🚀 Poseless-3B
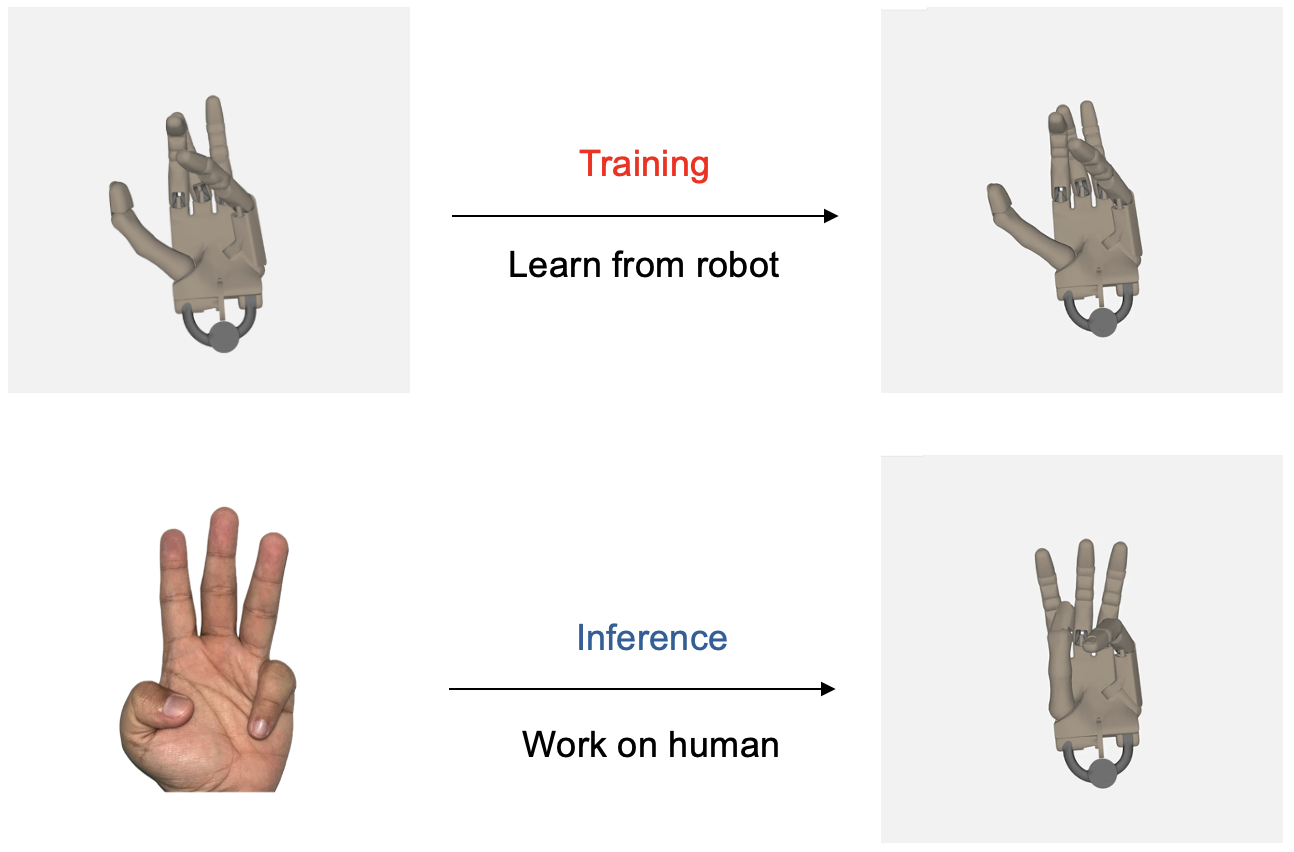
"PoseLess: Depth-Free Vision-to-Joint Control via Direct Image Mapping with VLM" 提出了一種全新的機器人手部控制框架,通過使用投影表示將2D圖像直接映射到關節角度,無需進行顯式的姿勢估計。該方法利用通過隨機關節配置生成的合成訓練數據,能夠在現實場景中實現零樣本泛化,並能從機器人手到人類手進行跨形態遷移。
🚀 快速開始
以下是使用該模型進行手部關節角度預測的示例代碼:
import torch
from PIL import Image
from transformers import AutoProcessor, Qwen2_5_VLForConditionalGeneration
from qwen_vl_utils import process_vision_info
device = "cuda" if torch.cuda.is_available() else "cpu"
model_path = "homebrewltd/Poseless-3B"
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
model_path,
trust_remote_code=True,
torch_dtype=torch.bfloat16
).eval().to(device)
processor = AutoProcessor.from_pretrained(
model_path,
min_pixels=256*28*28,
max_pixels=1280*28*28,
trust_remote_code=True
)
image = Image.open("your_hand_image.png").convert("RGB")
SYSTEM_PROMPT = """You are a specialized Vision Language Model designed to accurately estimate joint angles from hand pose images. Your task is to analyze images of a human or robotic hand and output precise angle measurements for each joint. Output joint angles in radians.
Output Format:
<lh_WRJ2>angle</lh_WRJ2><lh_WRJ1>angle</lh_WRJ1><lh_FFJ4>angle</lh_FFJ4><lh_FFJ3>angle</lh_FFJ3><lh_FFJ2>angle</lh_FFJ2><lh_FFJ1>angle</lh_FFJ1><lh_MFJ4>angle</lh_MFJ4><lh_MFJ3>angle</lh_MFJ3><lh_MFJ2>angle</lh_MFJ2><lh_MFJ1>angle</lh_MFJ1><lh_RFJ4>angle</lh_RFJ4><lh_RFJ3>angle</lh_RFJ3><lh_RFJ2>angle</lh_RFJ2><lh_RFJ1>angle</lh_RFJ1><lh_LFJ5>angle</lh_LFJ5><lh_LFJ4>angle</lh_LFJ4><lh_LFJ3>angle</lh_LFJ3><lh_LFJ2>angle</lh_LFJ2><lh_LFJ1>angle</lh_LFJ1><lh_THJ5>angle</lh_THJ5><lh_THJ4>angle</lh_THJ4><lh_THJ3>angle</lh_THJ3><lh_THJ2>angle</lh_THJ2><lh_THJ1>angle</lh_THJ1>
"""
messages = [
{"role": "system", "content": f"{SYSTEM_PROMPT}"},
{
"role": "user",
"content": [
{
"type": "image",
"image": image,
"min_pixels": 1003520,
"max_pixels": 1003520,
},
{"type": "text", "text": "<Pose>"},
],
},
]
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(text=[text], images=image_inputs, videos=video_inputs, padding=True, return_tensors="pt").to(device)
generated_ids = model.generate(**inputs, max_new_tokens=1024)
generated_ids_trimmed = [out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]
output_text = processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
print(output_text)
輸出將是以XML格式表示的弧度制關節角度:
<lh_WRJ2>angle</lh_WRJ2><lh_WRJ1>angle</lh_WRJ1><lh_FFJ4>angle</lh_FFJ4>...
✨ 主要特性
創新框架
利用VLM(如Qwen 2.5 3B Instruct)直接將單目圖像映射到機器人關節角度,完全繞過姿勢估計。VLM “觀察” 和投影圖像的能力實現了強大的、與形態無關的特徵提取,減少了兩階段管道中固有的誤差傳播。
合成數據管道
通過隨機化關節角度和對視覺特徵(如照明、紋理)進行領域隨機化,生成無限的訓練示例。這消除了對昂貴標記數據集的依賴,同時確保了對現實世界變化的魯棒性。
跨形態泛化
模型展示了跨形態泛化能力,即使僅在機器人手數據上進行訓練,也能模仿人類手部動作。這些發現為更廣泛的應用理解和利用這種泛化能力邁出了重要一步。
無深度控制
證明了無深度控制是可行的,為後續採用不支持深度估計能力的相機鋪平了道路,而這種相機在機器人研究中經常使用。
📚 詳細文檔
模型詳情
引用
更多信息
如需進一步瞭解詳情,請通過以下郵箱聯繫作者:alan@menlo.ai, bach@menlo.ai, charles@menlo.ai, yuuki@menlo.ai 。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors Transformers 支持多種語言
Transformers 支持多種語言