%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型概述
模型特點
模型能力
使用案例
🚀 Stable Diffusion v2-1-base模型卡片
Stable Diffusion v2-1-base是一款強大的基於文本生成圖像的模型,它在原有的基礎上進行了優化和調整,能夠根據文本提示更精準地生成和修改圖像,為圖像生成領域帶來了新的可能性。
🚀 快速開始
可以通過以下兩種方式使用stable-diffusion-2-1-base模型:
- 結合
stablediffusion倉庫使用:可從此處下載v2-1_512-ema-pruned.ckpt文件。 - 結合🧨
diffusers使用。
✨ 主要特性
- 文本驅動圖像生成:能夠根據輸入的文本提示生成相應的圖像。
- 模型微調優化:在
stable-diffusion-2-base基礎上進行了220k額外步驟的微調,提升了性能。 - 多場景應用:可用於藝術創作、教育工具、研究等多個領域。
📦 安裝指南
使用🤗的Diffusers庫可以簡單高效地運行Stable Diffusion 2,首先安裝必要的依賴:
pip install diffusers transformers accelerate scipy safetensors
💻 使用示例
基礎用法
運行以下代碼示例(如果不更換調度器,將使用默認的PNDM/PLMS調度器,本示例中更換為EulerDiscreteScheduler):
from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler
import torch
model_id = "stabilityai/stable-diffusion-2-1-base"
scheduler = EulerDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
高級用法
注意事項:
- 雖然不是必需依賴,但強烈建議安裝xformers以實現內存高效注意力(提升性能)。
- 如果GPU顯存較低,在將模型發送到
cuda後添加pipe.enable_attention_slicing()以減少顯存使用(但會降低速度)。
📚 詳細文檔
模型詳情
- 開發者:Robin Rombach, Patrick Esser
- 模型類型:基於擴散的文本到圖像生成模型
- 支持語言:英語
- 許可證:CreativeML Open RAIL++-M License
- 模型描述:這是一個可用於根據文本提示生成和修改圖像的模型,它是一個潛在擴散模型,使用固定的預訓練文本編碼器(OpenCLIP-ViT/H)。
- 更多信息資源:GitHub倉庫
- 引用格式:
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
使用場景
直接使用
該模型僅用於研究目的,可能的研究領域和任務包括:
- 安全部署有潛在生成有害內容風險的模型。
- 探究和理解生成模型的侷限性和偏差。
- 藝術品生成以及在設計和其他藝術過程中的應用。
- 教育或創意工具中的應用。
- 生成模型的研究。
禁止使用場景
模型不應被用於故意創建或傳播對人造成敵對或疏離環境的圖像,包括生成可能令人不安、痛苦或冒犯的圖像,或傳播歷史或當前刻板印象的內容。
- 超出範圍的使用:模型並非用於生成對人或事件的真實或準確表示,因此使用該模型生成此類內容超出了其能力範圍。
- 濫用和惡意使用:使用該模型生成對個人殘忍的內容屬於濫用,包括但不限於生成貶低、非人化或其他有害的人物、環境、文化、宗教等的表示;故意推廣或傳播歧視性內容或有害刻板印象;未經同意冒充個人;未經可能看到內容的人同意生成性內容;虛假和誤導性信息;嚴重暴力和血腥內容的表示;違反使用條款分享受版權或許可保護的材料;違反使用條款分享受版權或許可保護材料的修改版本。
侷限性和偏差
侷限性
- 模型無法實現完美的照片級真實感。
- 模型無法渲染清晰可讀的文本。
- 模型在涉及組合性的更復雜任務上表現不佳,例如渲染對應於“A red cube on top of a blue sphere”的圖像。
- 面部和人物的生成可能不夠理想。
- 模型主要使用英語字幕進行訓練,在其他語言中的表現不佳。
- 模型的自動編碼部分存在信息損失。
- 模型在大規模數據集LAION-5B的子集上進行訓練,該數據集包含成人、暴力和性內容。為部分緩解此問題,使用LAION的NFSW檢測器對數據集進行了過濾(見訓練部分)。
偏差
雖然圖像生成模型的能力令人印象深刻,但它們也可能強化或加劇社會偏差。Stable Diffusion v2主要在LAION-2B(en)的子集上進行訓練,該子集的圖像僅限於英語描述。使用其他語言的社區和文化的文本和圖像可能未得到充分考慮,這影響了模型的整體輸出,因為白人和西方文化通常被設定為默認。此外,模型使用非英語提示生成內容的能力明顯低於使用英語提示的情況。Stable Diffusion v2反映並加劇了偏差,無論輸入或意圖如何,都建議觀眾謹慎使用。
訓練
訓練數據
模型開發者使用以下數據集進行模型訓練:
- LAION-5B及其子集(詳情如下)。訓練數據使用LAION的NSFW檢測器進行了進一步過濾,“p_unsafe”分數為0.1(保守)。更多詳情,請參考LAION-5B的NeurIPS 2022論文和相關評審討論。
訓練過程
Stable Diffusion v2是一個潛在擴散模型,它將自動編碼器與在自動編碼器潛在空間中訓練的擴散模型相結合。訓練過程如下:
- 圖像通過編碼器編碼為潛在表示,自動編碼器使用相對下采樣因子8,將形狀為H x W x 3的圖像轉換為形狀為H/f x W/f x 4的潛在表示。
- 文本提示通過OpenCLIP-ViT/H文本編碼器進行編碼。
- 文本編碼器的輸出通過交叉注意力輸入到潛在擴散模型的UNet主幹中。
- 損失是添加到潛在表示的噪聲與UNet預測之間的重建目標,還使用了所謂的“v-objective”,詳見https://arxiv.org/abs/2202.00512。
目前為不同版本提供了以下檢查點:
- 版本2.1:
512-base-ema.ckpt:在512-base-ema.ckpt2.0基礎上進行220k額外步驟的微調,在相同數據集上punsafe=0.98。768-v-ema.ckpt:從768-v-ema.ckpt2.0恢復訓練,在相同數據集上額外進行55k步驟(punsafe=0.1),然後再進行155k額外步驟的微調,punsafe=0.98。
- 版本2.0:
512-base-ema.ckpt:在LAION-5B的一個子集上以256x256分辨率訓練550k步驟,該子集使用LAION-NSFW分類器過濾了明確的色情內容,punsafe=0.1且美學分數 >=4.5;在相同數據集上以512x512分辨率訓練850k步驟。768-v-ema.ckpt:從512-base-ema.ckpt恢復訓練,在相同數據集上使用v-objective訓練150k步驟;在數據集的768x768子集上再訓練140k步驟。512-depth-ema.ckpt:從512-base-ema.ckpt恢復訓練並微調200k步驟,添加一個額外的輸入通道來處理MiDaS (dpt_hybrid)產生的(相對)深度預測,作為額外的條件。處理此額外信息的U-Net額外輸入通道初始化為零。512-inpainting-ema.ckpt:從512-base-ema.ckpt恢復訓練並訓練200k步驟,遵循LAMA中提出的掩碼生成策略,結合掩碼圖像的潛在VAE表示作為額外條件。處理此額外信息的U-Net額外輸入通道初始化為零,與訓練1.5-inpainting檢查點使用的策略相同。x4-upscaling-ema.ckpt:在包含>2048x2048圖像的LAION 10M子集上訓練1250k步驟,模型在512x512大小的裁剪圖像上訓練,是一個文本引導的潛在上採樣擴散模型。除了文本輸入外,它還接收一個noise_level作為輸入參數,可根據預定義的擴散調度向低分辨率輸入添加噪聲。
訓練硬件:32 x 8 x A100 GPUs 優化器:AdamW 梯度累積:1 批次大小:32 x 8 x 2 x 4 = 2048 學習率:在10000步內預熱到0.0001,然後保持不變
評估結果
使用不同的無分類器引導尺度(1.5、2.0、3.0、4.0、5.0、6.0、7.0、8.0)和50步DDIM採樣步驟進行評估,結果顯示了檢查點的相對改進:
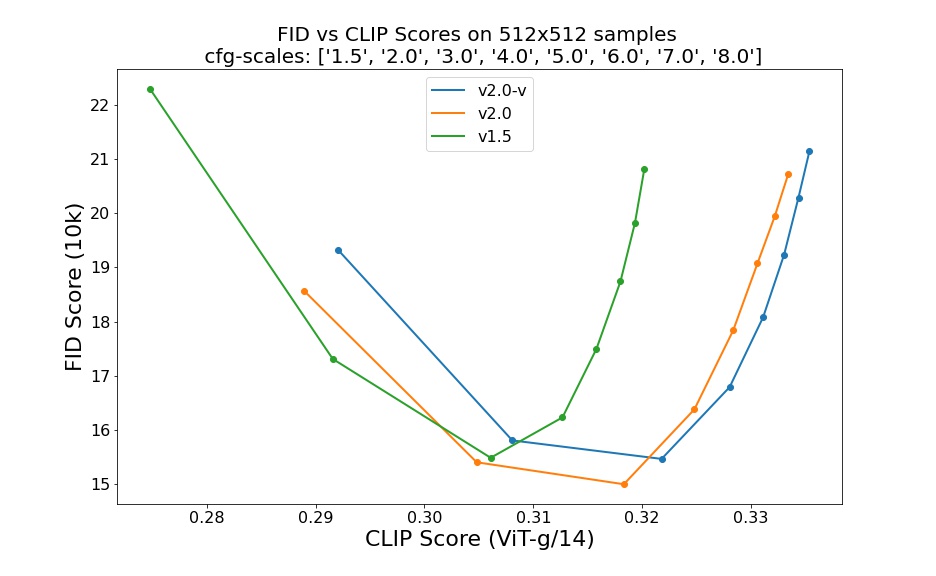
評估使用50步DDIM和來自COCO2017驗證集的10000個隨機提示,在512x512分辨率下進行,未針對FID分數進行優化。
環境影響
基於Lacoste等人(2019)提出的機器學習影響計算器,估計Stable Diffusion v1的二氧化碳排放量如下:
- 硬件類型:A100 PCIe 40GB
- 使用時長:200000小時
- 雲服務提供商:AWS
- 計算區域:美國東部
- 碳排放:(功耗 x 時間 x 基於電網位置產生的碳排放量)15000 kg CO2 eq.
📄 許可證
本模型遵循CreativeML Open RAIL++-M License。
本模型卡片由Robin Rombach、Patrick Esser和David Ha編寫,基於Stable Diffusion v1和DALL-E Mini模型卡片。