🚀 バーサタイル拡散V1.0モデルカード
私たちは、Universal Generative AI への一歩として、最初の統一型マルチフローマルチモーダル拡散フレームワークである「Versatile Diffusion (VD)」 を構築しました。Versatile Diffusionは、画像からテキスト、画像のバリエーション、テキストから画像、テキストのバリエーションをネイティブにサポートし、さらに、意味スタイルの分離、画像とテキストの二重誘導生成、潜在画像からテキストを経由した画像編集などの他のアプリケーションに拡張することができます。将来のバージョンでは、音声、音楽、ビデオ、3Dなどのより多くのモダリティをサポートする予定です。
詳細情報に関するリソース: GitHub、arXiv。
🚀 クイックスタート
このモデルについての概要を説明します。Versatile Diffusion (VD) は、Universal Generative AI を目指して開発された最初の統一型マルチフローマルチモーダル拡散フレームワークです。多様なタスクをサポートし、将来的にはさらに多くのモダリティをサポートする予定です。
✨ 主な機能
- 画像からテキスト、画像のバリエーション、テキストから画像、テキストのバリエーションをネイティブにサポート。
- 意味スタイルの分離、画像とテキストの二重誘導生成、潜在画像からテキストを経由した画像編集などのアプリケーションに拡張可能。
- 将来のバージョンでは、音声、音楽、ビデオ、3Dなどのモダリティをサポート予定。
📚 ドキュメント
モデルの詳細
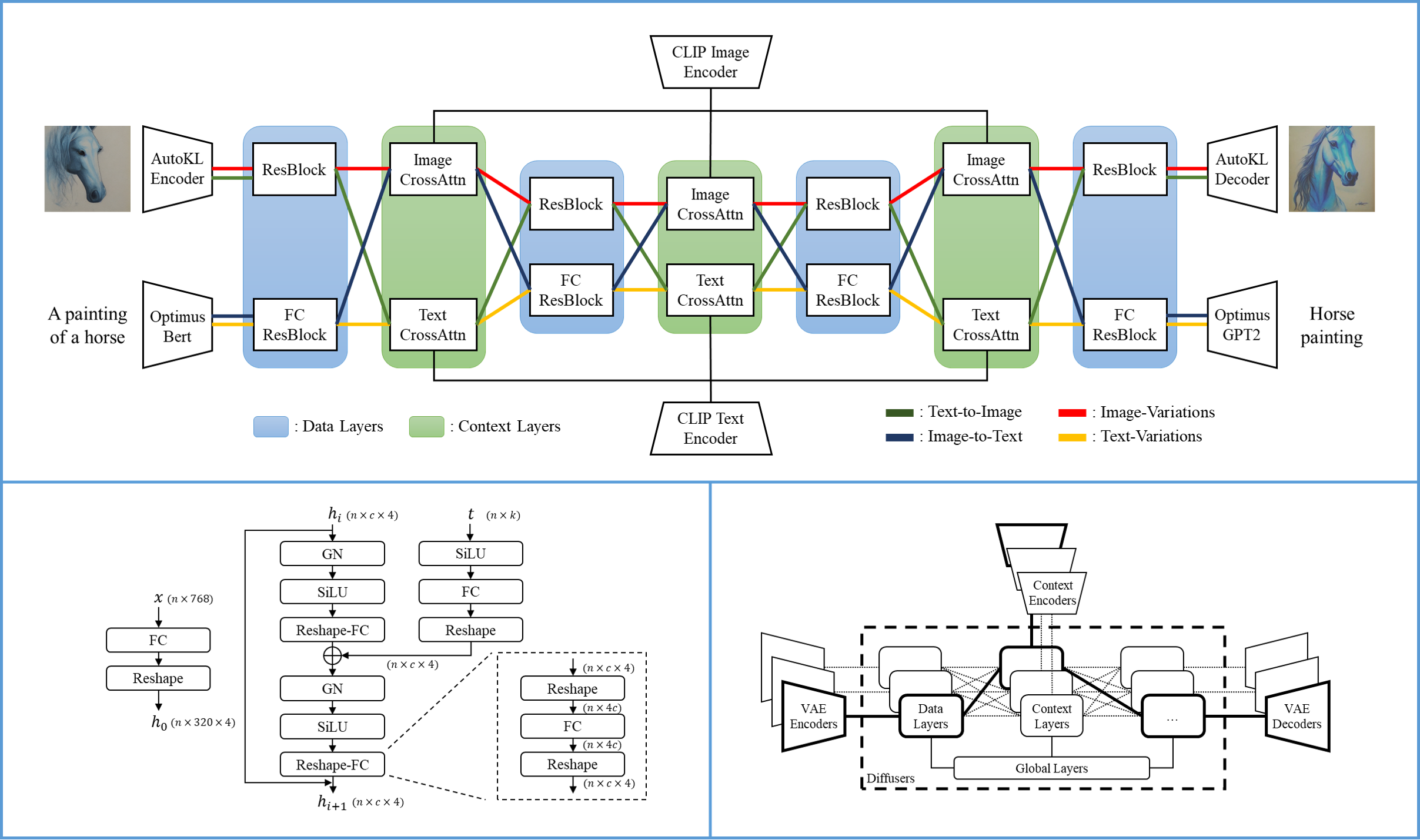
Versatile Diffusionの単一フローには、VAE、拡散器、コンテキストエンコーダが含まれており、1つのデータタイプ(例:画像)と1つのコンテキストタイプ(例:テキスト)の下で1つのタスク(例:テキストから画像)を処理します。Versatile Diffusionのマルチフロー構造は、次の図に示されています。
| 属性 |
详情 |
| 開発者 |
Xingqian Xu、Atlas Wang、Eric Zhang、Kai Wang、Humphrey Shi |
| モデルタイプ |
拡散ベースのマルチモーダル生成モデル |
| 言語 |
英語 |
| ライセンス |
MIT |
| 詳細情報のリソース |
GitHubリポジトリ、論文 |
| 引用形式 |
|
@article{xu2022versatile,
title = {Versatile Diffusion: Text, Images and Variations All in One Diffusion Model},
author = {Xingqian Xu, Zhangyang Wang, Eric Zhang, Kai Wang, Humphrey Shi},
year = 2022,
url = {https://arxiv.org/abs/2211.08332},
eprint = {2211.08332},
archiveprefix = {arXiv},
primaryclass = {cs.CV}
}
使用方法
このモデルは、🧨Diffusersライブラリ と SHI-Labs Versatile Diffusionコードベース の両方で使用できます。
🧨 Diffusers
Diffusersを使用すると、統一された、よりメモリ効率の良いタスク固有のパイプラインを使用できます。
⚠️ 重要提示
このモデルを使用するには、transformers を "main" からインストールする必要があります。
pip install git+https://github.com/huggingface/transformers
VersatileDiffusionPipeline
すべてのタスクでVersatile Diffusionを使用するには、VersatileDiffusionPipeline を使用することをお勧めします。
from diffusers import VersatileDiffusionPipeline
import torch
import requests
from io import BytesIO
from PIL import Image
pipe = VersatileDiffusionPipeline.from_pretrained("shi-labs/versatile-diffusion", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a red car"
url = "https://huggingface.co/datasets/diffusers/images/resolve/main/benz.jpg"
response = requests.get(url)
image = Image.open(BytesIO(response.content)).convert("RGB")
image = pipe.text_to_image(prompt).images[0]
image = pipe.image_variation(image).images[0]
image = pipe.dual_guided(prompt, image).images[0]
タスク固有のパイプライン
タスク固有のパイプラインは、必要な重みのみをGPUにロードします。すべてのタスク固有のパイプラインは、こちら で見つけることができます。
使用方法は次のとおりです。
テキストから画像
from diffusers import VersatileDiffusionTextToImagePipeline
import torch
pipe = VersatileDiffusionTextToImagePipeline.from_pretrained("shi-labs/versatile-diffusion", torch_dtype=torch.float16)
pipe.remove_unused_weights()
pipe = pipe.to("cuda")
generator = torch.Generator(device="cuda").manual_seed(0)
image = pipe("an astronaut riding on a horse on mars", generator=generator).images[0]
image.save("./astronaut.png")
画像のバリエーション
from diffusers import VersatileDiffusionImageVariationPipeline
import torch
import requests
from io import BytesIO
from PIL import Image
url = "https://huggingface.co/datasets/diffusers/images/resolve/main/benz.jpg"
response = requests.get(url)
image = Image.open(BytesIO(response.content)).convert("RGB")
pipe = VersatileDiffusionImageVariationPipeline.from_pretrained("shi-labs/versatile-diffusion", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
generator = torch.Generator(device="cuda").manual_seed(0)
image = pipe(image, generator=generator).images[0]
image.save("./car_variation.png")
二重誘導生成
from diffusers import VersatileDiffusionDualGuidedPipeline
import torch
import requests
from io import BytesIO
from PIL import Image
url = "https://huggingface.co/datasets/diffusers/images/resolve/main/benz.jpg"
response = requests.get(url)
image = Image.open(BytesIO(response.content)).convert("RGB")
text = "a red car in the sun"
pipe = VersatileDiffusionDualGuidedPipeline.from_pretrained("shi-labs/versatile-diffusion", torch_dtype=torch.float16)
pipe.remove_unused_weights()
pipe = pipe.to("cuda")
generator = torch.Generator(device="cuda").manual_seed(0)
text_to_image_strength = 0.75
image = pipe(prompt=text, image=image, text_to_image_strength=text_to_image_strength, generator=generator).images[0]
image.save("./red_car.png")
元のGitHubリポジトリ
こちら の指示に従ってください。
注意事項、バイアス、およびコンテンツの承認
私たちは、このデモのユーザーに、その潜在的な問題と懸念事項についての認識を高めたいと考えています。以前の大規模な基礎モデルと同様に、Versatile Diffusionは、不完全なトレーニングデータと限られた範囲の事前学習ネットワーク(VAE / コンテキストエンコーダ)のため、場合によっては問題が生じる可能性があります。将来の研究段階では、より強力なVAE、より洗練されたネットワーク設計、およびよりクリーンなデータの助けを借りて、VDはテキストから画像、画像からテキストなどのタスクでより良い結果を得る可能性があります。これまでのところ、VDフレームワークの大きな潜在力を示し、将来的にモデルを改善するための重要なフィードバックを収集するために、すべての機能を研究テスト用に利用可能な状態に保っています。研究者やユーザーからの問題の報告を、HuggingFaceコミュニティのディスカッション機能または著者へのメールで歓迎しています。
VDは、社会的なバイアスを強化または悪化させるコンテンツ、ならびにリアルな顔、ポルノグラフィー、および暴力を含むコンテンツを出力する可能性があることに注意してください。VDは、非選別のオンライン画像とテキストを収集したLAION - 2Bデータセットでトレーニングされており、違法コンテンツを削除した後でも意図しない例外が含まれる可能性があります。このデモのVDは、研究目的のみを意図しています。
📄 ライセンス
このモデルはMITライセンスの下で提供されています。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors Transformers 複数言語対応
Transformers 複数言語対応