🚀 ChatDB的Natural - SQL - 7B模型
Natural - SQL - 7B是一款在文本轉SQL指令方面表現極為出色的模型,它能夠出色地理解複雜問題,在同規模模型中脫穎而出。
ChatDB.ai | Notebook | Twitter

🚀 快速開始
安裝依賴
確保你安裝了正確版本的transformers庫:
pip install transformers==4.35.2
加載模型
使用以下Python代碼加載模型:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("chatdb/natural-sql-7b")
model = AutoModelForCausalLM.from_pretrained(
"chatdb/natural-sql-7b",
device_map="auto",
torch_dtype=torch.float16,
)
生成SQL
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
generated_ids = model.generate(
**inputs,
num_return_sequences=1,
eos_token_id=100001,
pad_token_id=100001,
max_new_tokens=400,
do_sample=False,
num_beams=1,
)
outputs = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
print(outputs[0].split("```sql")[-1])
✨ 主要特性
- 在文本轉SQL指令方面表現強勁,能出色理解複雜問題。
- 可以處理其他模型通常難以應對的複雜複合問題。
📦 安裝指南
安裝正確版本的transformers庫:
pip install transformers==4.35.2
💻 使用示例
基礎用法
加載模型
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("chatdb/natural-sql-7b")
model = AutoModelForCausalLM.from_pretrained(
"chatdb/natural-sql-7b",
device_map="auto",
torch_dtype=torch.float16,
)
生成SQL
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
generated_ids = model.generate(
**inputs,
num_return_sequences=1,
eos_token_id=100001,
pad_token_id=100001,
max_new_tokens=400,
do_sample=False,
num_beams=1,
)
outputs = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
print(outputs[0].split("```sql")[-1])
提示模板
# Task
Generate a SQL query to answer the following question: `{自然語言問題}`
### PostgreSQL Database Schema
The query will run on a database with the following schema:
<SQL Table DDL Statements>
# SQL
Here is the SQL query that answers the question: `{自然語言問題}`
'''sql
示例SQL輸出
示例模式
CREATE TABLE users (
user_id SERIAL PRIMARY KEY,
username VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL,
password_hash TEXT NOT NULL,
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE projects (
project_id SERIAL PRIMARY KEY,
project_name VARCHAR(100) NOT NULL,
description TEXT,
start_date DATE,
end_date DATE,
owner_id INTEGER REFERENCES users(user_id)
);
CREATE TABLE tasks (
task_id SERIAL PRIMARY KEY,
task_name VARCHAR(100) NOT NULL,
description TEXT,
due_date DATE,
status VARCHAR(50),
project_id INTEGER REFERENCES projects(project_id)
);
CREATE TABLE taskassignments (
assignment_id SERIAL PRIMARY KEY,
task_id INTEGER REFERENCES tasks(task_id),
user_id INTEGER REFERENCES users(user_id),
assigned_date DATE NOT NULL DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE comments (
comment_id SERIAL PRIMARY KEY,
content TEXT NOT NULL,
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
task_id INTEGER REFERENCES tasks(task_id),
user_id INTEGER REFERENCES users(user_id)
);
示例SQL輸出
問題:顯示用戶加入最多的日期
SELECT created_at::DATE AS day, COUNT(*) AS user_count
FROM users
GROUP BY day
ORDER BY user_count DESC
LIMIT 1;
問題:顯示擁有評論最多任務的項目
SELECT p.project_name, t.task_name, COUNT(c.comment_id) AS comment_count
FROM projects p
JOIN tasks t ON p.project_id = t.project_id
JOIN comments c ON t.task_id = c.task_id
GROUP BY p.project_name, t.task_name
ORDER BY comment_count DESC
LIMIT 1;
問題:擁有Gmail郵箱地址的用戶與沒有Gmail郵箱地址的用戶的比例是多少?
SELECT
SUM(CASE WHEN email ILIKE '%@gmail.com%' THEN 1 ELSE 0 END)::FLOAT / NULLIF(SUM(CASE WHEN email NOT ILIKE '%@gmail.com%' THEN 1 ELSE 0 END), 0) AS gmail_ratio
FROM
users;
📚 詳細文檔
基準測試
未訓練的新數據集上的結果(通過SQL - Eval)
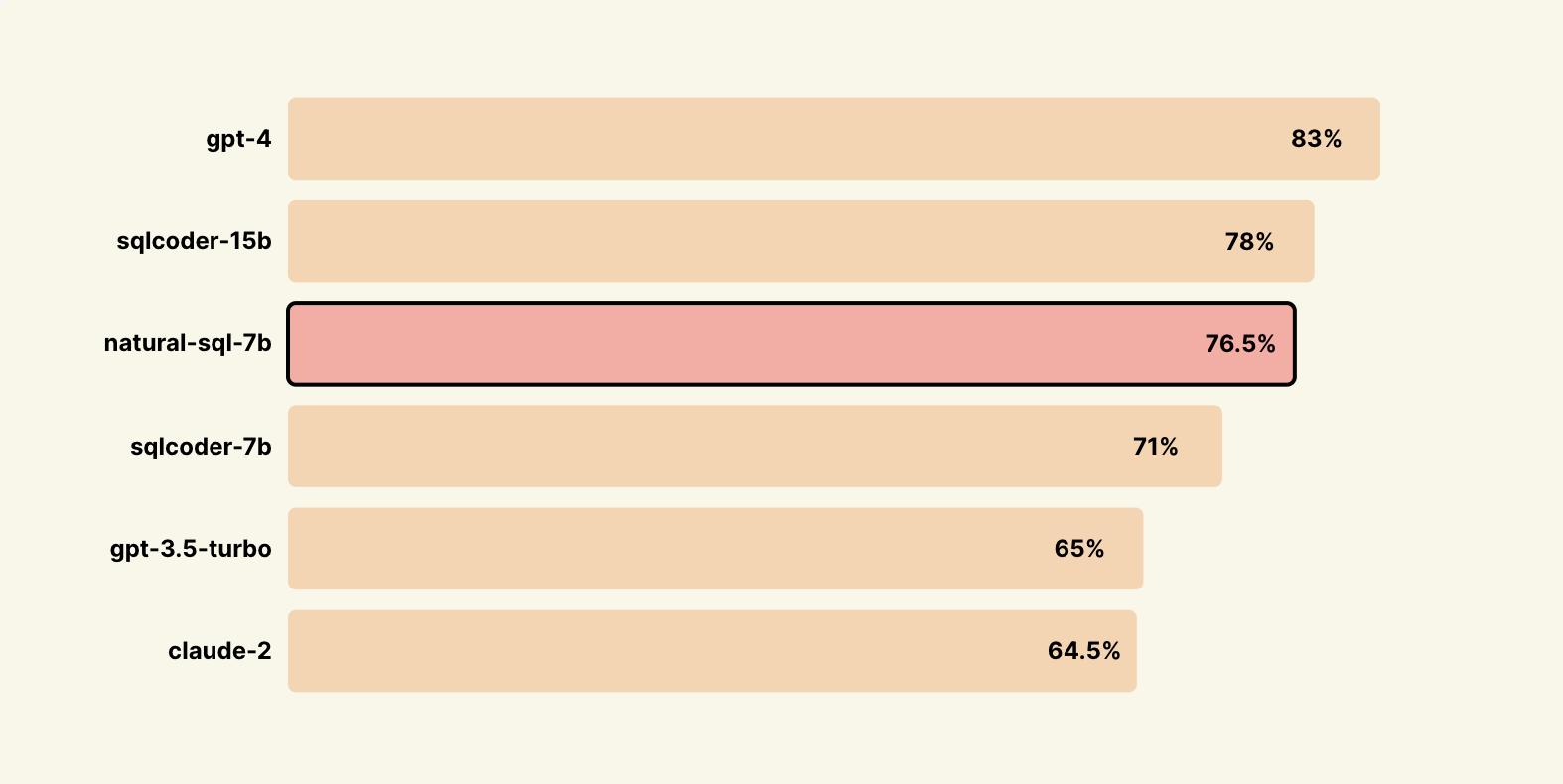
非常感謝defog團隊開源了sql - eval👏
Natural - SQL還可以處理其他模型通常難以應對的複雜複合問題。這裡有一個更詳細的報告,一個小測試在這裡。
📄 許可證
模型權重遵循CC BY - SA 4.0許可協議,並在原始模型Deepseek許可協議的基礎上擴展了負責任使用的額外指南。你可以自由使用和修改該模型,甚至用於商業目的。如果你修改了模型權重,例如通過微調,你必須在相同的CC BY - SA 4.0許可協議下公開分享你的更改。
📋 模型信息
| 屬性 |
詳情 |
| 基礎模型 |
deepseek - ai/deepseek - coder - 6.7b - instruct |
| 標籤 |
instruct、finetune |
| 庫名稱 |
transformers |
| 許可證 |
cc - by - sa - 4.0 |
| 任務類型 |
文本生成 |
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多種語言
Transformers 支持多種語言