🚀 ChatDBによるNatural - SQL - 7B
Natural - SQL - 7Bは、Text - to - SQL命令において非常に強力な性能を持つモデルです。複雑な質問に対する理解能力に優れ、同サイズのモデルを上回る性能を発揮します。

ChatDB.ai | Notebook | Twitter
🚀 クイックスタート
モデルのロード
まずは、transformersライブラリの正しいバージョンをインストールしましょう。
pip install transformers==4.35.2
次に、以下のPythonコードを使用してモデルをロードします。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("chatdb/natural-sql-7b")
model = AutoModelForCausalLM.from_pretrained(
"chatdb/natural-sql-7b",
device_map="auto",
torch_dtype=torch.float16,
)
SQLの生成
以下のコードを使用してSQLを生成できます。
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
generated_ids = model.generate(
**inputs,
num_return_sequences=1,
eos_token_id=100001,
pad_token_id=100001,
max_new_tokens=400,
do_sample=False,
num_beams=1,
)
outputs = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
print(outputs[0].split("```sql")[-1])
✨ 主な機能
Natural - SQLは、他のモデルが苦手とする複雑な複合質問も処理できます。詳細なレポートはこちらにあります。
📦 インストール
モデルを使用するには、transformersライブラリの正しいバージョンをインストールする必要があります。
pip install transformers==4.35.2
💻 使用例
基本的な使用法
モデルのロードとSQLの生成の基本的なコードは以下の通りです。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("chatdb/natural-sql-7b")
model = AutoModelForCausalLM.from_pretrained(
"chatdb/natural-sql-7b",
device_map="auto",
torch_dtype=torch.float16,
)
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
generated_ids = model.generate(
**inputs,
num_return_sequences=1,
eos_token_id=100001,
pad_token_id=100001,
max_new_tokens=400,
do_sample=False,
num_beams=1,
)
outputs = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
print(outputs[0].split("```sql")[-1])
📚 ドキュメント
プロンプトテンプレート
# タスク
次の質問に答えるSQLクエリを生成してください: `{自然言語の質問}`
### PostgreSQLデータベーススキーマ
クエリは以下のスキーマを持つデータベースで実行されます:
<SQLテーブルDDLステートメント>
# SQL
次の質問に答えるSQLクエリはこちらです: `{自然言語の質問}`
'''sql
例のSQL出力
例のスキーマ
CREATE TABLE users (
user_id SERIAL PRIMARY KEY,
username VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL,
password_hash TEXT NOT NULL,
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE projects (
project_id SERIAL PRIMARY KEY,
project_name VARCHAR(100) NOT NULL,
description TEXT,
start_date DATE,
end_date DATE,
owner_id INTEGER REFERENCES users(user_id)
);
CREATE TABLE tasks (
task_id SERIAL PRIMARY KEY,
task_name VARCHAR(100) NOT NULL,
description TEXT,
due_date DATE,
status VARCHAR(50),
project_id INTEGER REFERENCES projects(project_id)
);
CREATE TABLE taskassignments (
assignment_id SERIAL PRIMARY KEY,
task_id INTEGER REFERENCES tasks(task_id),
user_id INTEGER REFERENCES users(user_id),
assigned_date DATE NOT NULL DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE comments (
comment_id SERIAL PRIMARY KEY,
content TEXT NOT NULL,
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
task_id INTEGER REFERENCES tasks(task_id),
user_id INTEGER REFERENCES users(user_id)
);
例のSQL出力
質問: 最も多くのユーザーが登録した日を教えてください
SELECT created_at::DATE AS day, COUNT(*) AS user_count
FROM users
GROUP BY day
ORDER BY user_count DESC
LIMIT 1;
質問: 最も多くのコメントがあるタスクを持つプロジェクトを教えてください
SELECT p.project_name, t.task_name, COUNT(c.comment_id) AS comment_count
FROM projects p
JOIN tasks t ON p.project_id = t.project_id
JOIN comments c ON t.task_id = c.task_id
GROUP BY p.project_name, t.task_name
ORDER BY comment_count DESC
LIMIT 1;
質問: Gmailアドレスを持つユーザーと持たないユーザーの比率は何ですか?
SELECT
SUM(CASE WHEN email ILIKE '%@gmail.com%' THEN 1 ELSE 0 END)::FLOAT / NULLIF(SUM(CASE WHEN email NOT ILIKE '%@gmail.com%' THEN 1 ELSE 0 END), 0) AS gmail_ratio
FROM
users;
📄 ライセンス
モデルの重みはCC BY - SA 4.0ライセンスの下で提供されており、元のモデルのDeepseekライセンスから拡張された責任ある使用のガイドラインがあります。モデルを商用目的で使用したり、適応させることができます。重みを変更した場合、例えばファインチューニングを行った場合、同じCC BY - SA 4.0ライセンスの下で変更内容を公開する必要があります。
📊 ベンチマーク
SQL - Evalを通じた未学習の新しいデータセットでの結果
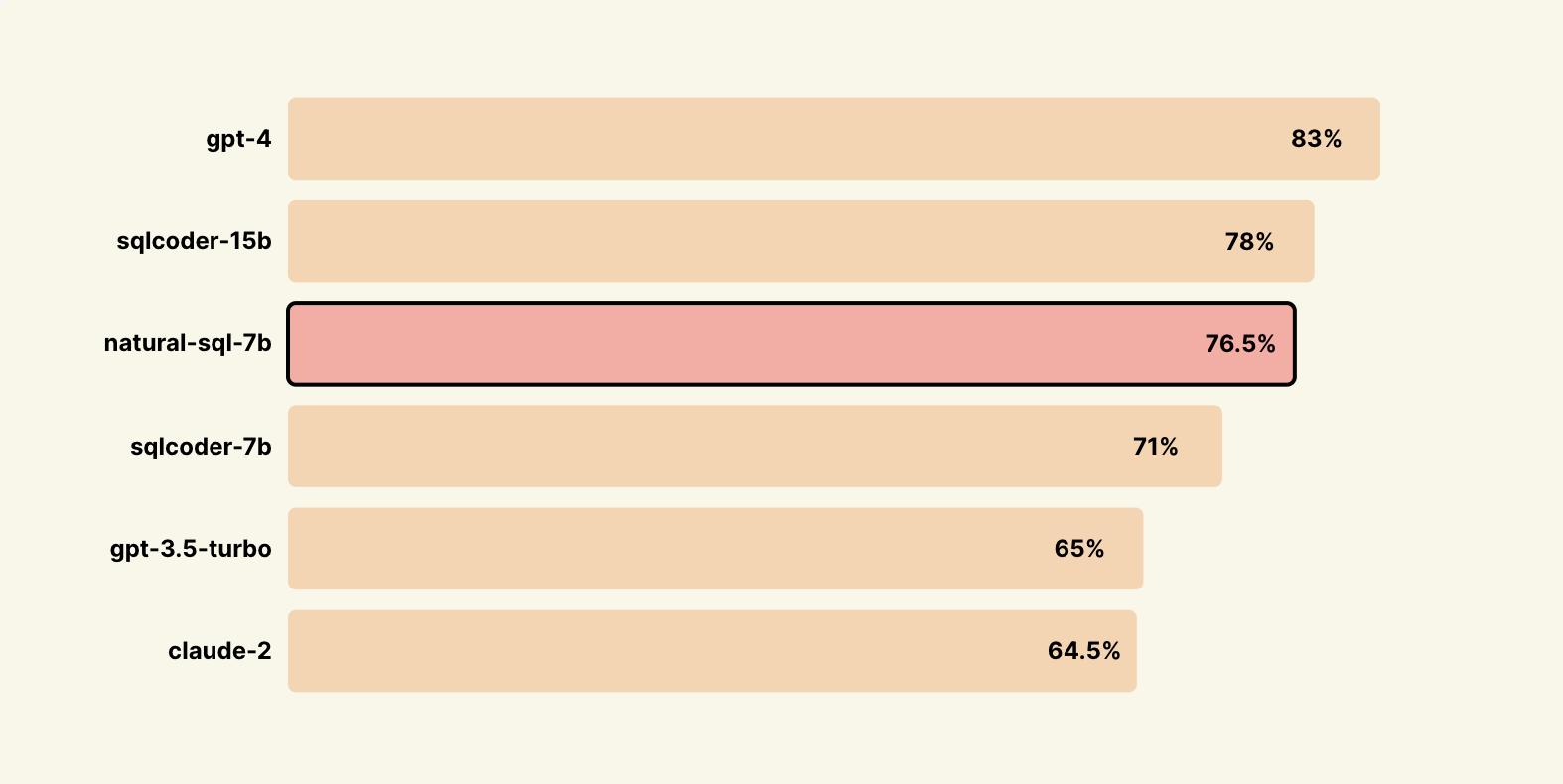
defogチームがsql - evalをオープンソース化してくれたことに大きな感謝を申し上げます👏
📋 モデル情報
| 属性 |
詳情 |
| モデルタイプ |
自然言語をSQLに変換するモデル |
| ベースモデル |
deepseek - ai/deepseek - coder - 6.7b - instruct |
| ライセンス |
CC BY - SA 4.0 |
| パイプラインタグ |
テキスト生成 |
| タグ |
instruct, finetune |
| ライブラリ名 |
transformers |
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応