%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
TW
Stockmarket Pattern Detection Yolov8
基於YOLOv8的目標檢測模型,專為即時檢測股市交易圖表中的關鍵模式而設計

下載量 6,746
發布時間 : 8/10/2023
模型概述
該模型能夠從屏幕捕獲的股市交易數據中即時檢測各類圖表模式,包括頭肩底、頭肩頂等6種常見形態,為交易決策提供自動化分析支持
模型特點
即時模式檢測
能夠即時處理股市屏幕截圖,快速識別關鍵圖表模式
多模式識別
支持檢測6種常見股市圖表模式,包括頭肩形態、趨勢線等
自動化交易支持
檢測結果可直接用於自動化交易策略或生成交易警報
模型能力
股市圖表模式檢測
即時屏幕截圖分析
多類別目標識別
自動化交易決策支持
使用案例
金融交易
即時交易決策
在交易過程中自動識別圖表形態,為買賣決策提供依據
檢測準確率mAP@0.5達到61.35%
交易策略優化
通過歷史數據分析特定模式的成功率,優化交易策略
金融教育
圖表模式教學
作為教學工具展示各類圖表模式的識別方法
🚀 YOLOv8s股票市場即時圖案檢測模型
該模型基於YOLO(You Only Look Once)框架,能夠從屏幕捕獲的股票市場交易數據中即時檢測各種圖表模式。它通過自動分析圖表模式,為交易者和投資者提供及時的見解,輔助他們做出明智的決策。該模型在多樣化的數據集上進行了微調,在即時交易場景中能夠高精度地檢測和分類股票市場模式。
🚀 快速開始
要開始使用YOLOv8s股票市場即時圖案檢測模型,你需要安裝必要的庫:
pip install mss==10.0.0 opencv-python==4.11.0.86 numpy ultralytics==8.3.94 openpyxl==3.1.5
💻 使用示例
基礎用法
import os
import mss # type: ignore
import cv2
import numpy as np
import time
import glob
from ultralytics import YOLO
from openpyxl import Workbook
# Get the user's home directory
home_dir = os.path.expanduser("~")
# Define dynamic paths
save_path = os.path.join(home_dir, "yolo_detection")
screenshots_path = os.path.join(save_path, "screenshots")
detect_path = os.path.join(save_path, "runs", "detect")
# Ensure necessary directories exist
os.makedirs(screenshots_path, exist_ok=True)
os.makedirs(detect_path, exist_ok=True)
# Define pattern classes
classes = ['Head and shoulders bottom', 'Head and shoulders top', 'M_Head', 'StockLine', 'Triangle', 'W_Bottom']
# Load YOLOv8 model
model_path = "model.pt"
if not os.path.exists(model_path):
raise FileNotFoundError(f"Model file not found: {model_path}")
model = YOLO(model_path)
# Define screen capture region
monitor = {"top": 0, "left": 683, "width": 683, "height": 768}
# Create an Excel file
excel_file = os.path.join(save_path, "classification_results.xlsx")
wb = Workbook()
ws = wb.active
ws.append(["Timestamp", "Predicted Image Path", "Label"]) # Headers
# Initialize video writer
video_path = os.path.join(save_path, "annotated_video.mp4")
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
fps = 0.5 # Adjust frames per second as needed
video_writer = None
with mss.mss() as sct:
start_time = time.time()
last_capture_time = start_time # Track the last capture time
frame_count = 0
while True:
# Continuously capture the screen
sct_img = sct.grab(monitor)
img = np.array(sct_img)
img = cv2.cvtColor(img, cv2.COLOR_BGRA2BGR)
# Check if 60 seconds have passed since last YOLO prediction
current_time = time.time()
if current_time - last_capture_time >= 60:
# Take screenshot for YOLO prediction
timestamp = time.strftime("%Y-%m-%d %H:%M:%S")
image_name = f"predicted_images_{timestamp}_{frame_count}.png"
image_path = os.path.join(screenshots_path, image_name)
cv2.imwrite(image_path, img)
# Run YOLO model and get save directory
results = model(image_path, save=True)
predict_path = results[0].save_dir if results else None
# Find the latest annotated image inside predict_path
if predict_path and os.path.exists(predict_path):
annotated_images = sorted(glob.glob(os.path.join(predict_path, "*.jpg")), key=os.path.getmtime, reverse=True)
final_image_path = annotated_images[0] if annotated_images else image_path
else:
final_image_path = image_path # Fallback to original image
# Determine predicted label
if results and results[0].boxes:
class_indices = results[0].boxes.cls.tolist()
predicted_label = classes[int(class_indices[0])]
else:
predicted_label = "No pattern detected"
# Insert data into Excel (store path instead of image)
ws.append([timestamp, final_image_path, predicted_label])
# Read the image for video processing
annotated_img = cv2.imread(final_image_path)
if annotated_img is not None:
# Add timestamp and label text to the image
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(annotated_img, f"{timestamp}", (10, 30), font, 0.7, (0, 255, 0), 2, cv2.LINE_AA)
cv2.putText(annotated_img, f"{predicted_label}", (10, 60), font, 0.7, (0, 255, 255), 2, cv2.LINE_AA)
# Initialize video writer if not already initialized
if video_writer is None:
height, width, layers = annotated_img.shape
video_writer = cv2.VideoWriter(video_path, fourcc, fps, (width, height))
video_writer.write(annotated_img)
print(f"Frame {frame_count}: {final_image_path} -> {predicted_label}")
frame_count += 1
# Update the last capture time
last_capture_time = current_time
# Save the Excel file periodically
wb.save(excel_file)
# If you want to continuously display the screen, you can add this line
cv2.imshow("Screen Capture", img)
# Break if 'q' is pressed (you can exit the loop this way)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video writer
if video_writer is not None:
video_writer.release()
print(f"Video saved at {video_path}")
# Remove all files in screenshots directory
for file in os.scandir(screenshots_path):
os.remove(file.path)
os.rmdir(screenshots_path)
print(f"Results saved to {excel_file}")
# Close OpenCV window
cv2.destroyAllWindows()
📚 詳細文檔
模型詳情
模型描述
YOLOv8s股票市場圖案檢測模型能夠即時檢測股票市場屏幕截圖中的關鍵圖表模式。由於股票市場變化迅速,該模型的功能使用戶能夠及時獲取信息,從而快速準確地做出明智決策。
該模型旨在處理股票市場交易圖表的屏幕截圖,能夠檢測諸如“頭肩底”、“頭肩頂”、“M頭”、“股票線”、“三角形”和“W底”等模式。交易者可以優化他們的策略,自動做出交易決策,並即時響應市場趨勢。
若要將此模型集成到即時交易系統或進行定製諮詢,請通過info@foduu.com與我們聯繫。
| 屬性 | 詳情 |
|---|---|
| 開發者 | FODUU AI |
| 模型類型 | 目標檢測 |
| 任務 | 從屏幕截圖中進行股票市場圖案檢測 |
支持的標籤
['Head and shoulders bottom', 'Head and shoulders top', 'M_Head', 'StockLine', 'Triangle', 'W_Bottom']
用途
- 直接使用:該模型可用於對屏幕捕獲的股票市場圖表進行即時圖案檢測。它可以記錄檢測到的圖案,對檢測到的圖像進行註釋,將結果保存到Excel文件中,並生成一段時間內檢測到的圖案的視頻。
- 下游使用:該模型的即時功能可用於自動化交易策略,為特定圖案生成警報,並提高整體交易表現。
- 訓練數據:該股票市場模型在一個自定義數據集上進行訓練,該數據集包含9000張訓練圖像和800張驗證圖像。
- 適用範圍外的使用:該模型不適用於與股票市場圖案檢測無關的目標檢測任務或場景。
偏差、風險和侷限性
- 性能可能會受到圖表樣式、屏幕分辨率和市場條件變化的影響。
- 快速的市場波動和交易數據中的噪聲可能會影響準確性。
- 訓練數據中未充分體現的特定市場模式可能會給檢測帶來挑戰。
建議
用戶應瞭解該模型的侷限性和潛在偏差。在將模型用於實際交易決策之前,建議使用歷史數據和即時市場條件進行測試和驗證。
📄 許可證
文檔中未提及相關許可證信息。
📞 模型聯繫信息
如有諮詢和貢獻需求,請通過info@foduu.com與我們聯繫。
引用信息
@ModelCard{
author = {Nehul Agrawal,
Pranjal Singh Thakur, Priyal Mehta and Arjun Singh},
title = {YOLOv8s Stock Market Pattern Detection from Live Screen Capture},
year = {2023}
}
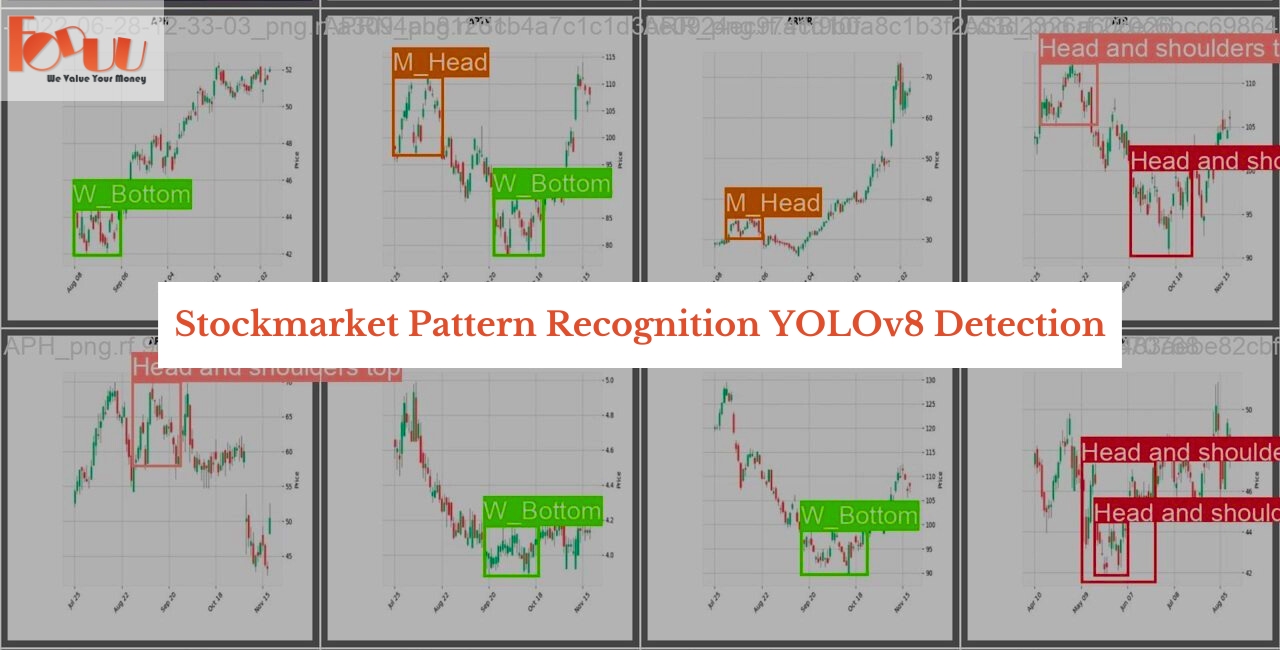
Table Transformer Detection
MIT
基於DETR架構的表格檢測模型,專門用於從非結構化文檔中提取表格
目標檢測 Transformers
Transformers
T
microsoft
2.6M
349
Grounding Dino Base
Apache-2.0
Grounding DINO是一個開放集目標檢測模型,通過結合DINO檢測器與文本編碼器實現零樣本目標檢測能力。
目標檢測 Transformers
G
IDEA-Research
1.1M
87
Grounding Dino Tiny
Apache-2.0
Grounding DINO是一個結合DINO檢測器與接地預訓練的開放集目標檢測模型,能夠實現零樣本目標檢測。
目標檢測 Transformers
G
IDEA-Research
771.67k
74
Detr Resnet 50
Apache-2.0
DETR是一個基於Transformer架構的端到端目標檢測模型,使用ResNet-50作為骨幹網絡,在COCO數據集上訓練。
目標檢測 Transformers
D
facebook
505.27k
857
Detr Resnet 101
Apache-2.0
DETR是一個使用Transformer架構的端到端目標檢測模型,採用ResNet-101作為骨幹網絡,在COCO數據集上訓練。
目標檢測 Transformers
D
facebook
262.94k
119
Detr Doc Table Detection
Apache-2.0
基於DETR架構的文檔表格檢測模型,用於檢測文檔中的有邊框和無邊框表格
目標檢測 Transformers
D
TahaDouaji
233.45k
59
Yolos Small
Apache-2.0
基於視覺Transformer(ViT)的目標檢測模型,使用DETR損失函數訓練,在COCO數據集上表現優異。
目標檢測 Transformers
Y
hustvl
154.46k
63
Yolos Tiny
Apache-2.0
基於COCO 2017目標檢測數據集微調的YOLOS模型,使用視覺Transformer架構實現高效目標檢測。
目標檢測 Transformers
Y
hustvl
144.58k
266
Rtdetr R50vd Coco O365
Apache-2.0
RT-DETR是首個即時端到端目標檢測器,通過高效混合編碼器和不確定性最小化查詢選擇機制,在COCO數據集上達到53.1% AP,108 FPS的性能。
目標檢測 Transformers 英語
R
PekingU
111.17k
11
Rtdetr R101vd Coco O365
Apache-2.0
首個即時端到端目標檢測器,基於Transformer架構,消除非極大值抑制需求,在速度與精度上超越YOLO系列
目標檢測 Transformers 英語
R
PekingU
106.81k
7
精選推薦AI模型
Llama 3 Typhoon V1.5x 8b Instruct
專為泰語設計的80億參數指令模型,性能媲美GPT-3.5-turbo,優化了應用場景、檢索增強生成、受限生成和推理任務
大型語言模型 Transformers 支持多種語言
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-Tiny是一個基於SODA數據集訓練的超小型對話模型,專為邊緣設備推理設計,體積僅為Cosmo-3B模型的2%左右。
對話系統 Transformers 英語
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
基於RoBERTa架構的中文抽取式問答模型,適用於從給定文本中提取答案的任務。
問答系統 中文
R
uer
2,694
98