%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型概述
模型特點
模型能力
使用案例
🚀 RT-DETR 模型卡片
RT-DETR 是首個即時端到端目標檢測器,解決了現有目標檢測框架在速度和準確性方面的困境。它通過高效混合編碼器和不確定性最小查詢選擇等方法,在保持準確性的同時提高速度,或在保持速度的同時提高準確性。
🚀 快速開始
使用以下代碼開始使用該模型:
import torch
import requests
from PIL import Image
from transformers import RTDetrForObjectDetection, RTDetrImageProcessor
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
image_processor = RTDetrImageProcessor.from_pretrained("PekingU/rtdetr_r18vd_coco_o365")
model = RTDetrForObjectDetection.from_pretrained("PekingU/rtdetr_r18vd_coco_o365")
inputs = image_processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
results = image_processor.post_process_object_detection(outputs, target_sizes=torch.tensor([image.size[::-1]]), threshold=0.3)
for result in results:
for score, label_id, box in zip(result["scores"], result["labels"], result["boxes"]):
score, label = score.item(), label_id.item()
box = [round(i, 2) for i in box.tolist()]
print(f"{model.config.id2label[label]}: {score:.2f} {box}")
這段代碼的輸出應該如下:
sofa: 0.97 [0.14, 0.38, 640.13, 476.21]
cat: 0.96 [343.38, 24.28, 640.14, 371.5]
cat: 0.96 [13.23, 54.18, 318.98, 472.22]
remote: 0.95 [40.11, 73.44, 175.96, 118.48]
✨ 主要特性
- 即時端到端檢測:RT-DETR 是首個即時端到端目標檢測器,解決了現有目標檢測框架在速度和準確性方面的困境。
- 高效混合編碼器:通過解耦尺度內交互和跨尺度融合,快速處理多尺度特徵,提高速度。
- 不確定性最小查詢選擇:為解碼器提供高質量的初始查詢,提高準確性。
- 靈活的速度調整:通過調整解碼器層數,支持靈活的速度調整,適應各種場景,無需重新訓練。
📦 安裝指南
文檔未提及安裝步驟,故跳過此章節。
💻 使用示例
基礎用法
import torch
import requests
from PIL import Image
from transformers import RTDetrForObjectDetection, RTDetrImageProcessor
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
image_processor = RTDetrImageProcessor.from_pretrained("PekingU/rtdetr_r18vd_coco_o365")
model = RTDetrForObjectDetection.from_pretrained("PekingU/rtdetr_r18vd_coco_o365")
inputs = image_processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
results = image_processor.post_process_object_detection(outputs, target_sizes=torch.tensor([image.size[::-1]]), threshold=0.3)
for result in results:
for score, label_id, box in zip(result["scores"], result["labels"], result["boxes"]):
score, label = score.item(), label_id.item()
box = [round(i, 2) for i in box.tolist()]
print(f"{model.config.id2label[label]}: {score:.2f} {box}")
高級用法
文檔未提及高級用法代碼示例,故跳過此部分。
📚 詳細文檔
模型詳情

YOLO 系列由於在速度和準確性之間進行了合理的權衡,已成為即時目標檢測最流行的框架。然而,我們觀察到 YOLO 的速度和準確性受到 NMS 的負面影響。最近,基於端到端 Transformer 的檢測器(DETR)提供了一種消除 NMS 的替代方案。然而,高計算成本限制了它們的實用性,並阻礙了它們充分發揮排除 NMS 的優勢。在本文中,我們提出了即時檢測 Transformer(RT-DETR),據我們所知,這是第一個解決上述困境的即時端到端目標檢測器。我們借鑑先進的 DETR,分兩步構建 RT-DETR:首先,我們專注於在提高速度的同時保持準確性,然後在保持速度的同時提高準確性。具體來說,我們設計了一種高效的混合編碼器,通過解耦尺度內交互和跨尺度融合來快速處理多尺度特徵,以提高速度。然後,我們提出了不確定性最小查詢選擇,為解碼器提供高質量的初始查詢,從而提高準確性。此外,RT-DETR 支持通過調整解碼器層數來靈活調整速度,以適應各種場景,無需重新訓練。我們的 RT-DETR-R50 / R101 在 COCO 上達到了 53.1% / 54.3% 的 AP,在 T4 GPU 上達到了 108 / 74 FPS,在速度和準確性上都優於之前先進的 YOLO。我們還開發了縮放版的 RT-DETR,優於較輕量級的 YOLO 檢測器(S 和 M 模型)。此外,RT-DETR-R50 在準確性上比 DINO-R50 高 2.2% 的 AP,在 FPS 上約高 21 倍。在使用 Objects365 進行預訓練後,RT-DETR-R50 / R101 達到了 55.3% / 56.2% 的 AP。項目頁面:https URL。
模型來源
- HF 文檔:RT-DETR
- 代碼倉庫:https://github.com/lyuwenyu/RT-DETR
- 論文:https://arxiv.org/abs/2304.08069
- 演示:RT-DETR 跟蹤
訓練詳情
訓練數據
RTDETR 模型在 COCO 2017 目標檢測 數據集上進行訓練,該數據集分別包含 118k/5k 張帶註釋的圖像用於訓練/驗證。
訓練過程
我們在 COCO 和 Objects365 數據集上進行實驗,其中 RT-DETR 在 COCO train2017 上進行訓練,並在 COCO val2017 數據集上進行驗證。我們報告了標準的 COCO 指標,包括 AP(在從 0.50 到 0.95 的均勻採樣 IoU 閾值上平均,步長為 0.05)、AP50、AP75,以及不同尺度下的 AP:AP-s、AP-m、AP-l。
預處理
圖像被調整為 640x640 像素,並使用 image_mean=[0.485, 0.456, 0.406] 和 image_std=[0.229, 0.224, 0.225] 進行重新縮放。
訓練超參數

評估
| 模型 | 訓練輪數 | 參數數量(M) | GFLOPs | FPS_bs=1 | AP (驗證集) | AP50 (驗證集) | AP75 (驗證集) | AP-s (驗證集) | AP-m (驗證集) | AP-l (驗證集) |
|---|---|---|---|---|---|---|---|---|---|---|
| RT-DETR-R18 | 72 | 20 | 60.7 | 217 | 46.5 | 63.8 | 50.4 | 28.4 | 49.8 | 63.0 |
| RT-DETR-R34 | 72 | 31 | 91.0 | 172 | 48.5 | 66.2 | 52.3 | 30.2 | 51.9 | 66.2 |
| RT-DETR R50 | 72 | 42 | 136 | 108 | 53.1 | 71.3 | 57.7 | 34.8 | 58.0 | 70.0 |
| RT-DETR R101 | 72 | 76 | 259 | 74 | 54.3 | 72.7 | 58.6 | 36.0 | 58.8 | 72.1 |
| RT-DETR-R18 (Objects 365 預訓練) | 60 | 20 | 61 | 217 | 49.2 | 66.6 | 53.5 | 33.2 | 52.3 | 64.8 |
| RT-DETR-R50 (Objects 365 預訓練) | 24 | 42 | 136 | 108 | 55.3 | 73.4 | 60.1 | 37.9 | 59.9 | 71.8 |
| RT-DETR-R101 (Objects 365 預訓練) | 24 | 76 | 259 | 74 | 56.2 | 74.6 | 61.3 | 38.3 | 60.5 | 73.5 |
模型架構和目標
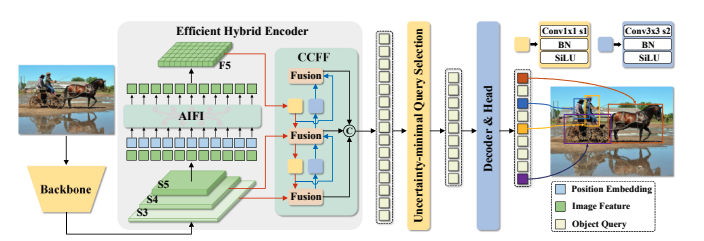
RT-DETR 概述。我們將骨幹網絡最後三個階段的特徵輸入到編碼器中。高效的混合編碼器通過基於注意力的尺度內特徵交互(AIFI)和基於 CNN 的跨尺度特徵融合(CCFF)將多尺度特徵轉換為圖像特徵序列。然後,不確定性最小查詢選擇選擇固定數量的編碼器特徵作為解碼器的初始目標查詢。最後,帶有輔助預測頭的解碼器迭代優化目標查詢,以生成類別和邊界框。
引用
BibTeX:
@misc{lv2023detrs,
title={DETRs Beat YOLOs on Real-time Object Detection},
author={Yian Zhao and Wenyu Lv and Shangliang Xu and Jinman Wei and Guanzhong Wang and Qingqing Dang and Yi Liu and Jie Chen},
year={2023},
eprint={2304.08069},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
模型卡片作者
🔧 技術細節
文檔未提及具體技術實現細節(>50 字),故跳過此章節。
📄 許可證
本模型使用的許可證為 Apache-2.0。