%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型概述
模型特點
模型能力
使用案例
🚀 多功能擴散模型V1.0項目介紹
多功能擴散模型(Versatile Diffusion,VD)是首個統一的多流多模態擴散框架,是邁向通用生成式人工智能的重要一步。該模型原生支持圖像轉文本、圖像變體生成、文本轉圖像和文本變體生成等功能,還可進一步擴展到語義風格解耦、圖文雙引導生成、潛在圖像 - 文本 - 圖像編輯等應用場景。未來版本將支持更多模態,如語音、音樂、視頻和3D。
✨ 主要特性
- 首個統一的多流多模態擴散框架,邁向通用生成式人工智能。
- 原生支持圖像轉文本、圖像變體生成、文本轉圖像和文本變體生成等功能。
- 可擴展到語義風格解耦、圖文雙引導生成、潛在圖像 - 文本 - 圖像編輯等應用場景。
- 未來版本將支持更多模態,如語音、音樂、視頻和3D。
📦 安裝指南
使用Diffusers庫
要使用此模型,需確保從 "main" 安裝 transformers:
pip install git+https://github.com/huggingface/transformers
💻 使用示例
基礎用法
使用 VersatileDiffusionPipeline 進行通用任務:
#! pip install git+https://github.com/huggingface/transformers diffusers torch
from diffusers import VersatileDiffusionPipeline
import torch
import requests
from io import BytesIO
from PIL import Image
pipe = VersatileDiffusionPipeline.from_pretrained("shi-labs/versatile-diffusion", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
# prompt
prompt = "a red car"
# initial image
url = "https://huggingface.co/datasets/diffusers/images/resolve/main/benz.jpg"
response = requests.get(url)
image = Image.open(BytesIO(response.content)).convert("RGB")
# text to image
image = pipe.text_to_image(prompt).images[0]
# image variation
image = pipe.image_variation(image).images[0]
# image variation
image = pipe.dual_guided(prompt, image).images[0]
高級用法
文本轉圖像
from diffusers import VersatileDiffusionTextToImagePipeline
import torch
pipe = VersatileDiffusionTextToImagePipeline.from_pretrained("shi-labs/versatile-diffusion", torch_dtype=torch.float16)
pipe.remove_unused_weights()
pipe = pipe.to("cuda")
generator = torch.Generator(device="cuda").manual_seed(0)
image = pipe("an astronaut riding on a horse on mars", generator=generator).images[0]
image.save("./astronaut.png")
圖像變體生成
from diffusers import VersatileDiffusionImageVariationPipeline
import torch
import requests
from io import BytesIO
from PIL import Image
# download an initial image
url = "https://huggingface.co/datasets/diffusers/images/resolve/main/benz.jpg"
response = requests.get(url)
image = Image.open(BytesIO(response.content)).convert("RGB")
pipe = VersatileDiffusionImageVariationPipeline.from_pretrained("shi-labs/versatile-diffusion", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
generator = torch.Generator(device="cuda").manual_seed(0)
image = pipe(image, generator=generator).images[0]
image.save("./car_variation.png")
雙引導生成
from diffusers import VersatileDiffusionDualGuidedPipeline
import torch
import requests
from io import BytesIO
from PIL import Image
# download an initial image
url = "https://huggingface.co/datasets/diffusers/images/resolve/main/benz.jpg"
response = requests.get(url)
image = Image.open(BytesIO(response.content)).convert("RGB")
text = "a red car in the sun"
pipe = VersatileDiffusionDualGuidedPipeline.from_pretrained("shi-labs/versatile-diffusion", torch_dtype=torch.float16)
pipe.remove_unused_weights()
pipe = pipe.to("cuda")
generator = torch.Generator(device="cuda").manual_seed(0)
text_to_image_strength = 0.75
image = pipe(prompt=text, image=image, text_to_image_strength=text_to_image_strength, generator=generator).images[0]
image.save("./red_car.png")
原GitHub倉庫使用
請遵循此處的說明。
📚 詳細文檔
模型詳情
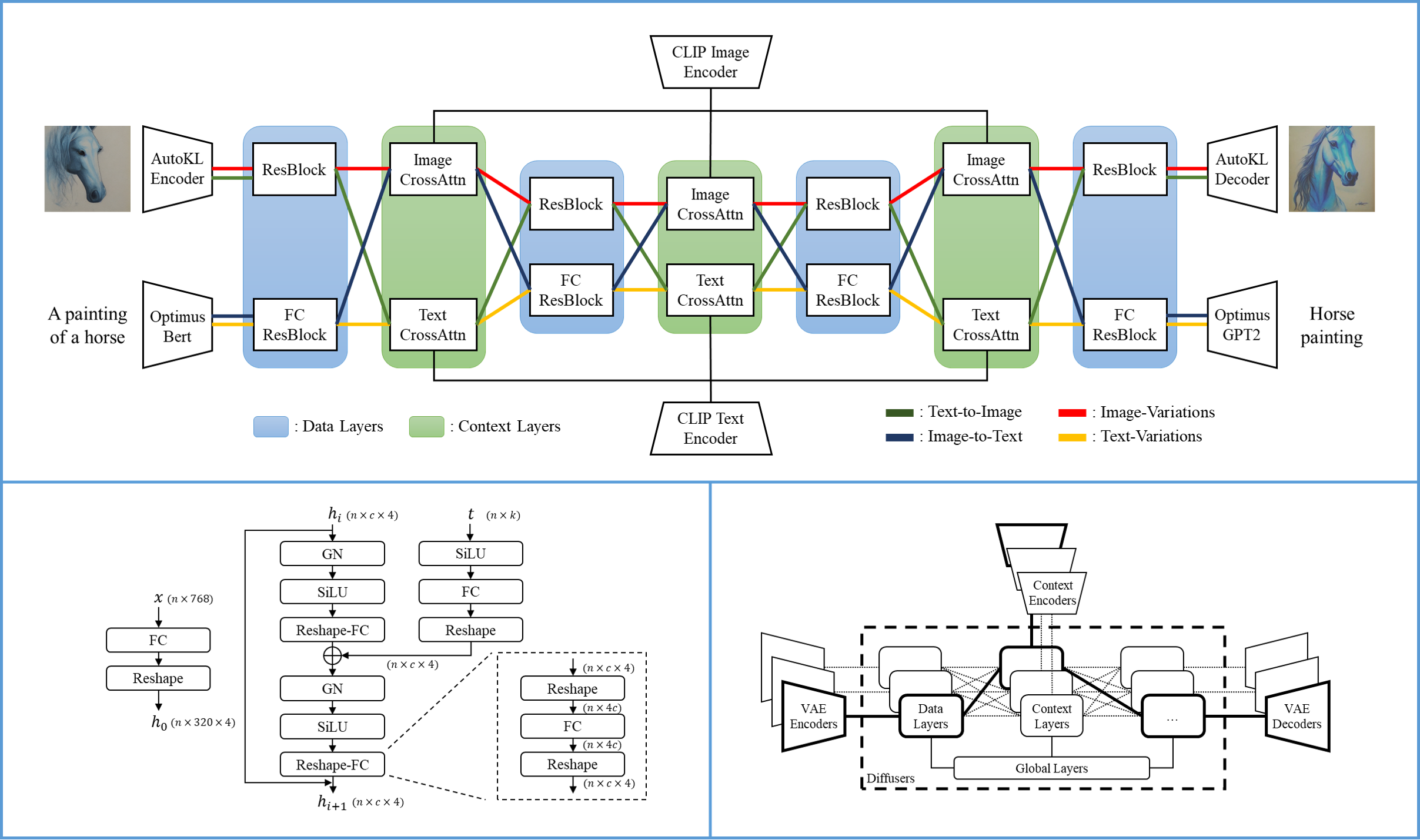
多功能擴散模型的單一流包含一個變分自編碼器(VAE)、一個擴散器和一個上下文編碼器,因此可以在一種數據類型(如圖像)和一種上下文類型(如文本)下處理一個任務(如文本轉圖像)。多功能擴散模型的多流結構如下圖所示:
| 屬性 | 詳情 |
|---|---|
| 開發者 | Xingqian Xu, Atlas Wang, Eric Zhang, Kai Wang, and Humphrey Shi |
| 模型類型 | 基於擴散的多模態生成模型 |
| 語言 | 英語 |
| 許可證 | MIT |
| 更多信息資源 | GitHub倉庫,論文 |
| 引用格式 |
@article{xu2022versatile,
title = {Versatile Diffusion: Text, Images and Variations All in One Diffusion Model},
author = {Xingqian Xu, Zhangyang Wang, Eric Zhang, Kai Wang, Humphrey Shi},
year = 2022,
url = {https://arxiv.org/abs/2211.08332},
eprint = {2211.08332},
archiveprefix = {arXiv},
primaryclass = {cs.CV}
}
🔧 技術細節
多功能擴散模型的一個單一流由VAE、擴散器和上下文編碼器組成,可處理一種數據類型和上下文類型下的一個任務。多流結構使其能夠支持多種任務和應用場景。
📄 許可證
本項目採用MIT許可證。
⚠️ 重要提示
我們希望使用此演示的用戶意識到其潛在的問題和擔憂。與之前的大型基礎模型一樣,多功能擴散模型在某些情況下可能存在問題,部分原因是訓練數據不完善以及預訓練網絡(VAE / 上下文編碼器)的範圍有限。在未來的研究階段,藉助更強大的VAE、更復雜的網絡設計和更乾淨的數據,多功能擴散模型在文本轉圖像、圖像轉文本等任務上可能會表現得更好。到目前為止,我們保留了所有功能用於研究測試,既為了展示多功能擴散框架的巨大潛力,也為了收集重要反饋以在未來改進模型。我們歡迎研究人員和用戶通過HuggingFace社區討論功能報告問題或給作者發送電子郵件。
請注意,多功能擴散模型可能會輸出強化或加劇社會偏見的內容,以及逼真的人臉、色情和暴力內容。該模型在LAION - 2B數據集上進行訓練,該數據集抓取了未經整理的在線圖像和文本,儘管我們刪除了非法內容,但仍可能包含意外異常。此演示中的多功能擴散模型僅用於研究目的。
 Safetensors Safetensors
Safetensors Safetensors