - ERA XAI 2019 call. Antidote (PCI2020 - 120717 - 2) はMCIN/AEI /10.13039/501100011033およびEuropean Union NextGenerationEU/PRTRによって資金提供されています。
- モデルタイプ:text2text - generation
- 言語:英語、スペイン語、フランス語、イタリア語
- ライセンス:apache - 2.0
- 微調整元モデル:mT5
事前学習設定
| 設定項目 |
Medical mT5 - Large (HiTZ/Medical-mT5-large) |
Medical mT5 - XL (HiTZ/Medical-mT5-xl) |
| パラメータ数 |
738M |
3B |
| シーケンス長 |
1024 |
480 |
| トークン/ステップ |
65536 |
30720 |
| エポック数 |
1 |
1 |
| 総トークン数 |
4.5B |
4.5B |
| オプティマイザ |
Adafactor |
Adafactor |
| 学習率 |
0.001 |
0.001 |
| スケジューラ |
Constant |
Constant |
| ハードウェア |
4xA100 |
4xA100 |
| 時間 (h) |
10.5 |
20.5 |
| CO₂eq (kg) |
2.9 |
5.6 |
学習データ
| 言語 |
データソース |
単語数 |
| 英語 |
ClinicalTrials |
127.4M |
| 英語 |
EMEA |
12M |
| 英語 |
PubMed |
968.4M |
| スペイン語 |
EMEA |
13.6M |
| スペイン語 |
PubMed |
8.4M |
| スペイン語 |
Medical Crawler |
918M |
| スペイン語 |
SPACC |
350K |
| スペイン語 |
UFAL |
10.5M |
| スペイン語 |
WikiMed |
5.2M |
| フランス語 |
PubMed |
1.4M |
| フランス語 |
Science Direct |
15.2M |
| フランス語 |
Wikipedia - Médecine |
5M |
| フランス語 |
EDP |
48K |
| フランス語 |
Google Patents |
654M |
| イタリア語 |
Medical Commoncrawl - IT |
67M |
| イタリア語 |
Drug instructions |
30.5M |
| イタリア語 |
Wikipedia - Medicina |
13.3M |
| イタリア語 |
E3C Corpus - IT |
11.6M |
| イタリア語 |
Medicine descriptions |
6.3M |
| イタリア語 |
Medical theses |
5.8M |
| イタリア語 |
Medical websites |
4M |
| イタリア語 |
PubMed |
2.3M |
| イタリア語 |
Supplement description |
1.3M |
| イタリア語 |
Medical notes |
975K |
| イタリア語 |
Pathologies |
157K |
| イタリア語 |
Medical test simulations |
26K |
| イタリア語 |
Clinical cases |
20K |
評価
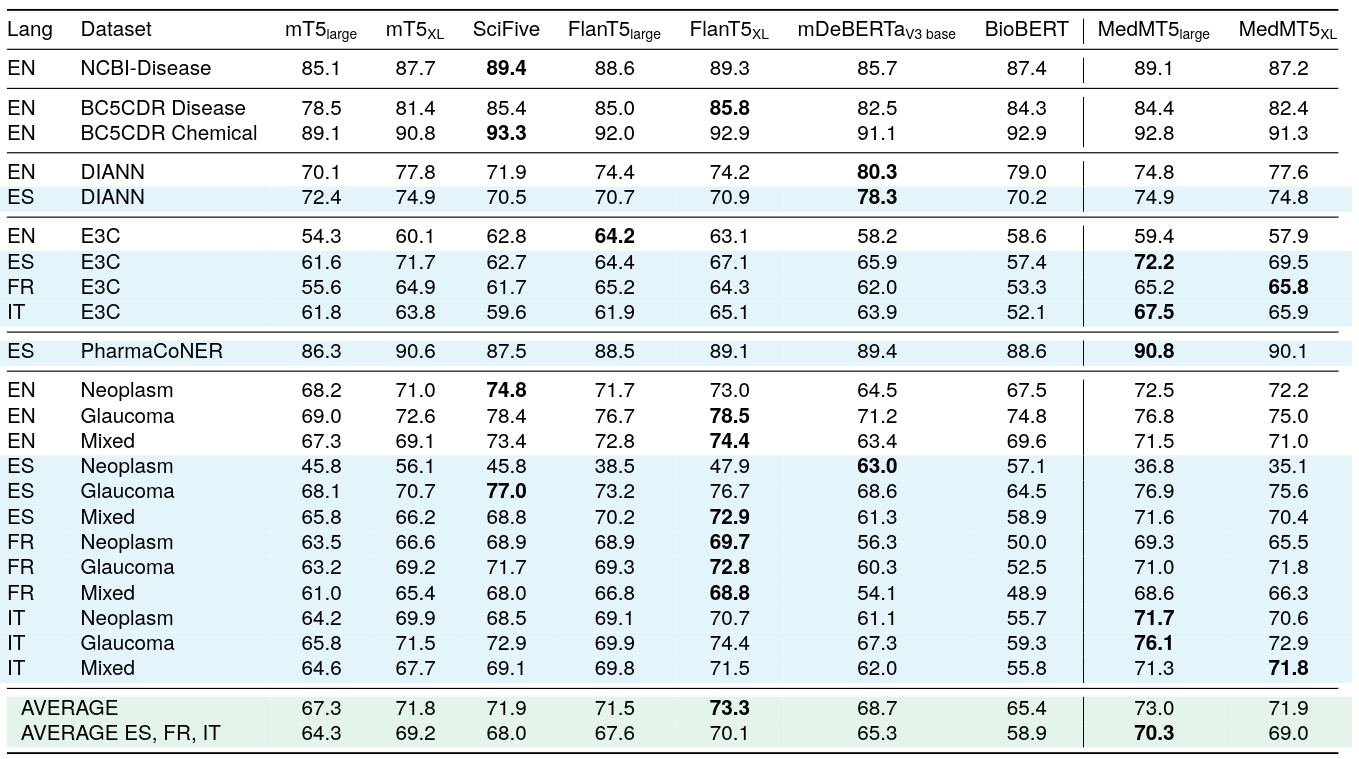
シーケンスラベリング用のMedical mT5
シーケンスラベリングの単タスク監督F1スコア
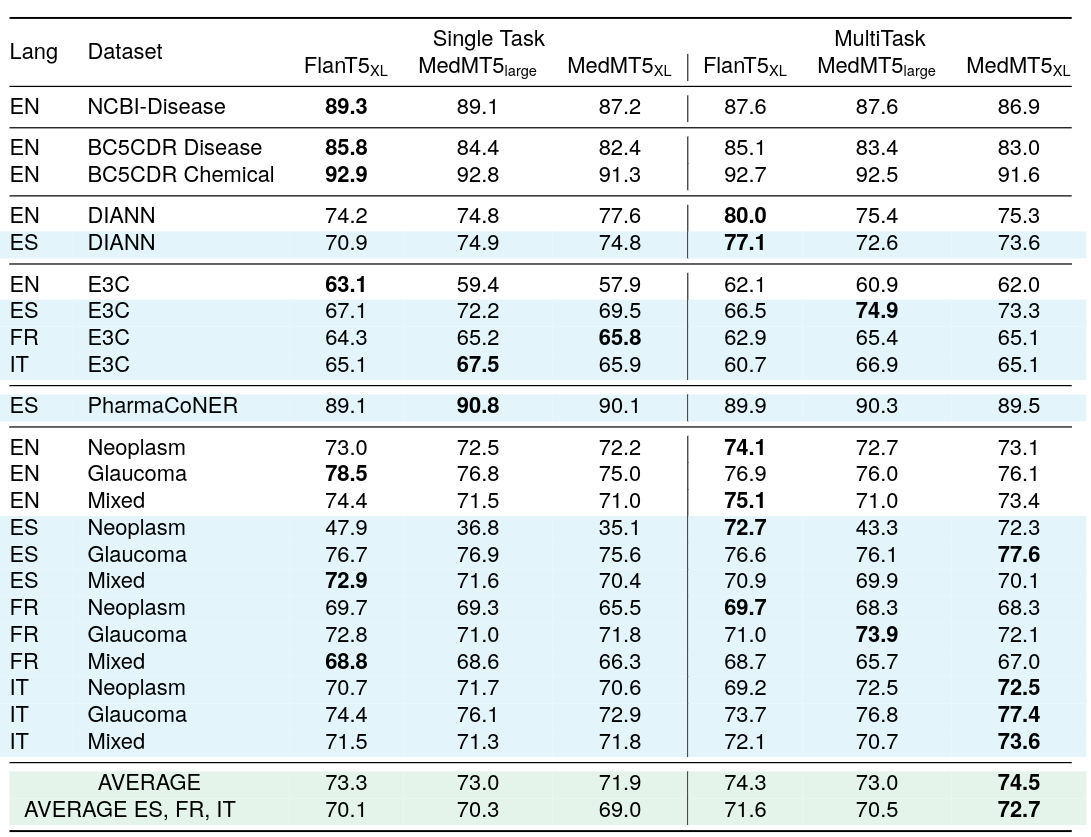
シーケンスラベリングのマルチタスク監督F1スコア
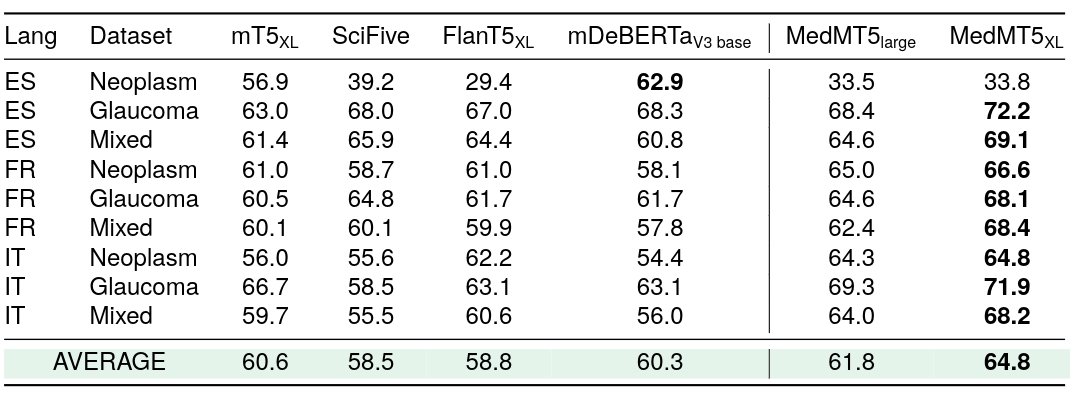
アーギュメントマイニングのゼロショットF1スコア
モデルは英語で学習され、スペイン語、フランス語、イタリア語で評価されました。
🔧 技術詳細
Medical mT5は、公開されているmT5チェックポイントを医療分野のデータで継続学習することで開発されました。T5のマスク言語モデリングタスクを使用して学習されており、独自のタスクに合わせて微調整する必要があります。
📄 ライセンス
このモデルはapache - 2.0ライセンスの下で公開されています。
引用
@misc{garcíaferrero2024medical,
title={Medical mT5: An Open-Source Multilingual Text-to-Text LLM for The Medical Domain},
author={Iker García-Ferrero and Rodrigo Agerri and Aitziber Atutxa Salazar and Elena Cabrio and Iker de la Iglesia and Alberto Lavelli and Bernardo Magnini and Benjamin Molinet and Johana Ramirez-Romero and German Rigau and Jose Maria Villa-Gonzalez and Serena Villata and Andrea Zaninello},
year={2024},
eprint={2404.07613},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応