🚀 AltCLIP
A simple and efficient method to train a better bilingual CLIP model
🚀 Quick Start
AltCLIP is a bilingual CLIP model that can provide support for the AltDiffusion model. You can download the code from FlagAI AltCLIP and follow the instructions in the README to get started.
✨ Features
- Bilingual Support: AltCLIP supports both Chinese and English, making it suitable for a wide range of applications.
- High Performance: The model shows excellent performance in text-image retrieval tasks, outperforming many existing models.
- Open Source: The model code is open source on FlagAI, and the weights are available on modelhub.
📋 Model Information
| Property |
Details |
| Name |
AltCLIP |
| Task |
text-image representation |
| Language(s) |
Chinese & English |
| Model |
CLIP |
| Github |
FlagAI |
📚 Documentation
Brief Introduction
We propose a simple and efficient method to train a better bilingual CLIP model, named AltCLIP. AltCLIP is trained based on Stable Diffusiosn, and the training data comes from WuDao dataset and LIAON.
The AltCLIP model can support the AltDiffusion model in this project. For more information about the AltDiffusion model, please refer to this tutorial.
Training
There are two phases of training.
In the parallel knowledge distillation phase, we only use parallel corpus texts for distillation (parallel corpus is easier to obtain and larger in number compared to image text pairs). In the bilingual comparison learning phase, we use a small number of Chinese-English image-text pairs (about 2 million in total) to train our text encoder to better fit the image encoder.
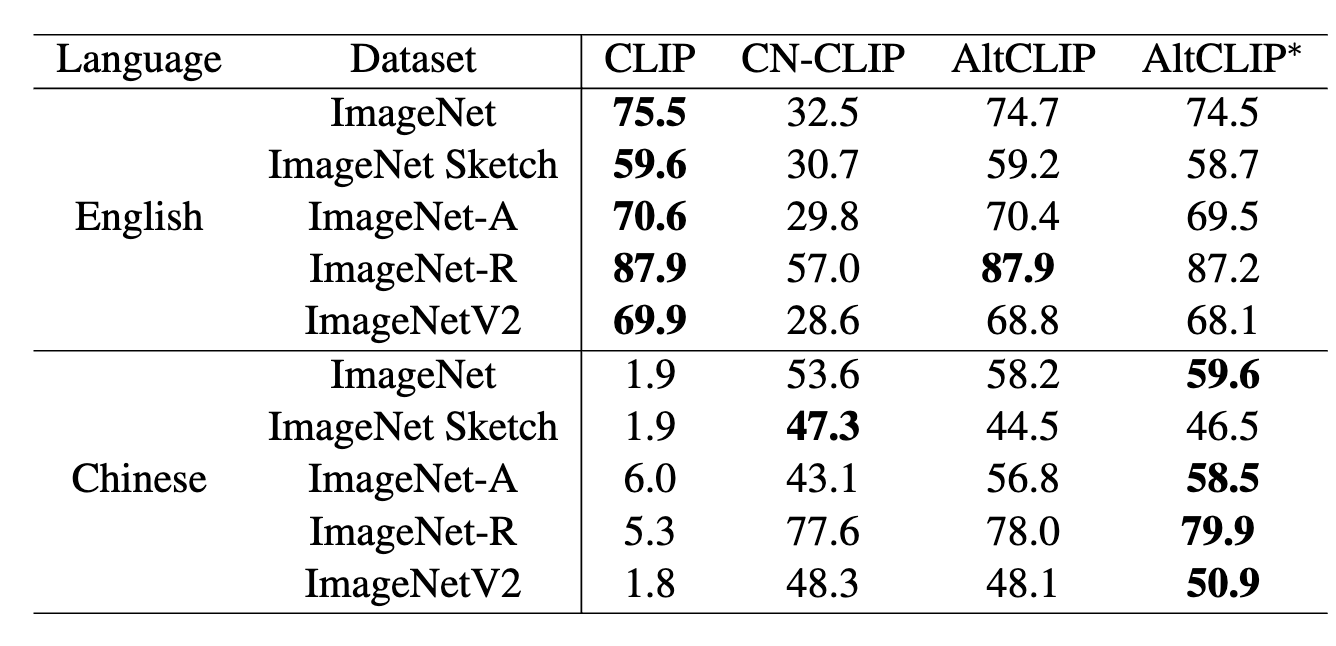
Performance
The following table shows the performance of AltCLIP and other models in text-to-image and image-to-text retrieval tasks:
| Language |
Method |
Text-to-Image Retrival (R@1) |
Text-to-Image Retrival (R@5) |
Text-to-Image Retrival (R@10) |
Image-to-Text Retrival (R@1) |
Image-to-Text Retrival (R@5) |
Image-to-Text Retrival (R@10) |
MR |
| English |
CLIP |
65.0 |
87.1 |
92.2 |
85.1 |
97.3 |
99.2 |
87.6 |
| English |
Taiyi |
25.3 |
48.2 |
59.2 |
39.3 |
68.1 |
79.6 |
53.3 |
| English |
Wukong |
- |
- |
- |
- |
- |
- |
- |
| English |
R2D2 |
- |
- |
- |
- |
- |
- |
- |
| English |
CN-CLIP |
49.5 |
76.9 |
83.8 |
66.5 |
91.2 |
96.0 |
77.3 |
| English |
AltCLIP |
66.3 |
87.8 |
92.7 |
85.9 |
97.7 |
99.1 |
88.3 |
| English |
AltCLIP∗ |
72.5 |
91.6 |
95.4 |
86.0 |
98.0 |
99.1 |
90.4 |
| Chinese |
CLIP |
0.0 |
2.4 |
4.0 |
2.3 |
8.1 |
12.6 |
5.0 |
| Chinese |
Taiyi |
53.7 |
79.8 |
86.6 |
63.8 |
90.5 |
95.9 |
78.4 |
| Chinese |
Wukong |
51.7 |
78.9 |
86.3 |
76.1 |
94.8 |
97.5 |
80.9 |
| Chinese |
R2D2 |
60.9 |
86.8 |
92.7 |
77.6 |
96.7 |
98.9 |
85.6 |
| Chinese |
CN-CLIP |
68.0 |
89.7 |
94.4 |
80.2 |
96.6 |
98.2 |
87.9 |
| Chinese |
AltCLIP |
63.7 |
86.3 |
92.1 |
84.7 |
97.4 |
98.7 |
87.2 |
| Chinese |
AltCLIP∗ |
69.8 |
89.9 |
94.7 |
84.8 |
97.4 |
98.8 |
89.2 |
Visualization effects
Based on AltCLIP, we have also developed the AltDiffusion model, visualized as follows:

💻 Usage Examples
Basic Usage
from PIL import Image
import requests
from modeling_altclip import AltCLIP
from processing_altclip import AltCLIPProcessor
model = AltCLIP.from_pretrained("BAAI/AltCLIP")
processor = AltCLIPProcessor.from_pretrained("BAAI/AltCLIP")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image
probs = logits_per_image.softmax(dim=1)
🔧 Technical Details
Training Phases
The training of AltCLIP consists of two phases:
- Parallel Knowledge Distillation Phase: We use parallel corpus texts for distillation. Parallel corpus is easier to obtain and larger in quantity compared to image-text pairs.
- Bilingual Contrastive Learning Phase: We use a small number (about 2 million) of Chinese-English image-text pairs to train the text encoder to better match the image encoder.
📄 License
This model is licensed under the CreativeML OpenRAIL-M license. By accessing the repository, you agree to the terms of the license and that your contact information (email address and username) may be shared with the model authors.
📚 Citation
If you find this work helpful, please consider citing the following paper:
@article{https://doi.org/10.48550/arxiv.2211.06679,
doi = {10.48550/ARXIV.2211.06679},
url = {https://arxiv.org/abs/2211.06679},
author = {Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences},
title = {AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities},
publisher = {arXiv},
year = {2022},
copyright = {arXiv.org perpetual, non-exclusive license}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors