🚀 T5-base在WikiSQL上微調
基於Google的T5模型,在WikiSQL數據集上微調,實現從英語到SQL的翻譯。
🚀 快速開始
本項目使用基於Google的 T5 模型,在 WikiSQL 數據集上進行微調,以實現從 英語 到 SQL 的 翻譯。
from transformers import AutoModelWithLMHead, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("mrm8488/t5-base-finetuned-wikiSQL")
model = AutoModelWithLMHead.from_pretrained("mrm8488/t5-base-finetuned-wikiSQL")
def get_sql(query):
input_text = "translate English to SQL: %s </s>" % query
features = tokenizer([input_text], return_tensors='pt')
output = model.generate(input_ids=features['input_ids'],
attention_mask=features['attention_mask'])
return tokenizer.decode(output[0])
query = "How many models were finetuned using BERT as base model?"
get_sql(query)
✨ 主要特性
- 基於強大的T5模型架構,在WikiSQL數據集上進行微調,實現英語到SQL的準確翻譯。
- 提供了詳細的數據集信息和模型微調的相關說明。
- 給出了模型的使用示例,方便用戶快速上手。
📚 詳細文檔
T5模型詳情
T5 模型由 Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li、Peter J. Liu 在論文 Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer 中提出。以下是論文摘要:
遷移學習是一種強大的自然語言處理(NLP)技術,它先在數據豐富的任務上對模型進行預訓練,然後在下游任務上進行微調。遷移學習的有效性催生了各種方法、方法論和實踐。在本文中,我們通過引入一個統一的框架,將每個語言問題轉化為文本到文本的格式,探索了NLP遷移學習技術的領域。我們的系統研究比較了預訓練目標、架構、無標籤數據集、遷移方法和其他因素在數十個語言理解任務上的表現。通過將我們的探索見解與規模和新的“Colossal Clean Crawled Corpus”相結合,我們在許多涵蓋摘要、問答、文本分類等的基準測試中取得了最先進的結果。為了促進未來NLP遷移學習的研究,我們發佈了我們的數據集、預訓練模型和代碼。

數據集詳情 📚
數據集ID:wikisql,來自 Huggingface/NLP
| 數據集 |
劃分 |
樣本數量 |
| wikisql |
訓練集 |
56355 |
| wikisql |
驗證集 |
14436 |
如何從 nlp 加載該數據集
train_dataset = nlp.load_dataset('wikisql', split=nlp.Split.TRAIN)
valid_dataset = nlp.load_dataset('wikisql', split=nlp.Split.VALIDATION)
在 NLP Viewer 中查看更多關於此數據集和其他數據集的信息。
模型微調 🏋️
訓練腳本是 Suraj Patil 創建的 Colab Notebook 的略微修改版本,所有功勞歸他!
模型應用示例 🚀
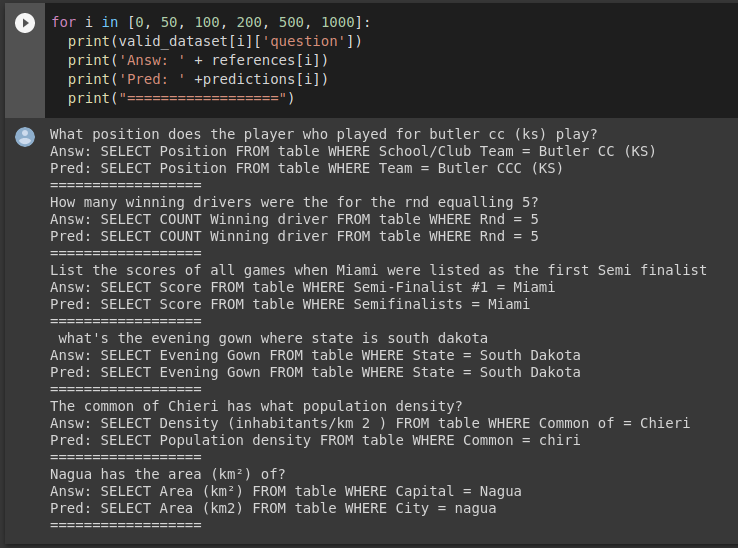
驗證數據集的其他示例:
由 Manuel Romero/@mrm8488 創建 | 領英
在西班牙用心打造 ♥
📄 許可證
本項目採用 Apache-2.0 許可證。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多種語言
Transformers 支持多種語言