🚀 VideoScore-v1.1
VideoScore-v1.1は、ビデオ品質評価モデルで、多面的な人間の評価を持つ大規模ビデオ評価データセットで訓練され、人間の評価と高い一致性を示します。
📃論文 | 🌐ウェブサイト | 💻Github | 🛢️データセット | 🤗モデル (VideoScore) | 🤗デモ
🚀 クイックスタート
概要
✨ 主な機能
- ビデオ品質を多面的に評価する能力を備えています。
- 人間の評価と高い一致性を示し、多くのベースラインを上回っています。
- 推論時に48フレームのサポートを備えています。
📦 インストール
pip install git+https://github.com/TIGER-AI-Lab/VideoScore.git
# または
# pip install mantis-vl
💻 使用例
基本的な使用法
import av
import numpy as np
from typing import List
from PIL import Image
import torch
from transformers import AutoProcessor
from mantis.models.idefics2 import Idefics2ForSequenceClassification
def _read_video_pyav(
frame_paths:List[str],
max_frames:int,
):
frames = []
container.seek(0)
start_index = indices[0]
end_index = indices[-1]
for i, frame in enumerate(container.decode(video=0)):
if i > end_index:
break
if i >= start_index and i in indices:
frames.append(frame)
return np.stack([x.to_ndarray(format="rgb24") for x in frames])
ROUND_DIGIT=3
REGRESSION_QUERY_PROMPT = """
Suppose you are an expert in judging and evaluating the quality of AI-generated videos,
please watch the following frames of a given video and see the text prompt for generating the video,
then give scores from 5 different dimensions:
(1) visual quality: the quality of the video in terms of clearness, resolution, brightness, and color
(2) temporal consistency, both the consistency of objects or humans and the smoothness of motion or movements
(3) dynamic degree, the degree of dynamic changes
(4) text-to-video alignment, the alignment between the text prompt and the video content
(5) factual consistency, the consistency of the video content with the common-sense and factual knowledge
for each dimension, output a float number from 1.0 to 4.0,
the higher the number is, the better the video performs in that sub-score,
the lowest 1.0 means Bad, the highest 4.0 means Perfect/Real (the video is like a real video)
Here is an output example:
visual quality: 3.2
temporal consistency: 2.7
dynamic degree: 4.0
text-to-video alignment: 2.3
factual consistency: 1.8
For this video, the text prompt is "{text_prompt}",
all the frames of video are as follows:
"""
MAX_NUM_FRAMES=48
model_name="TIGER-Lab/VideoScore-v1.1"
video_path="video1.mp4"
video_prompt="Near the Elephant Gate village, they approach the haunted house at night. Rajiv feels anxious, but Bhavesh encourages him. As they reach the house, a mysterious sound in the air adds to the suspense."
processor = AutoProcessor.from_pretrained(model_name,torch_dtype=torch.bfloat16)
model = Idefics2ForSequenceClassification.from_pretrained(model_name,torch_dtype=torch.bfloat16).eval()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
container = av.open(video_path)
total_frames = container.streams.video[0].frames
if total_frames > MAX_NUM_FRAMES:
indices = np.arange(0, total_frames, total_frames / MAX_NUM_FRAMES).astype(int)
else:
indices = np.arange(total_frames)
frames = [Image.fromarray(x) for x in _read_video_pyav(container, indices)]
eval_prompt = REGRESSION_QUERY_PROMPT.format(text_prompt=video_prompt)
num_image_token = eval_prompt.count("<image>")
if num_image_token < len(frames):
eval_prompt += "<image> " * (len(frames) - num_image_token)
flatten_images = []
for x in [frames]:
if isinstance(x, list):
flatten_images.extend(x)
else:
flatten_images.append(x)
flatten_images = [Image.open(x) if isinstance(x, str) else x for x in flatten_images]
inputs = processor(text=eval_prompt, images=flatten_images, return_tensors="pt")
inputs = {k: v.to(model.device) for k, v in inputs.items()}
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
num_aspects = logits.shape[-1]
aspect_scores = []
for i in range(num_aspects):
aspect_scores.append(round(logits[0, i].item(),ROUND_DIGIT))
print(aspect_scores)
"""
model output on visual quality, temporal consistency, dynamic degree,
text-to-video alignment, factual consistency, respectively
VideoScore:
[2.297, 2.469, 2.906, 2.766, 2.516]
VideoScore-v1.1:
[2.328, 2.484, 2.562, 1.969, 2.594]
"""
高度な使用法
訓練
詳細についてはVideoScore/trainingを参照してください。
評価
詳細についてはVideoScore/benchmarkを参照してください。
📚 ドキュメント
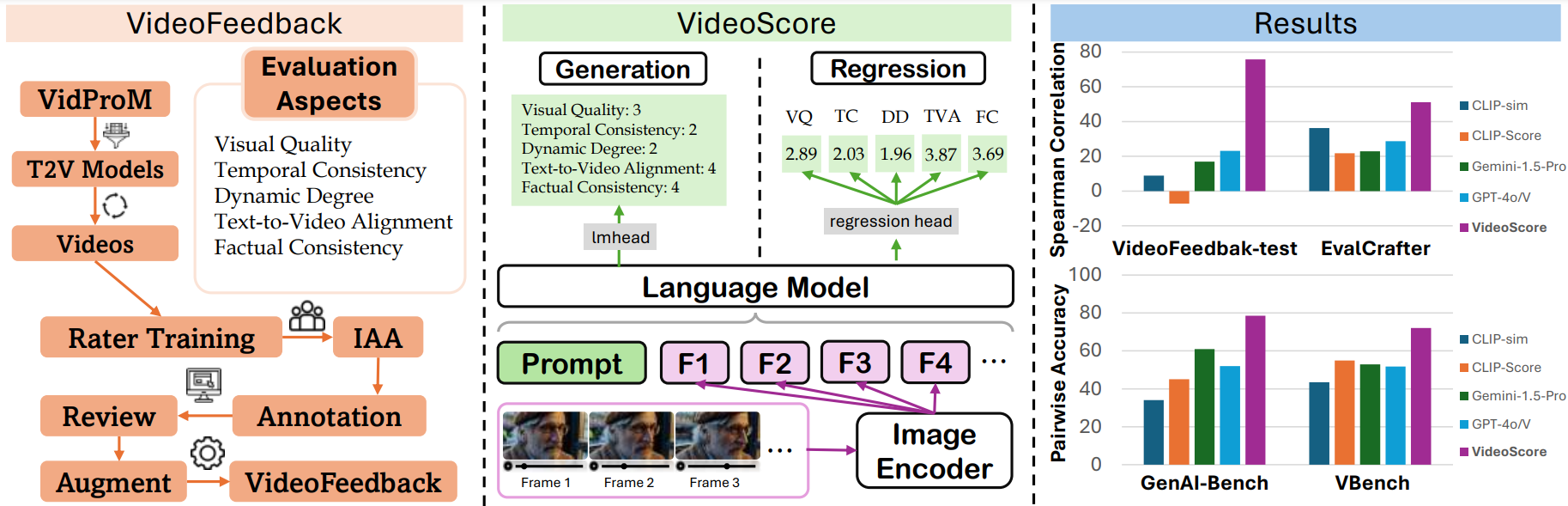
評価結果
VideoScore-v1.1をVideoFeedback-testでテストし、モデルの出力と人間の評価の間のスピアマン相関をすべての評価面で平均したものを指標としています。評価結果は以下の通りです。
| 指標 |
VideoFeedback-test |
| VideoScore-v1.1 |
74.0 |
| Gemini-1.5-Pro |
22.1 |
| Gemini-1.5-Flash |
20.8 |
| GPT-4o |
23.1 |
| CLIP-sim |
8.9 |
| DINO-sim |
7.5 |
| SSIM-sim |
13.4 |
| CLIP-Score |
-7.2 |
| LLaVA-1.5-7B |
8.5 |
| LLaVA-1.6-7B |
-3.1 |
| X-CLIP-Score |
-1.9 |
| PIQE |
-10.1 |
| BRISQUE |
-20.3 |
| Idefics2 |
6.5 |
| MSE-dyn |
-5.5 |
| SSIM-dyn |
-12.9 |
VideoScoreシリーズで最良の結果は太字で、ベースラインで最良の結果は下線付きで示されています。
📄 ライセンス
このプロジェクトはMITライセンスの下で公開されています。
引用
@article{he2024videoscore,
title = {VideoScore: Building Automatic Metrics to Simulate Fine-grained Human Feedback for Video Generation},
author = {He, Xuan and Jiang, Dongfu and Zhang, Ge and Ku, Max and Soni, Achint and Siu, Sherman and Chen, Haonan and Chandra, Abhranil and Jiang, Ziyan and Arulraj, Aaran and Wang, Kai and Do, Quy Duc and Ni, Yuansheng and Lyu, Bohan and Narsupalli, Yaswanth and Fan, Rongqi and Lyu, Zhiheng and Lin, Yuchen and Chen, Wenhu},
journal = {ArXiv},
year = {2024},
volume={abs/2406.15252},
url = {https://arxiv.org/abs/2406.15252},
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応