%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
TW
Cogagent Vqa Hf
CogAgent是基於CogVLM改進的開源視覺語言模型,專注於單輪視覺問答任務
下載量 238
發布時間 : 12/16/2023
模型概述
CogAgent是一個強大的視覺語言模型,特別優化了單輪視覺問答能力,支持1120x1120高分辨率圖像輸入,在多個VQA基準測試上表現優異
模型特點
高分辨率圖像處理
支持1120x1120超高分辨率圖像輸入,能捕捉更精細的視覺細節
卓越的VQA性能
在9個跨模態基準測試中達到頂尖水平,包括VQAv2、MM-Vet等
優化的單輪問答
專門針對單輪視覺問答任務進行優化,相比chat版本在VQA任務上表現更優
模型能力
視覺問答
圖像理解
文本生成
高分辨率圖像處理
使用案例
教育
教材圖像問答
回答關於教材圖表、插圖的各類問題
準確理解圖表內容並生成正確回答
商業
商業圖表分析
分析商業報告中的各類圖表數據
準確提取圖表信息並生成分析結果
🚀 CogAgent
CogAgent 是一個基於 CogVLM 改進的開源視覺語言模型。它在圖像理解和 GUI 代理方面表現出色,支持高分辨率視覺輸入和對話問答,可用於多種跨模態基準測試和 GUI 操作任務。
🚀 快速開始
使用以下 Python 代碼在 cli_demo.py 中快速開始:
import torch
from PIL import Image
from transformers import AutoModelForCausalLM, LlamaTokenizer
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--quant", choices=[4], type=int, default=None, help='quantization bits')
parser.add_argument("--from_pretrained", type=str, default="THUDM/cogagent-chat-hf", help='pretrained ckpt')
parser.add_argument("--local_tokenizer", type=str, default="lmsys/vicuna-7b-v1.5", help='tokenizer path')
parser.add_argument("--fp16", action="store_true")
parser.add_argument("--bf16", action="store_true")
args = parser.parse_args()
MODEL_PATH = args.from_pretrained
TOKENIZER_PATH = args.local_tokenizer
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
tokenizer = LlamaTokenizer.from_pretrained(TOKENIZER_PATH)
if args.bf16:
torch_type = torch.bfloat16
else:
torch_type = torch.float16
print("========Use torch type as:{} with device:{}========\n\n".format(torch_type, DEVICE))
if args.quant:
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch_type,
low_cpu_mem_usage=True,
load_in_4bit=True,
trust_remote_code=True
).eval()
else:
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch_type,
low_cpu_mem_usage=True,
load_in_4bit=args.quant is not None,
trust_remote_code=True
).to(DEVICE).eval()
while True:
image_path = input("image path >>>>> ")
if image_path == "stop":
break
image = Image.open(image_path).convert('RGB')
history = []
while True:
query = input("Human:")
if query == "clear":
break
input_by_model = model.build_conversation_input_ids(tokenizer, query=query, history=history, images=[image])
inputs = {
'input_ids': input_by_model['input_ids'].unsqueeze(0).to(DEVICE),
'token_type_ids': input_by_model['token_type_ids'].unsqueeze(0).to(DEVICE),
'attention_mask': input_by_model['attention_mask'].unsqueeze(0).to(DEVICE),
'images': [[input_by_model['images'][0].to(DEVICE).to(torch_type)]],
}
if 'cross_images' in input_by_model and input_by_model['cross_images']:
inputs['cross_images'] = [[input_by_model['cross_images'][0].to(DEVICE).to(torch_type)]]
# add any transformers params here.
gen_kwargs = {"max_length": 2048,
"temperature": 0.9,
"do_sample": False}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
response = tokenizer.decode(outputs[0])
response = response.split("</s>")[0]
print("\nCog:", response)
history.append((query, response))
然後運行:
python cli_demo_hf.py --bf16
✨ 主要特性
多版本選擇
我們開源了 2 個版本的 CogAgent 檢查點,你可以根據需求選擇:
cogagent-chat:該模型在 GUI 代理、視覺多輪對話、視覺定位 等方面具有強大能力。如果你需要 GUI 代理和視覺定位功能,或需要與給定圖像進行多輪對話,建議使用此版本模型。cogagent-vqa:該模型在 單輪視覺對話 方面具有 更強 的能力。如果你需要 處理 VQA 基準測試(如 MMVET、VQAv2),建議使用此模型。
強大性能表現
- 跨模態基準測試:CogAgent - 18B 在 9 個跨模態基準測試中取得了最先進的通用性能,包括 VQAv2、MM - Vet、POPE、ST - VQA、OK - VQA、TextVQA、ChartQA、InfoVQA、DocVQA。
- GUI 操作數據集:CogAgent - 18B 在 GUI 操作數據集(包括 AITW 和 Mind2Web)上顯著超越了現有模型。
新增特性
- 高分辨率支持:支持更高分辨率的視覺輸入和對話問答,支持 1120x1120 的超高分辨率圖像輸入。
- 視覺 Agent 能力:具備視覺 Agent 的能力,能夠針對任何給定的 GUI 截圖任務返回計劃、下一步行動和帶座標的具體操作。
- 增強的 GUI 問答能力:增強了與 GUI 相關的問答能力,能夠處理關於任何 GUI 截圖(如網頁、PC 應用程序、移動應用程序等)的問題。
- OCR 任務能力提升:通過改進預訓練和微調,增強了在 OCR 相關任務中的能力。
模型參數
CogAgent - 18B 擁有 110 億視覺參數和 70 億語言參數。
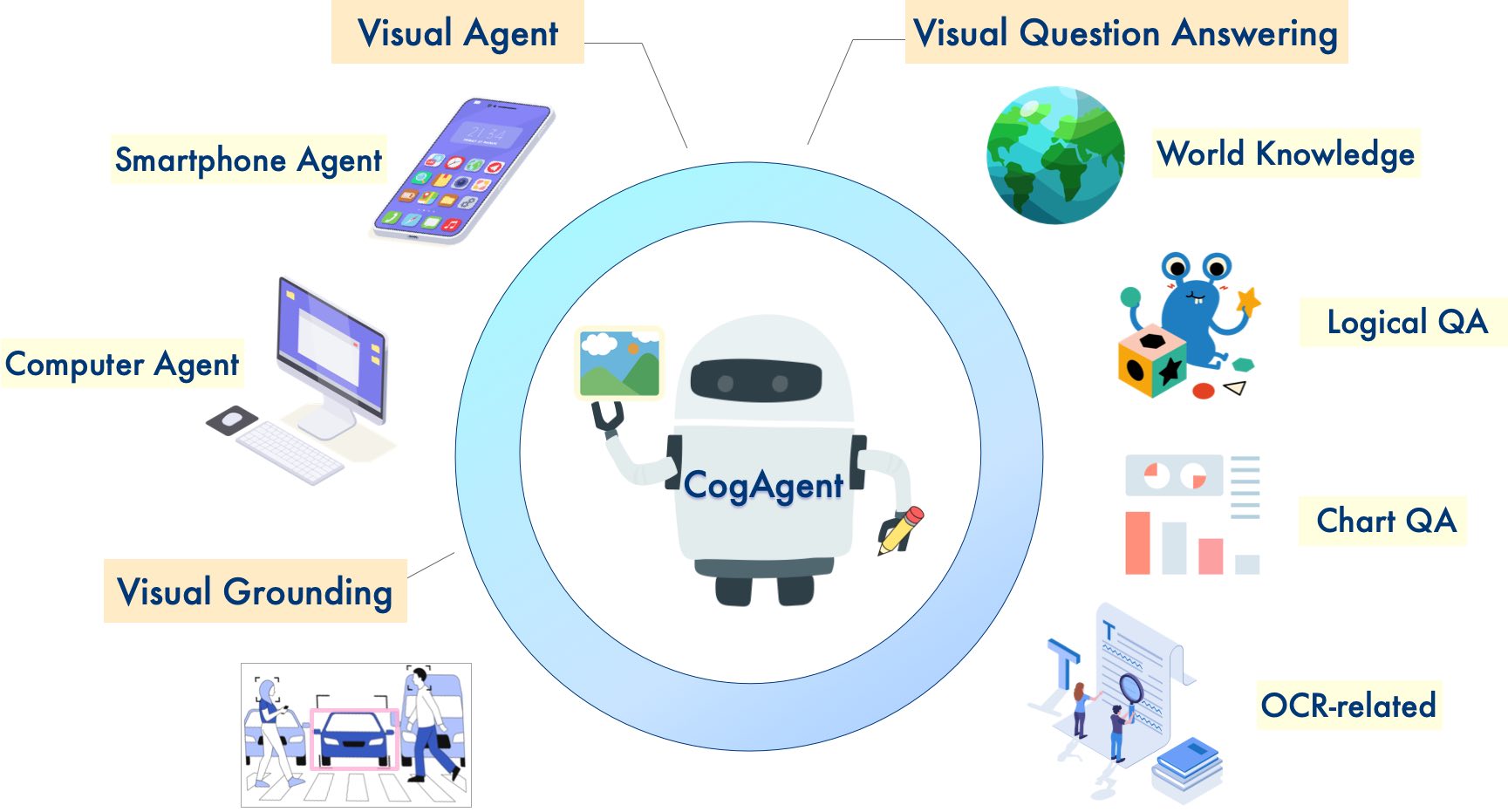
模型使用說明
本倉庫中的模型權重可免費用於學術研究。希望將模型用於 商業目的 的用戶必須在 此處 註冊。註冊用戶可以免費將模型用於商業活動,但必須遵守本許可證的所有條款和條件。許可證聲明應包含在軟件的所有副本或重要部分中。
📄 許可證
本倉庫中的代碼根據 Apache - 2.0 許可證 開源,而 CogAgent 和 CogVLM 模型權重的使用必須遵守 模型許可證。
📚 詳細文檔
引用與致謝
如果你覺得我們的工作有幫助,請考慮引用以下論文:
@misc{hong2023cogagent,
title={CogAgent: A Visual Language Model for GUI Agents},
author={Wenyi Hong and Weihan Wang and Qingsong Lv and Jiazheng Xu and Wenmeng Yu and Junhui Ji and Yan Wang and Zihan Wang and Yuxiao Dong and Ming Ding and Jie Tang},
year={2023},
eprint={2312.08914},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{wang2023cogvlm,
title={CogVLM: Visual Expert for Pretrained Language Models},
author={Weihan Wang and Qingsong Lv and Wenmeng Yu and Wenyi Hong and Ji Qi and Yan Wang and Junhui Ji and Zhuoyi Yang and Lei Zhao and Xixuan Song and Jiazheng Xu and Bin Xu and Juanzi Li and Yuxiao Dong and Ming Ding and Jie Tang},
year={2023},
eprint={2311.03079},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
在 CogVLM 的指令微調階段,使用了來自 [MiniGPT - 4](https://github.com/Vision - CAIR/MiniGPT - 4)、[LLAVA](https://github.com/haotian - liu/LLaVA)、[LRV - Instruction](https://github.com/FuxiaoLiu/LRV - Instruction)、[LLaVAR](https://github.com/SALT - NLP/LLaVAR) 和 Shikra 項目的一些英文圖像文本數據,以及許多經典的跨模態工作數據集。我們衷心感謝他們的貢獻。
相關鏈接
- 📖 論文:https://arxiv.org/abs/2312.08914
- 🚀 GitHub:如需瞭解更多信息(如演示、微調、查詢提示),請參考 我們的 GitHub
Clip Vit Large Patch14 336
基於Vision Transformer架構的大規模視覺語言預訓練模型,支持圖像與文本的跨模態理解
文本生成圖像 Transformers
Transformers
C
openai
5.9M
241
Fashion Clip
MIT
FashionCLIP是基於CLIP開發的視覺語言模型,專門針對時尚領域進行微調,能夠生成通用產品表徵。
文本生成圖像 Transformers 英語
F
patrickjohncyh
3.8M
222
Gemma 3 1b It
Gemma 3是Google推出的輕量級先進開放模型系列,基於與Gemini模型相同的研究和技術構建。該模型是多模態模型,能夠處理文本和圖像輸入並生成文本輸出。
文本生成圖像 Transformers
G
google
2.1M
347
Blip Vqa Base
Bsd-3-clause
BLIP是一個統一的視覺語言預訓練框架,擅長視覺問答任務,通過語言-圖像聯合訓練實現多模態理解與生成能力
文本生成圖像 Transformers
B
Salesforce
1.9M
154
CLIP ViT H 14 Laion2b S32b B79k
MIT
基於OpenCLIP框架在LAION-2B英文數據集上訓練的視覺-語言模型,支持零樣本圖像分類和跨模態檢索任務
文本生成圖像 Safetensors
Safetensors
SafetensorsC
laion
1.8M
368
CLIP ViT B 32 Laion2b S34b B79k
MIT
基於OpenCLIP框架在LAION-2B英語子集上訓練的視覺-語言模型,支持零樣本圖像分類和跨模態檢索
文本生成圖像 Safetensors
SafetensorsC
laion
1.1M
112
Pickscore V1
PickScore v1 是一個針對文本生成圖像的評分函數,可用於預測人類偏好、評估模型性能和圖像排序等任務。
文本生成圖像 Transformers
P
yuvalkirstain
1.1M
44
Owlv2 Base Patch16 Ensemble
Apache-2.0
OWLv2是一種零樣本文本條件目標檢測模型,可通過文本查詢在圖像中定位對象。
文本生成圖像 Transformers
O
google
932.80k
99
Llama 3.2 11B Vision Instruct
Llama 3.2 是 Meta 發佈的多語言多模態大型語言模型,支持圖像文本到文本的轉換任務,具備強大的跨模態理解能力。
文本生成圖像 Transformers 支持多種語言
L
meta-llama
784.19k
1,424
Owlvit Base Patch32
Apache-2.0
OWL-ViT是一個零樣本文本條件目標檢測模型,可以通過文本查詢搜索圖像中的對象,無需特定類別的訓練數據。
文本生成圖像 Transformers
O
google
764.95k
129
精選推薦AI模型
Llama 3 Typhoon V1.5x 8b Instruct
專為泰語設計的80億參數指令模型,性能媲美GPT-3.5-turbo,優化了應用場景、檢索增強生成、受限生成和推理任務
大型語言模型 Transformers 支持多種語言
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-Tiny是一個基於SODA數據集訓練的超小型對話模型,專為邊緣設備推理設計,體積僅為Cosmo-3B模型的2%左右。
對話系統 Transformers 英語
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
基於RoBERTa架構的中文抽取式問答模型,適用於從給定文本中提取答案的任務。
問答系統 中文
R
uer
2,694
98