🚀 T5-baseをWikiSQLでファインチューニング
GoogleのT5をWikiSQLでファインチューニングし、英語からSQLへの翻訳を行うモデルです。
🚀 クイックスタート
このモデルは、GoogleのT5をWikiSQLデータセットでファインチューニングして、英語からSQLへの翻訳を行うことができます。以下に使用例を示します。
from transformers import AutoModelWithLMHead, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("mrm8488/t5-base-finetuned-wikiSQL")
model = AutoModelWithLMHead.from_pretrained("mrm8488/t5-base-finetuned-wikiSQL")
def get_sql(query):
input_text = "translate English to SQL: %s </s>" % query
features = tokenizer([input_text], return_tensors='pt')
output = model.generate(input_ids=features['input_ids'],
attention_mask=features['attention_mask'])
return tokenizer.decode(output[0])
query = "How many models were finetuned using BERT as base model?"
get_sql(query)
✨ 主な機能
- GoogleのT5モデルをWikiSQLデータセットでファインチューニングし、英語からSQLへの翻訳を行うことができます。
📦 インストール
このモデルを使用するには、transformersライブラリが必要です。以下のコマンドでインストールできます。
pip install transformers
📚 ドキュメント
T5の詳細
T5モデルは、Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. LiuによるExploring the Limits of Transfer Learning with a Unified Text-to-Text Transformerで発表されました。以下はその概要です。
転移学習は、モデルがまずデータが豊富なタスクで事前学習され、その後下流のタスクでファインチューニングされる手法であり、自然言語処理(NLP)において強力な技術として浮上しています。転移学習の有効性により、様々なアプローチ、方法論、実践が生まれています。この論文では、すべての言語問題をテキストからテキストへの形式に変換する統一的なフレームワークを導入することで、NLPの転移学習技術の領域を探索します。我々の体系的な研究では、数十の言語理解タスクにおいて、事前学習の目的、アーキテクチャ、ラベルなしデータセット、転移アプローチ、その他の要素を比較します。我々の探索から得られた洞察と規模、そして新しい「Colossal Clean Crawled Corpus」を組み合わせることで、要約、質問応答、テキスト分類などの多くのベンチマークで最先端の結果を達成します。NLPの転移学習に関する将来の研究を促進するために、我々はデータセット、事前学習モデル、コードを公開します。

データセットの詳細 📚
データセットID: wikisql Huggingface/NLPから取得可能
| データセット |
分割 |
サンプル数 |
| wikisql |
トレーニング |
56355 |
| wikisql |
検証 |
14436 |
nlpからデータセットをロードする方法
train_dataset = nlp.load_dataset('wikisql', split=nlp.Split.TRAIN)
valid_dataset = nlp.load_dataset('wikisql', split=nlp.Split.VALIDATION)
このデータセットや他のデータセットの詳細については、NLP Viewerを参照してください。
モデルのファインチューニング 🏋️
トレーニングスクリプトは、Suraj Patilによって作成されたthis Colab Notebookを少し改変したものです。彼にすべての功績を捧げます!
モデルの動作例 🚀
上記の「クイックスタート」セクションを参照してください。
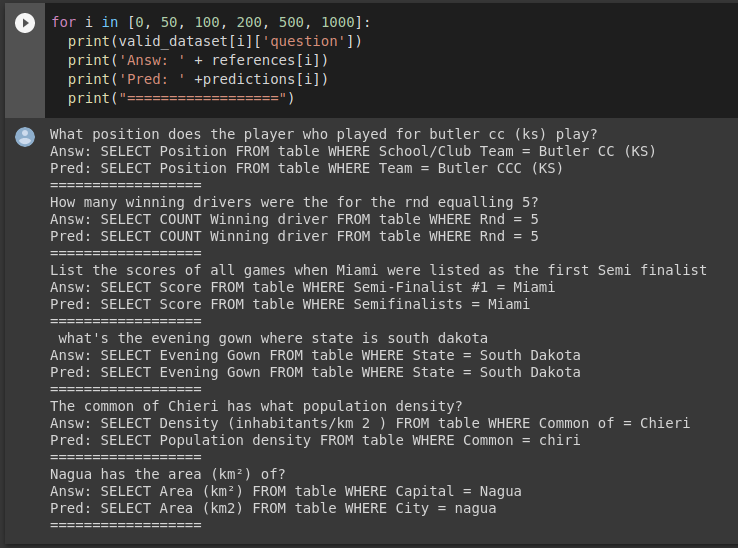
検証データセットの他の例
Created by Manuel Romero/@mrm8488 | LinkedIn
Made with ♥ in Spain
📄 ライセンス
このプロジェクトは、Apache License 2.0の下でライセンスされています。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応