%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型简介
模型特点
模型能力
使用案例
🚀 Stable Diffusion v2-1-base模型卡片
Stable Diffusion v2-1-base是一款强大的基于文本生成图像的模型,它在原有的基础上进行了优化和调整,能够根据文本提示更精准地生成和修改图像,为图像生成领域带来了新的可能性。
🚀 快速开始
可以通过以下两种方式使用stable-diffusion-2-1-base模型:
- 结合
stablediffusion仓库使用:可从此处下载v2-1_512-ema-pruned.ckpt文件。 - 结合🧨
diffusers使用。
✨ 主要特性
- 文本驱动图像生成:能够根据输入的文本提示生成相应的图像。
- 模型微调优化:在
stable-diffusion-2-base基础上进行了220k额外步骤的微调,提升了性能。 - 多场景应用:可用于艺术创作、教育工具、研究等多个领域。
📦 安装指南
使用🤗的Diffusers库可以简单高效地运行Stable Diffusion 2,首先安装必要的依赖:
pip install diffusers transformers accelerate scipy safetensors
💻 使用示例
基础用法
运行以下代码示例(如果不更换调度器,将使用默认的PNDM/PLMS调度器,本示例中更换为EulerDiscreteScheduler):
from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler
import torch
model_id = "stabilityai/stable-diffusion-2-1-base"
scheduler = EulerDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
高级用法
注意事项:
- 虽然不是必需依赖,但强烈建议安装xformers以实现内存高效注意力(提升性能)。
- 如果GPU显存较低,在将模型发送到
cuda后添加pipe.enable_attention_slicing()以减少显存使用(但会降低速度)。
📚 详细文档
模型详情
- 开发者:Robin Rombach, Patrick Esser
- 模型类型:基于扩散的文本到图像生成模型
- 支持语言:英语
- 许可证:CreativeML Open RAIL++-M License
- 模型描述:这是一个可用于根据文本提示生成和修改图像的模型,它是一个潜在扩散模型,使用固定的预训练文本编码器(OpenCLIP-ViT/H)。
- 更多信息资源:GitHub仓库
- 引用格式:
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
使用场景
直接使用
该模型仅用于研究目的,可能的研究领域和任务包括:
- 安全部署有潜在生成有害内容风险的模型。
- 探究和理解生成模型的局限性和偏差。
- 艺术品生成以及在设计和其他艺术过程中的应用。
- 教育或创意工具中的应用。
- 生成模型的研究。
禁止使用场景
模型不应被用于故意创建或传播对人造成敌对或疏离环境的图像,包括生成可能令人不安、痛苦或冒犯的图像,或传播历史或当前刻板印象的内容。
- 超出范围的使用:模型并非用于生成对人或事件的真实或准确表示,因此使用该模型生成此类内容超出了其能力范围。
- 滥用和恶意使用:使用该模型生成对个人残忍的内容属于滥用,包括但不限于生成贬低、非人化或其他有害的人物、环境、文化、宗教等的表示;故意推广或传播歧视性内容或有害刻板印象;未经同意冒充个人;未经可能看到内容的人同意生成性内容;虚假和误导性信息;严重暴力和血腥内容的表示;违反使用条款分享受版权或许可保护的材料;违反使用条款分享受版权或许可保护材料的修改版本。
局限性和偏差
局限性
- 模型无法实现完美的照片级真实感。
- 模型无法渲染清晰可读的文本。
- 模型在涉及组合性的更复杂任务上表现不佳,例如渲染对应于“A red cube on top of a blue sphere”的图像。
- 面部和人物的生成可能不够理想。
- 模型主要使用英语字幕进行训练,在其他语言中的表现不佳。
- 模型的自动编码部分存在信息损失。
- 模型在大规模数据集LAION-5B的子集上进行训练,该数据集包含成人、暴力和性内容。为部分缓解此问题,使用LAION的NFSW检测器对数据集进行了过滤(见训练部分)。
偏差
虽然图像生成模型的能力令人印象深刻,但它们也可能强化或加剧社会偏差。Stable Diffusion v2主要在LAION-2B(en)的子集上进行训练,该子集的图像仅限于英语描述。使用其他语言的社区和文化的文本和图像可能未得到充分考虑,这影响了模型的整体输出,因为白人和西方文化通常被设定为默认。此外,模型使用非英语提示生成内容的能力明显低于使用英语提示的情况。Stable Diffusion v2反映并加剧了偏差,无论输入或意图如何,都建议观众谨慎使用。
训练
训练数据
模型开发者使用以下数据集进行模型训练:
- LAION-5B及其子集(详情如下)。训练数据使用LAION的NSFW检测器进行了进一步过滤,“p_unsafe”分数为0.1(保守)。更多详情,请参考LAION-5B的NeurIPS 2022论文和相关评审讨论。
训练过程
Stable Diffusion v2是一个潜在扩散模型,它将自动编码器与在自动编码器潜在空间中训练的扩散模型相结合。训练过程如下:
- 图像通过编码器编码为潜在表示,自动编码器使用相对下采样因子8,将形状为H x W x 3的图像转换为形状为H/f x W/f x 4的潜在表示。
- 文本提示通过OpenCLIP-ViT/H文本编码器进行编码。
- 文本编码器的输出通过交叉注意力输入到潜在扩散模型的UNet主干中。
- 损失是添加到潜在表示的噪声与UNet预测之间的重建目标,还使用了所谓的“v-objective”,详见https://arxiv.org/abs/2202.00512。
目前为不同版本提供了以下检查点:
- 版本2.1:
512-base-ema.ckpt:在512-base-ema.ckpt2.0基础上进行220k额外步骤的微调,在相同数据集上punsafe=0.98。768-v-ema.ckpt:从768-v-ema.ckpt2.0恢复训练,在相同数据集上额外进行55k步骤(punsafe=0.1),然后再进行155k额外步骤的微调,punsafe=0.98。
- 版本2.0:
512-base-ema.ckpt:在LAION-5B的一个子集上以256x256分辨率训练550k步骤,该子集使用LAION-NSFW分类器过滤了明确的色情内容,punsafe=0.1且美学分数 >=4.5;在相同数据集上以512x512分辨率训练850k步骤。768-v-ema.ckpt:从512-base-ema.ckpt恢复训练,在相同数据集上使用v-objective训练150k步骤;在数据集的768x768子集上再训练140k步骤。512-depth-ema.ckpt:从512-base-ema.ckpt恢复训练并微调200k步骤,添加一个额外的输入通道来处理MiDaS (dpt_hybrid)产生的(相对)深度预测,作为额外的条件。处理此额外信息的U-Net额外输入通道初始化为零。512-inpainting-ema.ckpt:从512-base-ema.ckpt恢复训练并训练200k步骤,遵循LAMA中提出的掩码生成策略,结合掩码图像的潜在VAE表示作为额外条件。处理此额外信息的U-Net额外输入通道初始化为零,与训练1.5-inpainting检查点使用的策略相同。x4-upscaling-ema.ckpt:在包含>2048x2048图像的LAION 10M子集上训练1250k步骤,模型在512x512大小的裁剪图像上训练,是一个文本引导的潜在上采样扩散模型。除了文本输入外,它还接收一个noise_level作为输入参数,可根据预定义的扩散调度向低分辨率输入添加噪声。
训练硬件:32 x 8 x A100 GPUs 优化器:AdamW 梯度累积:1 批次大小:32 x 8 x 2 x 4 = 2048 学习率:在10000步内预热到0.0001,然后保持不变
评估结果
使用不同的无分类器引导尺度(1.5、2.0、3.0、4.0、5.0、6.0、7.0、8.0)和50步DDIM采样步骤进行评估,结果显示了检查点的相对改进:
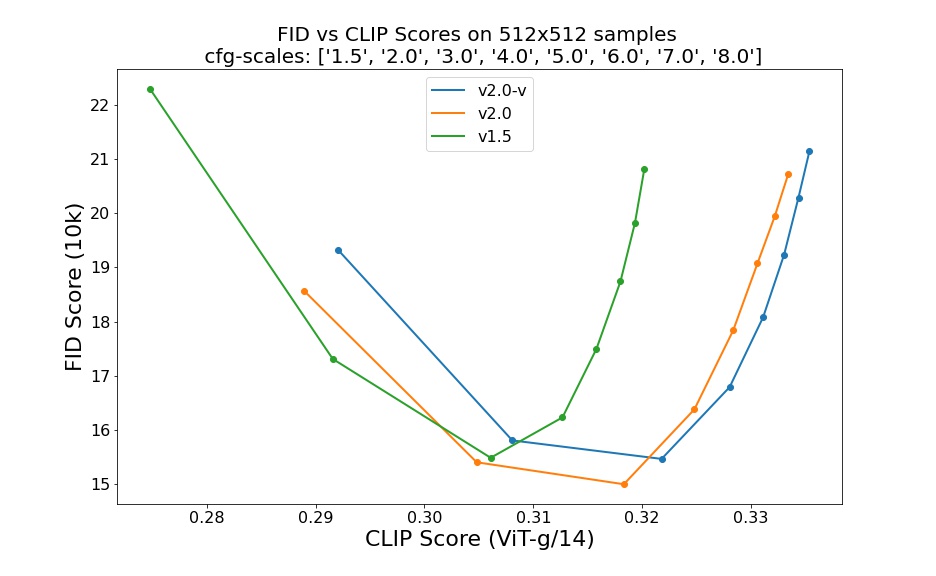
评估使用50步DDIM和来自COCO2017验证集的10000个随机提示,在512x512分辨率下进行,未针对FID分数进行优化。
环境影响
基于Lacoste等人(2019)提出的机器学习影响计算器,估计Stable Diffusion v1的二氧化碳排放量如下:
- 硬件类型:A100 PCIe 40GB
- 使用时长:200000小时
- 云服务提供商:AWS
- 计算区域:美国东部
- 碳排放:(功耗 x 时间 x 基于电网位置产生的碳排放量)15000 kg CO2 eq.
📄 许可证
本模型遵循CreativeML Open RAIL++-M License。
本模型卡片由Robin Rombach、Patrick Esser和David Ha编写,基于Stable Diffusion v1和DALL-E Mini模型卡片。