🚀 🗿 ruGPT-3.5 13B
ruGPT-3.5 13B 是一款面向俄語的語言模型。從名稱可以推測,該模型擁有 130 億個參數,是目前為止最大的模型,並且被用於訓練 GigaChat(更多相關信息可查看文章)。
🚀 快速開始
ruGPT-3.5 13B 是強大的俄語語言模型,具備豐富的知識和出色的語言生成能力,可用於多種自然語言處理任務。
✨ 主要特性
- 擁有 130 億參數,是目前最大的模型。
- 用於訓練 GigaChat,具備較高的性能和質量。
📦 安裝指南
文檔未提及安裝步驟,故跳過此章節。
💻 使用示例
基礎用法
request = "Стих про программиста может быть таким:"
encoded_input = tokenizer(request, return_tensors='pt', \
add_special_tokens=False).to('cuda:0')
output = model.generate(
**encoded_input,
num_beams=2,
do_sample=True,
max_new_tokens=100
)
print(tokenizer.decode(output[0], skip_special_tokens=True))
>>> Стих про программиста может быть таким:
Программист сидит в кресле,
Стих сочиняет он про любовь,
Он пишет, пишет, пишет, пишет...
И не выходит ни черта!
高級用法
request = "Нейронная сеть — это"
encoded_input = tokenizer(request, return_tensors='pt', \
add_special_tokens=False).to('cuda:0')
output = model.generate(
**encoded_input,
num_beams=4,
do_sample=True,
max_new_tokens=100
)
print(tokenizer.decode(output[0], skip_special_tokens=True))
>>> Нейронная сеть — это математическая модель, состоящая из большого
количества нейронов, соединенных между собой электрическими связями.
Нейронная сеть может быть смоделирована на компьютере, и с ее помощью
можно решать задачи, которые не поддаются решению с помощью традиционных
математических методов.
request = "Гагарин полетел в космос в"
encoded_input = tokenizer(request, return_tensors='pt', \
add_special_tokens=False).to('cuda:0')
output = model.generate(
**encoded_input,
num_beams=2,
do_sample=True,
max_new_tokens=100
)
print(tokenizer.decode(output[0], skip_special_tokens=True))
>>> Гагарин полетел в космос в 1961 году. Это было первое в истории
человечества космическое путешествие. Юрий Гагарин совершил его
на космическом корабле Восток-1. Корабль был запущен с космодрома
Байконур.
📚 詳細文檔
數據集
該模型在 300GB 的多領域數據上進行預訓練,然後在 100GB 的代碼和法律文檔上進行額外訓練。以下是數據集結構:
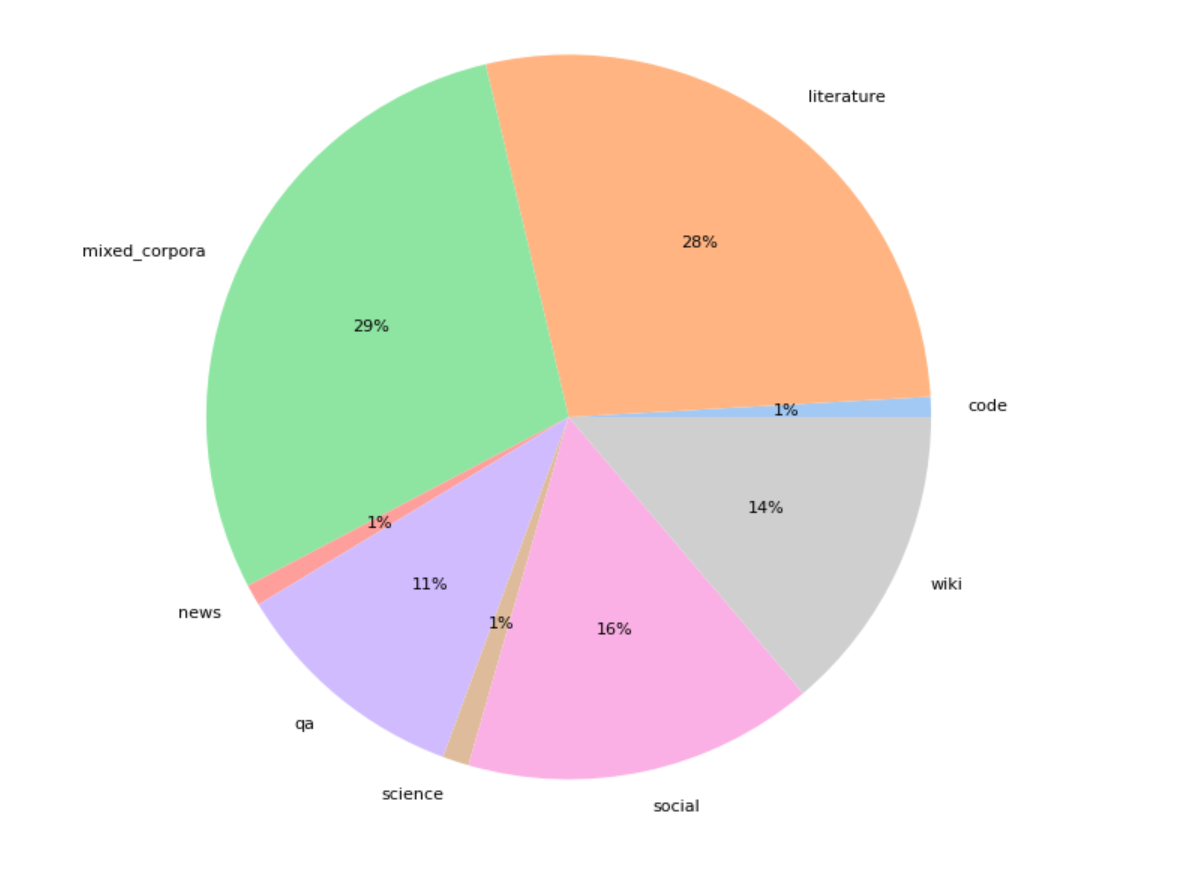
訓練數據經過去重處理,文本去重包括對語料庫中的每個文本進行 64 位哈希處理,以保留具有唯一哈希值的文本。我們還使用 zlib4 根據文檔的文本壓縮率對文檔進行過濾,丟棄壓縮率過高和過低的去重文本。
信息表格
| 屬性 |
詳情 |
| 模型類型 |
俄語語言模型 |
| 訓練數據 |
先在 300GB 多領域數據預訓練,後在 100GB 代碼和法律文檔額外訓練 |
🔧 技術細節
該模型使用 Deepspeed 和 Megatron 庫進行訓練,在 3000 億標記的數據集上進行 3 個輪次的訓練,在 512 個 V100 GPU 上訓練約 45 天。之後,在額外數據(見上文)上以序列長度 2048 進行 1 個輪次的微調,在 200 個 A100 GPU 上訓練約 20 天。
最終訓練後,該模型在俄語上的困惑度約為 8.8。

📄 許可證
本項目採用 MIT 許可證。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多種語言
Transformers 支持多種語言