🚀 AltCLIP
我們提出了一個簡單高效的方法去訓練更加優秀的雙語CLIP模型,命名為AltCLIP。該模型基於特定框架和豐富數據集訓練,能為AltDiffusion模型提供支持,在多語言圖像文本檢索任務中表現出色。
🚀 快速開始
AltCLIP是一個簡單高效的雙語CLIP模型,以下為你介紹它的基本信息和使用方式。
⚠️ 重要提示
訪問此模型前需額外步驟。該模型開放訪問,採用CreativeML OpenRAIL - M許可證,進一步明確了權利和使用規範。此許可證規定:
- 不得使用該模型故意生成或分享非法或有害的輸出或內容。
- 北京智源人工智能研究院(BAAI)對您生成的輸出不主張任何權利,您可自由使用,但需對其使用負責,且使用不得違反許可證規定。
- 您可以重新分發模型權重,並將模型用於商業用途或作為服務。若這樣做,請務必包含與許可證相同的使用限制,並向所有用戶分享一份CreativeML OpenRAIL - M許可證副本(請完整仔細閱讀許可證)。
請在此處閱讀完整許可證:https://huggingface.co/spaces/CompVis/stable-diffusion-license
點擊下方“訪問倉庫”,即表示您同意您的聯繫信息(電子郵件地址和用戶名)也可與模型作者共享。
✨ 主要特性
- 雙語支持:支持中英文兩種語言,能更好地適應不同語言環境下的圖像 - 文本任務。
- 高效訓練:採用簡單高效的訓練方法,結合平行知識蒸餾和雙語對比學習,提升模型性能。
- 下游效果好:在文本 - 圖像檢索等下游任務中表現出色,尤其在中文任務上顯著優於傳統CLIP模型。
📦 安裝指南
暫未提供相關安裝步驟,你可以從 FlagAI AltCLIP 下載代碼進行使用。
💻 使用示例
基礎用法
from PIL import Image
import requests
from modeling_altclip import AltCLIP
from processing_altclip import AltCLIPProcessor
model = AltCLIP.from_pretrained("BAAI/AltCLIP")
processor = AltCLIPProcessor.from_pretrained("BAAI/AltCLIP")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image
probs = logits_per_image.softmax(dim=1)
📚 詳細文檔
簡介
我們提出了一個簡單高效的方法去訓練更加優秀的雙語CLIP模型,命名為AltCLIP。AltCLIP基於 Stable Diffusiosn 訓練,訓練數據來自 WuDao數據集 和 LIAON 。
AltCLIP模型可以為本項目中的AltDiffusion模型提供支持,關於AltDiffusion模型的具體信息可查看此教程 。
模型代碼已經在 FlagAI 上開源,權重位於我們搭建的 modelhub 上。我們還提供了微調,推理,驗證的腳本,歡迎試用。
引用
關於AltCLIP,我們已經推出了相關報告,有更多細節可以查閱,如對您的工作有幫助,歡迎引用。
@article{https://doi.org/10.48550/arxiv.2211.06679,
doi = {10.48550/ARXIV.2211.06679},
url = {https://arxiv.org/abs/2211.06679},
author = {Chen, Zhongzhi and Liu, Guang and Zhang, Bo - Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences},
title = {AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities},
publisher = {arXiv},
year = {2022},
copyright = {arXiv.org perpetual, non - exclusive license}
}
訓練
訓練共有兩個階段。
在平行知識蒸餾階段,我們只是使用平行語料文本來進行蒸餾(平行語料相對於圖文對更容易獲取且數量更大)。在雙語對比學習階段,我們使用少量的中 - 英 圖像 - 文本對(一共約2百萬)來訓練我們的文本編碼器以更好地適應圖像編碼器。
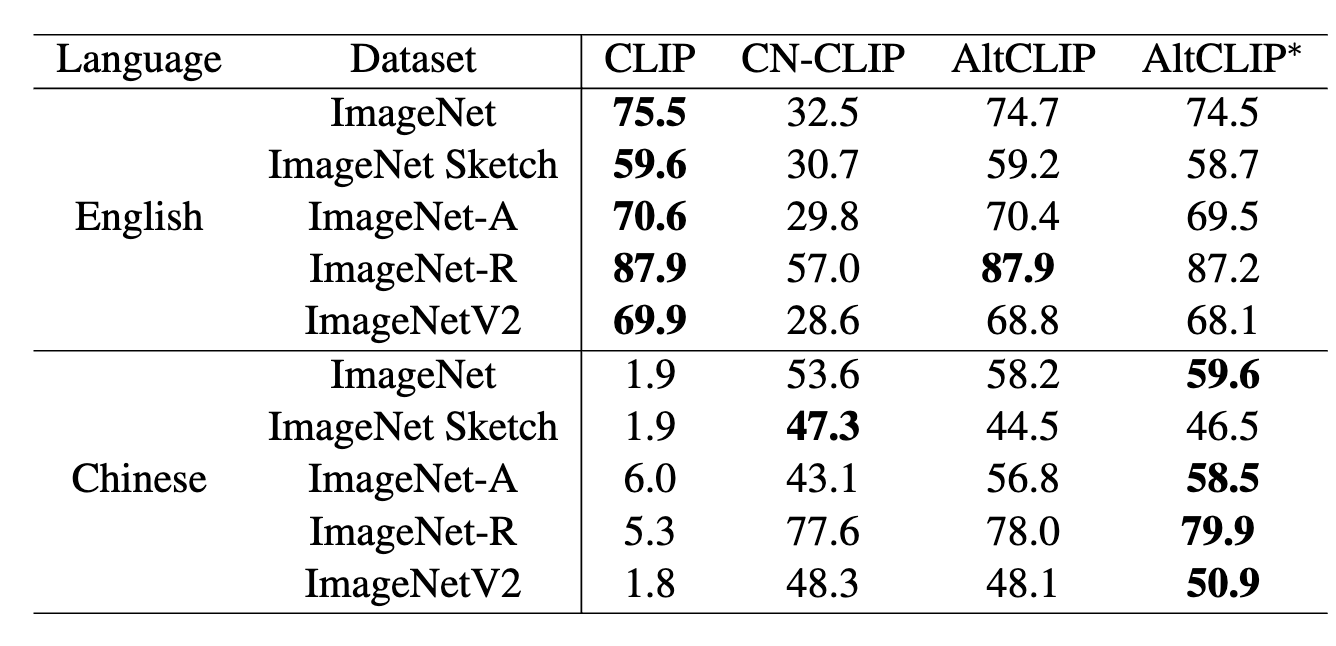
下游效果
| 語言 |
方法 |
文本到圖像檢索(R@1) |
文本到圖像檢索(R@5) |
文本到圖像檢索(R@10) |
圖像到文本檢索(R@1) |
圖像到文本檢索(R@5) |
圖像到文本檢索(R@10) |
MR |
| 英文 |
CLIP |
65.0 |
87.1 |
92.2 |
85.1 |
97.3 |
99.2 |
87.6 |
| 英文 |
Taiyi |
25.3 |
48.2 |
59.2 |
39.3 |
68.1 |
79.6 |
53.3 |
| 英文 |
Wukong |
- |
- |
- |
- |
- |
- |
- |
| 英文 |
R2D2 |
- |
- |
- |
- |
- |
- |
- |
| 英文 |
CN - CLIP |
49.5 |
76.9 |
83.8 |
66.5 |
91.2 |
96.0 |
77.3 |
| 英文 |
AltCLIP |
66.3 |
87.8 |
92.7 |
85.9 |
97.7 |
99.1 |
88.3 |
| 英文 |
AltCLIP∗ |
72.5 |
91.6 |
95.4 |
86.0 |
98.0 |
99.1 |
90.4 |
| 中文 |
CLIP |
0.0 |
2.4 |
4.0 |
2.3 |
8.1 |
12.6 |
5.0 |
| 中文 |
Taiyi |
53.7 |
79.8 |
86.6 |
63.8 |
90.5 |
95.9 |
78.4 |
| 中文 |
Wukong |
51.7 |
78.9 |
86.3 |
76.1 |
94.8 |
97.5 |
80.9 |
| 中文 |
R2D2 |
60.9 |
86.8 |
92.7 |
77.6 |
96.7 |
98.9 |
85.6 |
| 中文 |
CN - CLIP |
68.0 |
89.7 |
94.4 |
80.2 |
96.6 |
98.2 |
87.9 |
| 中文 |
AltCLIP |
63.7 |
86.3 |
92.1 |
84.7 |
97.4 |
98.7 |
87.2 |
| 中文 |
AltCLIP∗ |
69.8 |
89.9 |
94.7 |
84.8 |
97.4 |
98.8 |
89.2 |
可視化效果
基於AltCLIP,我們還開發了AltDiffusion模型,可視化效果如下。

📄 許可證
本模型採用CreativeML OpenRAIL - M許可證。具體規定如下:
- 您不能使用該模型故意生成或分享非法或有害的輸出或內容。
- 北京智源人工智能研究院(BAAI)對您生成的輸出不主張任何權利,您可自由使用,但需對其使用負責,且使用不得違反許可證規定。
- 您可以重新分發模型權重,並將模型用於商業用途或作為服務。若這樣做,請務必包含與許可證相同的使用限制,並向所有用戶分享一份CreativeML OpenRAIL - M許可證副本(請完整仔細閱讀許可證)。
請在此處閱讀完整許可證:https://huggingface.co/spaces/CompVis/stable-diffusion-license 。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors Transformers 支持多種語言
Transformers 支持多種語言