🚀 InternViT-300M-448px-V2_5
InternViT-300M-448px-V2_5 是基於 InternViT-300M-448px 構建的增強版本,採用ViT增量學習與NTP損失,提升了視覺編碼器提取特徵的能力,尤其在多語言OCR數據和數學圖表等領域表現出色。
📂 GitHub 📜 InternVL 1.0 📜 InternVL 1.5 📜 Mini-InternVL 📜 InternVL 2.5
🆕 Blog 🗨️ Chat Demo 🤗 HF Demo 🚀 Quick Start 📖 Documents
✨ 主要特性
我們很高興地宣佈 InternViT-300M-448px-V2_5 的發佈,它是在 InternViT-300M-448px 的基礎上進行的重大改進。通過採用具有NTP損失的 ViT增量學習(階段1.5),視覺編碼器提取視覺特徵的能力得到了提升,使其能夠捕捉更全面的信息。這種改進在大規模網絡數據集(如LAION - 5B)中代表性不足的領域尤為明顯,包括多語言OCR數據和數學圖表等。

📚 詳細文檔
InternViT 2.5 系列
下表概述了InternViT 2.5系列的模型:
| 模型名稱 |
HF鏈接 |
| InternViT-300M-448px-V2_5 |
🤗 link |
| InternViT-6B-448px-V2_5 |
🤗 link |
模型架構
如下圖所示,InternVL 2.5保留了與前代版本InternVL 1.5和2.0相同的模型架構,遵循 “ViT - MLP - LLM” 範式。在這個新版本中,我們使用隨機初始化的MLP投影器,將新的增量預訓練的InternViT與各種預訓練的LLM(包括InternLM 2.5和Qwen 2.5)集成在一起。

與之前的版本一樣,我們應用了像素重排操作,將視覺標記的數量減少到原來的四分之一。此外,我們採用了與InternVL 1.5類似的動態分辨率策略,將圖像分割成448×448像素的圖塊。從InternVL 2.0開始,關鍵的區別在於我們還增加了對多圖像和視頻數據的支持。
訓練策略
多模態數據的動態高分辨率
在InternVL 2.0和2.5中,我們擴展了動態高分辨率訓練方法,增強了其處理多圖像和視頻數據集的能力。

- 對於單圖像數據集,將總圖塊數
n_max 分配給單個圖像以實現最大分辨率。視覺標記用 <img> 和 </img> 標籤括起來。
- 對於多圖像數據集,將總圖塊數
n_max 分配到樣本中的所有圖像上。每個圖像用 Image - 1 等輔助標籤標記,並使用 <img> 和 </img> 標籤括起來。
- 對於視頻,每個幀被調整為448×448。幀用
Frame - 1 等標籤標記,並使用 <img> 和 </img> 標籤括起來,與圖像類似。
單模型訓練流程
InternVL 2.5中單個模型的訓練流程分為三個階段,旨在增強模型的視覺感知和多模態能力。

- 階段1:MLP預熱:在這個階段,僅訓練MLP投影器,而視覺編碼器和語言模型保持凍結。應用動態高分辨率訓練策略以獲得更好的性能,儘管成本有所增加。此階段確保了強大的跨模態對齊,併為模型的穩定多模態訓練做好準備。
- 階段1.5:ViT增量學習(可選):此階段允許使用與階段1相同的數據對視覺編碼器和MLP投影器進行增量訓練。它增強了編碼器處理多語言OCR和數學圖表等罕見領域的能力。一旦訓練完成,編碼器可以在不同的LLM之間重複使用,而無需重新訓練,因此除非引入新的領域,否則此階段是可選的。
- 階段2:全模型指令調優:在高質量的多模態指令數據集上訓練整個模型。實施嚴格的數據質量控制,以防止LLM性能下降,因為嘈雜的數據可能會導致輸出重複或錯誤等問題。此階段完成後,訓練過程結束。
視覺能力評估
我們對視覺編碼器在各個領域和任務中的性能進行了全面評估。評估分為兩個關鍵類別:(1)圖像分類,代表全局視圖語義質量;(2)語義分割,捕捉局部視圖語義質量。這種方法使我們能夠評估InternViT在其連續版本更新中的表示質量。更多詳細信息請參考我們的技術報告。
圖像分類
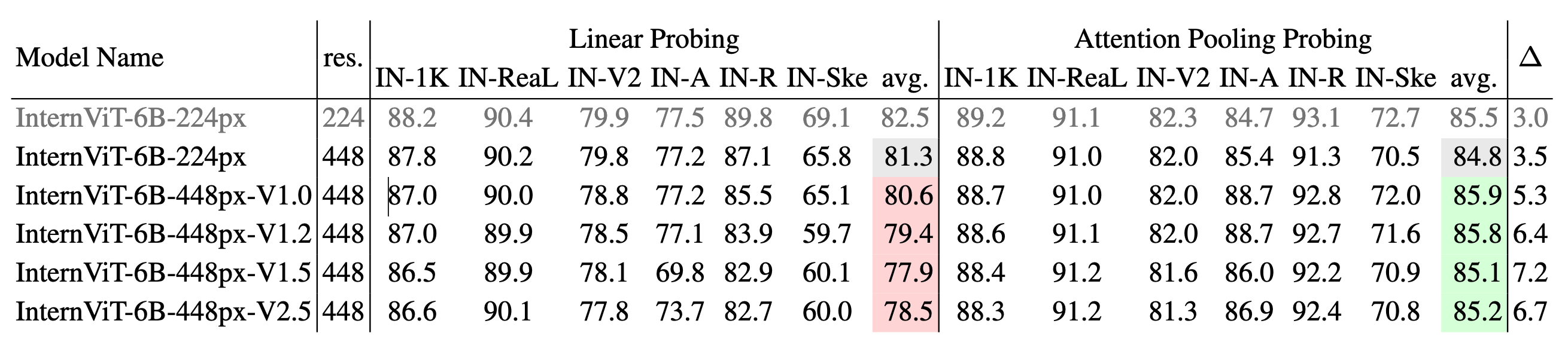
不同版本InternViT的圖像分類性能:我們使用IN - 1K進行訓練,並在IN - 1K驗證集以及多個ImageNet變體(包括IN - ReaL、IN - V2、IN - A、IN - R和IN - Sketch)上進行評估。報告了線性探測和注意力池化探測方法的結果,並給出了每種方法的平均準確率。∆ 表示注意力池化探測和線性探測之間的性能差距,∆ 值越大表明從學習簡單的線性特徵向捕捉更復雜的非線性語義表示轉變。
語義分割性能

不同版本InternViT的語義分割性能:在ADE20K和COCO - Stuff - 164K上使用三種配置(線性探測、頭部調優和全調優)對模型進行評估。表格顯示了每種配置的mIoU分數及其平均值。∆1 表示頭部調優和線性探測之間的差距,而∆2 表示全調優和線性探測之間的差距。∆ 值越大表明從簡單的線性特徵向更復雜的非線性表示轉變。
💻 使用示例
基礎用法
import torch
from PIL import Image
from transformers import AutoModel, CLIPImageProcessor
model = AutoModel.from_pretrained(
'OpenGVLab/InternViT-300M-448px-V2_5',
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True).cuda().eval()
image = Image.open('./examples/image1.jpg').convert('RGB')
image_processor = CLIPImageProcessor.from_pretrained('OpenGVLab/InternViT-300M-448px-V2_5')
pixel_values = image_processor(images=image, return_tensors='pt').pixel_values
pixel_values = pixel_values.to(torch.bfloat16).cuda()
outputs = model(pixel_values)
⚠️ 重要提示
根據我們的經驗,InternViT V2.5系列更適合構建MLLM,而非傳統的計算機視覺任務。
📄 許可證
本項目採用MIT許可證發佈。
📚 引用
如果您在研究中發現本項目有用,請考慮引用:
@article{chen2024expanding,
title={Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling},
author={Chen, Zhe and Wang, Weiyun and Cao, Yue and Liu, Yangzhou and Gao, Zhangwei and Cui, Erfei and Zhu, Jinguo and Ye, Shenglong and Tian, Hao and Liu, Zhaoyang and others},
journal={arXiv preprint arXiv:2412.05271},
year={2024}
}
@article{gao2024mini,
title={Mini-internvl: A flexible-transfer pocket multimodal model with 5\% parameters and 90\% performance},
author={Gao, Zhangwei and Chen, Zhe and Cui, Erfei and Ren, Yiming and Wang, Weiyun and Zhu, Jinguo and Tian, Hao and Ye, Shenglong and He, Junjun and Zhu, Xizhou and others},
journal={arXiv preprint arXiv:2410.16261},
year={2024}
}
@article{chen2024far,
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites},
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
journal={arXiv preprint arXiv:2404.16821},
year={2024}
}
@inproceedings{chen2024internvl,
title={Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks},
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and others},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={24185--24198},
year={2024}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)


 Transformers 支持多種語言
Transformers 支持多種語言