🚀 InternViT-300M-448px-V2_5
InternViT-300M-448px-V2_5は、InternViT-300M-448pxをベースに大幅に強化されたモデルです。ViTの増分学習を用いることで、視覚エンコーダの視覚特徴抽出能力が向上し、より包括的な情報を捉えることができます。
[📂 GitHub] [📜 InternVL 1.0] [📜 InternVL 1.5] [📜 Mini-InternVL] [📜 InternVL 2.5]
[🆕 Blog] [🗨️ Chat Demo] [🤗 HF Demo] [🚀 Quick Start] [📖 Documents]
🚀 クイックスタート
⚠️ 重要提示
経験上、InternViT V2.5シリーズは、従来のコンピュータビジョンタスクよりもMLLMの構築に適しています。
import torch
from PIL import Image
from transformers import AutoModel, CLIPImageProcessor
model = AutoModel.from_pretrained(
'OpenGVLab/InternViT-300M-448px-V2_5',
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True).cuda().eval()
image = Image.open('./examples/image1.jpg').convert('RGB')
image_processor = CLIPImageProcessor.from_pretrained('OpenGVLab/InternViT-300M-448px-V2_5')
pixel_values = image_processor(images=image, return_tensors='pt').pixel_values
pixel_values = pixel_values.to(torch.bfloat16).cuda()
outputs = model(pixel_values)
✨ 主な機能
視覚特徴抽出能力の向上
InternViT-300M-448px-V2_5は、ViT増分学習とNTP損失を用いることで、視覚エンコーダの視覚特徴抽出能力を向上させています。これにより、LAION-5Bなどの大規模ウェブデータセットでは表現が不十分な領域(多言語OCRデータや数学チャートなど)でも、より包括的な情報を捉えることができます。
マルチモーダルデータの動的高解像度対応
InternVL 2.0と2.5では、動的高解像度トレーニングアプローチを拡張し、マルチ画像やビデオデータセットの処理能力を強化しています。
シングルモデルトレーニングパイプラインの最適化
InternVL 2.5のシングルモデルトレーニングパイプラインは、3つの段階に構成されており、モデルの視覚知覚とマルチモーダル能力を強化するように設計されています。
📚 ドキュメント
InternViT 2.5ファミリー
以下の表は、InternViT 2.5シリーズの概要を示しています。
| モデル名 |
HFリンク |
| InternViT-300M-448px-V2_5 |
🤗 link |
| InternViT-6B-448px-V2_5 |
🤗 link |
モデルアーキテクチャ
InternVL 2.5は、以前のバージョンであるInternVL 1.5と2.0と同じモデルアーキテクチャを保持しており、「ViT-MLP-LLM」パラダイムに従っています。この新バージョンでは、新たに増分事前学習されたInternViTを、ランダムに初期化されたMLPプロジェクターを用いて、InternLM 2.5やQwen 2.5などの様々な事前学習済みLLMと統合しています。

前のバージョンと同様に、ピクセルアンシャッフル操作を適用し、視覚トークンの数を元の4分の1に減らしています。また、InternVL 1.5と同様の動的解像度戦略を採用し、画像を448×448ピクセルのタイルに分割しています。InternVL 2.0以降の主な違いは、マルチ画像やビデオデータのサポートを追加したことです。
トレーニング戦略
マルチモーダルデータの動的高解像度
InternVL 2.0と2.5では、動的高解像度トレーニングアプローチを拡張し、マルチ画像やビデオデータセットの処理能力を強化しています。

- 単一画像データセットの場合、タイルの総数
n_maxは、最大解像度を得るために単一画像に割り当てられます。視覚トークンは<img>と</img>タグで囲まれます。
- マルチ画像データセットの場合、タイルの総数
n_maxは、サンプル内のすべての画像に分散されます。各画像はImage-1などの補助タグでラベル付けされ、<img>と</img>タグで囲まれます。
- ビデオの場合、各フレームは448×448にリサイズされます。フレームは
Frame-1などのタグでラベル付けされ、画像と同様に<img>と</img>タグで囲まれます。
シングルモデルトレーニングパイプライン
InternVL 2.5のシングルモデルトレーニングパイプラインは、3つの段階に構成されており、モデルの視覚知覚とマルチモーダル能力を強化するように設計されています。

- 段階1: MLPウォームアップ:この段階では、MLPプロジェクターのみがトレーニングされ、視覚エンコーダと言語モデルは凍結されます。動的高解像度トレーニング戦略が適用され、コストは増えますが、より良いパフォーマンスが得られます。このフェーズは、強力なクロスモーダルアラインメントを確保し、安定したマルチモーダルトレーニングのためにモデルを準備します。
- 段階1.5: ViT増分学習(オプション):この段階では、段階1と同じデータを用いて、視覚エンコーダとMLPプロジェクターの増分トレーニングが可能です。これにより、エンコーダの多言語OCRや数学チャートなどの希少領域の処理能力が向上します。トレーニング後、エンコーダは再トレーニングすることなくLLM間で再利用できるため、新しい領域が導入されない限り、この段階はオプションです。
- 段階2: フルモデルインストラクションチューニング:この段階では、高品質のマルチモーダルインストラクションデータセットでモデル全体がトレーニングされます。ノイズの多いデータは、繰り返しや誤った出力などの問題を引き起こす可能性があるため、LLMの性能低下を防ぐために、厳格なデータ品質管理が行われます。この段階の後、トレーニングプロセスは完了します。
視覚能力の評価
視覚エンコーダのパフォーマンスを、様々なドメインやタスクにわたって包括的に評価しています。評価は、(1) グローバルビューのセマンティック品質を表す画像分類、(2) ローカルビューのセマンティック品質を捉えるセマンティックセグメンテーションの2つの主要なカテゴリに分けられます。このアプローチにより、InternViTの連続するバージョンアップデートにわたって、表現品質を評価することができます。詳細については、技術レポートを参照してください。
画像分類
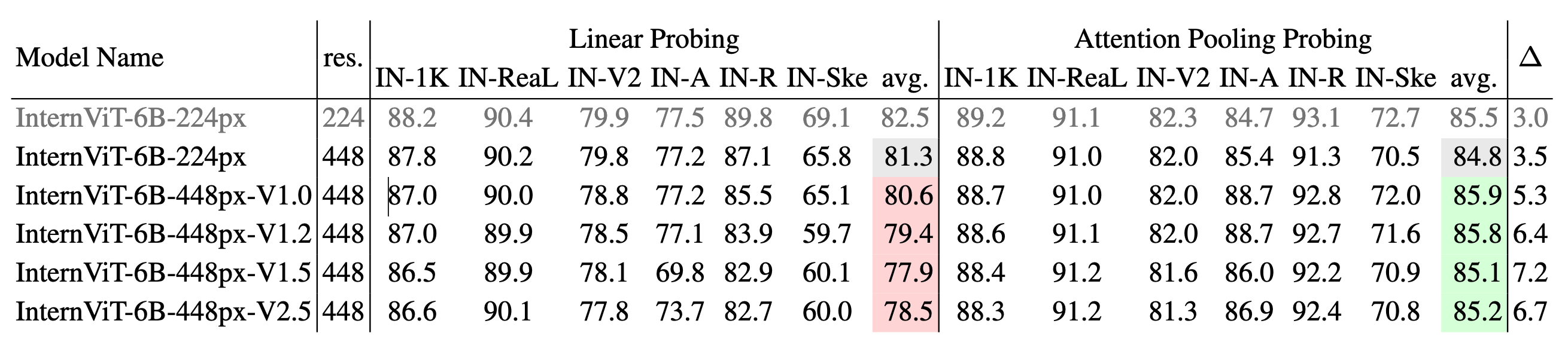
InternViTの異なるバージョンにおける画像分類パフォーマンス:IN-1Kをトレーニングに使用し、IN-1K検証セットおよび複数のImageNetバリアント(IN-ReaL、IN-V2、IN-A、IN-R、IN-Sketchなど)で評価しています。結果は、線形プロービングとアテンションプーリングプロービングの両方の方法について報告され、各方法の平均精度が示されています。∆は、アテンションプーリングプロービングと線形プロービングの間のパフォーマンスギャップを表し、∆が大きいほど、単純な線形特徴の学習から、より複雑な非線形セマンティック表現の捕捉へのシフトを示しています。
セマンティックセグメンテーションパフォーマンス

InternViTの異なるバージョンにおけるセマンティックセグメンテーションパフォーマンス:モデルは、ADE20KとCOCO-Stuff-164Kで、線形プロービング、ヘッドチューニング、フルチューニングの3つの構成で評価されています。表には、各構成のmIoUスコアとその平均が示されています。∆1は、ヘッドチューニングと線形プロービングの間のギャップを表し、∆2は、フルチューニングと線形プロービングの間のギャップを示しています。∆値が大きいほど、単純な線形特徴から、より複雑な非線形表現へのシフトを示しています。
📄 ライセンス
このプロジェクトは、MITライセンスの下で公開されています。
引用
このプロジェクトがあなたの研究に役立った場合は、以下を引用してください。
@article{chen2024expanding,
title={Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling},
author={Chen, Zhe and Wang, Weiyun and Cao, Yue and Liu, Yangzhou and Gao, Zhangwei and Cui, Erfei and Zhu, Jinguo and Ye, Shenglong and Tian, Hao and Liu, Zhaoyang and others},
journal={arXiv preprint arXiv:2412.05271},
year={2024}
}
@article{gao2024mini,
title={Mini-internvl: A flexible-transfer pocket multimodal model with 5\% parameters and 90\% performance},
author={Gao, Zhangwei and Chen, Zhe and Cui, Erfei and Ren, Yiming and Wang, Weiyun and Zhu, Jinguo and Tian, Hao and Ye, Shenglong and He, Junjun and Zhu, Xizhou and others},
journal={arXiv preprint arXiv:2410.16261},
year={2024}
}
@article{chen2024far,
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites},
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
journal={arXiv preprint arXiv:2404.16821},
year={2024}
}
@inproceedings{chen2024internvl,
title={Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks},
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and others},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={24185--24198},
year={2024}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)


 Transformers 複数言語対応
Transformers 複数言語対応