%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
TW
Videoscore V1.1
模型概述
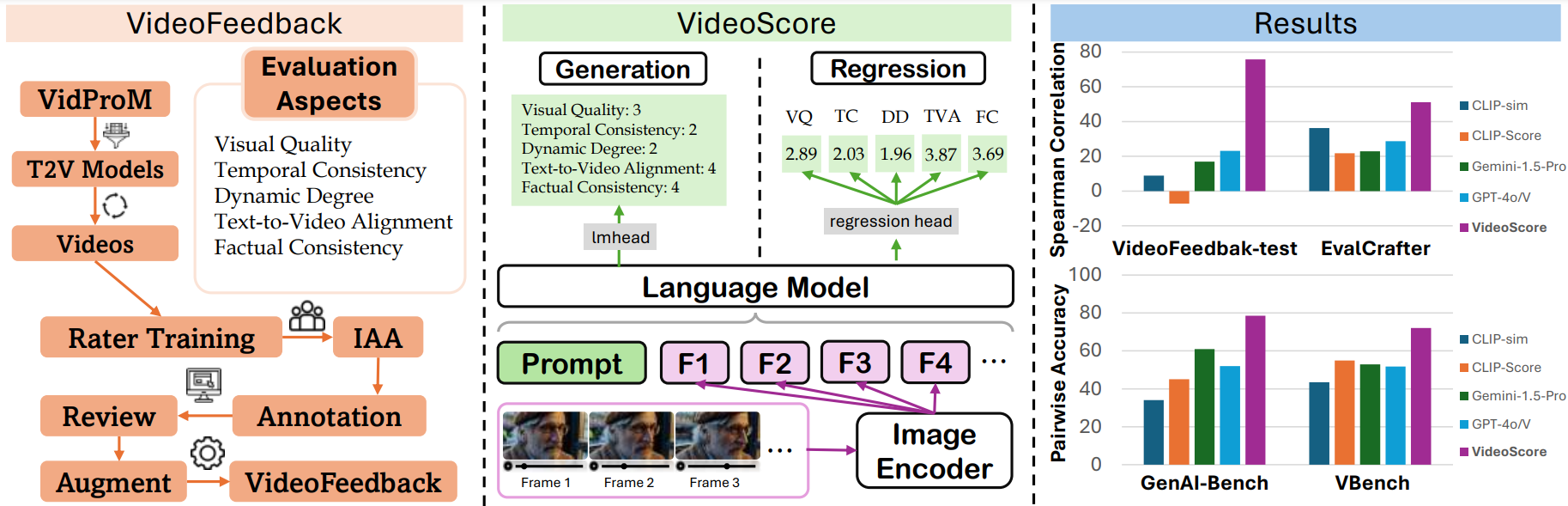
VideoScore系列是用於視頻質量評估的模型,能夠從多個維度評估AI生成視頻的質量,包括視覺質量、時間一致性、動態程度、文本到視頻對齊和事實一致性。
模型特點
多維度評估
能夠從視覺質量、時間一致性、動態程度、文本到視頻對齊和事實一致性五個維度評估視頻質量。
高幀數支持
支持處理48幀視頻,相比前代模型有顯著提升。
高性能
在VideoFeedback-test上達到74.0的Spearman相關性,超越GPT-4o等基線模型。
迴歸模型
直接輸出1.0-4.0的評分,而非分類結果。
模型能力
視頻質量評估
多維度評分
文本到視頻對齊分析
事實一致性檢查
使用案例
AI生成視頻評估
視頻生成模型評估
評估AI生成視頻的質量,為視頻生成模型提供反饋。
與人類評估高度一致,Spearman相關性達74.0
視頻內容審核
檢查生成視頻是否符合事實和常識。
在事實一致性維度提供可靠評分
視頻質量研究
視頻質量基準測試
為視頻質量研究提供標準化評估工具。
在GenAI-Bench和VBench上超越最佳基線
🚀 VideoScore-v1.1視頻質量評估模型
VideoScore-v1.1是一個視頻質量評估模型,以Mantis-8B-Idefics2為基礎模型,在大規模視頻評估數據集VideoFeedback上訓練得到。該模型能從多個維度對視頻質量進行評分,與人類評估高度一致,在多個基準測試中表現出色。
🚀 快速開始
你可以通過以下鏈接快速瞭解和使用VideoScore-v1.1:
✨ 主要特性
- 新版本優勢:嘗試使用新版本VideoScore-v1.1,它是VideoScore的變體,在“文本與視頻對齊”子分數方面表現更好,並且現在推理時支持48幀。它以Mantis-8B-Idefics2為基礎模型,在VideoFeedback數據集上進行訓練。
- 模型系列:VideoScore系列是視頻質量評估模型系列,以Mantis-8B-Idefics2或Qwen/Qwen2-VL為基礎模型,並在VideoFeedback(一個具有多方面人類評分的大型視頻評估數據集)上進行訓練。
- 評估表現:與VideoScore一樣,VideoScore-v1.1在VideoFeedback測試集上與人類評分的Spearman相關性約為75,超過了所有多模態大語言模型(MLLM)提示方法和基於特徵的指標。VideoScore-v1.1在另外兩個基準測試GenAI-Bench和VBench上也擊敗了最佳基線,顯示出與人類評估的高度一致性。有關這些基準測試的數據詳情,請參考VideoScore-Bench。
- 模型類型:VideoScore-v1.1是一個迴歸版本的模型。
📦 安裝指南
你可以使用以下命令安裝VideoScore:
pip install git+https://github.com/TIGER-AI-Lab/VideoScore.git
# 或者
# pip install mantis-vl
💻 使用示例
基礎用法
以下是一個使用VideoScore-v1.1進行推理的示例代碼:
import av
import numpy as np
from typing import List
from PIL import Image
import torch
from transformers import AutoProcessor
from mantis.models.idefics2 import Idefics2ForSequenceClassification
def _read_video_pyav(
frame_paths:List[str],
max_frames:int,
):
frames = []
container.seek(0)
start_index = indices[0]
end_index = indices[-1]
for i, frame in enumerate(container.decode(video=0)):
if i > end_index:
break
if i >= start_index and i in indices:
frames.append(frame)
return np.stack([x.to_ndarray(format="rgb24") for x in frames])
ROUND_DIGIT=3
REGRESSION_QUERY_PROMPT = """
Suppose you are an expert in judging and evaluating the quality of AI-generated videos,
please watch the following frames of a given video and see the text prompt for generating the video,
then give scores from 5 different dimensions:
(1) visual quality: the quality of the video in terms of clearness, resolution, brightness, and color
(2) temporal consistency, both the consistency of objects or humans and the smoothness of motion or movements
(3) dynamic degree, the degree of dynamic changes
(4) text-to-video alignment, the alignment between the text prompt and the video content
(5) factual consistency, the consistency of the video content with the common-sense and factual knowledge
for each dimension, output a float number from 1.0 to 4.0,
the higher the number is, the better the video performs in that sub-score,
the lowest 1.0 means Bad, the highest 4.0 means Perfect/Real (the video is like a real video)
Here is an output example:
visual quality: 3.2
temporal consistency: 2.7
dynamic degree: 4.0
text-to-video alignment: 2.3
factual consistency: 1.8
For this video, the text prompt is "{text_prompt}",
all the frames of video are as follows:
"""
# MAX_NUM_FRAMES=16
# model_name="TIGER-Lab/VideoScore"
# =======================================
# we support 48 frames in VideoScore-v1.1
# =======================================
MAX_NUM_FRAMES=48
model_name="TIGER-Lab/VideoScore-v1.1"
video_path="video1.mp4"
video_prompt="Near the Elephant Gate village, they approach the haunted house at night. Rajiv feels anxious, but Bhavesh encourages him. As they reach the house, a mysterious sound in the air adds to the suspense."
processor = AutoProcessor.from_pretrained(model_name,torch_dtype=torch.bfloat16)
model = Idefics2ForSequenceClassification.from_pretrained(model_name,torch_dtype=torch.bfloat16).eval()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# sample uniformly 8 frames from the video
container = av.open(video_path)
total_frames = container.streams.video[0].frames
if total_frames > MAX_NUM_FRAMES:
indices = np.arange(0, total_frames, total_frames / MAX_NUM_FRAMES).astype(int)
else:
indices = np.arange(total_frames)
frames = [Image.fromarray(x) for x in _read_video_pyav(container, indices)]
eval_prompt = REGRESSION_QUERY_PROMPT.format(text_prompt=video_prompt)
num_image_token = eval_prompt.count("<image>")
if num_image_token < len(frames):
eval_prompt += "<image> " * (len(frames) - num_image_token)
flatten_images = []
for x in [frames]:
if isinstance(x, list):
flatten_images.extend(x)
else:
flatten_images.append(x)
flatten_images = [Image.open(x) if isinstance(x, str) else x for x in flatten_images]
inputs = processor(text=eval_prompt, images=flatten_images, return_tensors="pt")
inputs = {k: v.to(model.device) for k, v in inputs.items()}
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
num_aspects = logits.shape[-1]
aspect_scores = []
for i in range(num_aspects):
aspect_scores.append(round(logits[0, i].item(),ROUND_DIGIT))
print(aspect_scores)
"""
model output on visual quality, temporal consistency, dynamic degree,
text-to-video alignment, factual consistency, respectively
VideoScore:
[2.297, 2.469, 2.906, 2.766, 2.516]
VideoScore-v1.1:
[2.328, 2.484, 2.562, 1.969, 2.594]
"""
訓練
有關訓練的詳細信息,請參考VideoScore/training。
評估
有關評估的詳細信息,請參考VideoScore/benchmark。
📚 詳細文檔
評估結果
我們在VideoFeedback測試集上對VideoScore-v1.1進行了測試,並將模型輸出與人類評分在所有評估方面的Spearman相關性平均值作為指標。評估結果如下:
| 指標 | VideoFeedback測試集 |
|---|---|
| VideoScore-v1.1 | 74.0 |
| Gemini-1.5-Pro | 22.1 |
| Gemini-1.5-Flash | 20.8 |
| GPT-4o | 23.1 |
| CLIP-sim | 8.9 |
| DINO-sim | 7.5 |
| SSIM-sim | 13.4 |
| CLIP-Score | -7.2 |
| LLaVA-1.5-7B | 8.5 |
| LLaVA-1.6-7B | -3.1 |
| X-CLIP-Score | -1.9 |
| PIQE | -10.1 |
| BRISQUE | -20.3 |
| Idefics2 | 6.5 |
| MSE-dyn | -5.5 |
| SSIM-dyn | -12.9 |
VideoScore系列中的最佳結果用粗體表示,基線中的最佳結果用下劃線表示。
📄 許可證
本項目採用MIT許可證。
📖 引用
如果你使用了該模型或相關代碼,請引用以下論文:
@article{he2024videoscore,
title = {VideoScore: Building Automatic Metrics to Simulate Fine-grained Human Feedback for Video Generation},
author = {He, Xuan and Jiang, Dongfu and Zhang, Ge and Ku, Max and Soni, Achint and Siu, Sherman and Chen, Haonan and Chandra, Abhranil and Jiang, Ziyan and Arulraj, Aaran and Wang, Kai and Do, Quy Duc and Ni, Yuansheng and Lyu, Bohan and Narsupalli, Yaswanth and Fan, Rongqi and Lyu, Zhiheng and Lin, Yuchen and Chen, Wenhu},
journal = {ArXiv},
year = {2024},
volume={abs/2406.15252},
url = {https://arxiv.org/abs/2406.15252},
}
Xclip Base Patch32
MIT
X-CLIP是CLIP的擴展版本,用於通用視頻語言理解,通過對比學習在(視頻,文本)對上訓練,適用於視頻分類和視頻-文本檢索等任務。
文本生成視頻 Transformers 英語
Transformers 英語
X
microsoft
309.80k
84
LTX Video
其他
首個基於DiT的視頻生成模型,能夠即時生成高質量視頻,支持文本轉視頻和圖像+文本轉視頻兩種場景。
文本生成視頻 英語
L
Lightricks
165.42k
1,174
Wan2.1 14B VACE GGUF
Apache-2.0
Wan2.1-VACE-14B模型的GGUF格式版本,主要用於文本到視頻的生成任務。
文本生成視頻
W
QuantStack
146.36k
139
Animatediff Lightning
Openrail
極速文本生成視頻模型,生成速度比原版AnimateDiff快十倍以上
文本生成視頻
A
ByteDance
144.00k
925
V Express
V-Express是一個基於音頻和麵部關鍵點條件生成的視頻生成模型,能夠將音頻輸入轉換為動態視頻輸出。
文本生成視頻 英語
V
tk93
118.36k
85
Cogvideox 5b
其他
CogVideoX是源自清影的視頻生成模型的開源版本,提供高質量的視頻生成能力。
文本生成視頻 英語
C
THUDM
92.32k
611
Llava NeXT Video 7B Hf
LLaVA-NeXT-Video是一個開源多模態聊天機器人,通過視頻和圖像數據混合訓練獲得優秀的視頻理解能力,在VideoMME基準上達到開源模型SOTA水平。
文本生成視頻 Transformers 英語
L
llava-hf
65.95k
88
Wan2.1 T2V 14B Diffusers
Apache-2.0
萬2.1是一套全面開放的視頻基礎模型,旨在突破視頻生成的邊界,支持中英文文本生成視頻、圖像生成視頻等多種任務。
文本生成視頻 支持多種語言
W
Wan-AI
48.65k
24
Wan2.1 T2V 1.3B Diffusers
Apache-2.0
萬2.1是一套全面開放的視頻基礎模型,具備頂尖性能、支持消費級GPU、多任務支持、視覺文本生成和高效視頻VAE等特點。
文本生成視頻 支持多種語言
W
Wan-AI
45.29k
38
Wan2.1 T2V 14B
Apache-2.0
萬2.1是一套綜合性開源視頻基礎模型,具備文本生成視頻、圖像生成視頻、視頻編輯、文本生成圖像及視頻生成音頻等多任務能力,支持中英雙語文本生成。
文本生成視頻 支持多種語言
W
Wan-AI
44.88k
1,238
精選推薦AI模型
Llama 3 Typhoon V1.5x 8b Instruct
專為泰語設計的80億參數指令模型,性能媲美GPT-3.5-turbo,優化了應用場景、檢索增強生成、受限生成和推理任務
大型語言模型 Transformers 支持多種語言
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-Tiny是一個基於SODA數據集訓練的超小型對話模型,專為邊緣設備推理設計,體積僅為Cosmo-3B模型的2%左右。
對話系統 Transformers 英語
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
基於RoBERTa架構的中文抽取式問答模型,適用於從給定文本中提取答案的任務。
問答系統 中文
R
uer
2,694
98