🚀 Kandinsky 2.2
Kandinsky繼承了Dall - E 2和潛在擴散模型的最佳實踐,同時引入了一些新的理念。它使用CLIP模型作為文本和圖像編碼器,並在CLIP模態的潛在空間之間進行擴散圖像先驗(映射)。這種方法提升了模型的視覺表現,為圖像融合和文本引導的圖像操作開闢了新的可能性。
該Kandinsky模型由Arseniy Shakhmatov、Anton Razzhigaev、Aleksandr Nikolich、Igor Pavlov、Andrey Kuznetsov和Denis Dimitrov創建。
🚀 快速開始
Kandinsky 2.2可在diffusers中使用!
pip install diffusers transformers accelerate
✨ 主要特性
Kandinsky 2.2是一個基於unCLIP和潛在擴散的文本條件擴散模型,由基於Transformer的圖像先驗模型、Unet擴散模型和解碼器組成。它使用CLIP模型作為文本和圖像編碼器,並在CLIP模態的潛在空間之間進行擴散圖像先驗(映射),提升了模型的視覺表現,為圖像融合和文本引導的圖像操作開闢了新的可能性。
💻 使用示例
基礎用法
文本到圖像
from diffusers import AutoPipelineForText2Image
import torch
pipe = AutoPipelineForText2Image.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "portrait of a young women, blue eyes, cinematic"
negative_prompt = "low quality, bad quality"
image = pipe(prompt=prompt, negative_prompt=negative_prompt, prior_guidance_scale =1.0, height=768, width=768).images[0]
image.save("portrait.png")

高級用法
文本引導的圖像到圖像生成
from PIL import Image
import requests
from io import BytesIO
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
response = requests.get(url)
original_image = Image.open(BytesIO(response.content)).convert("RGB")
original_image = original_image.resize((768, 512))

from diffusers import AutoPipelineForImage2Image
import torch
pipe = AutoPipelineForImage2Image.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16)
pipe.enable_model_cpu_offload()
prompt = "A fantasy landscape, Cinematic lighting"
negative_prompt = "low quality, bad quality"
image = pipe(prompt=prompt, image=original_image, strength=0.3, height=768, width=768).images[0]
out.images[0].save("fantasy_land.png")

圖像插值
from diffusers import KandinskyV22PriorPipeline, KandinskyV22Pipeline
from diffusers.utils import load_image
import PIL
import torch
pipe_prior = KandinskyV22PriorPipeline.from_pretrained(
"kandinsky-community/kandinsky-2-2-prior", torch_dtype=torch.float16
)
pipe_prior.to("cuda")
img1 = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/cat.png"
)
img2 = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/starry_night.jpeg"
)
images_texts = ["a cat", img1, img2]
weights = [0.3, 0.3, 0.4]
prompt = ""
prior_out = pipe_prior.interpolate(images_texts, weights)
pipe = KandinskyV22Pipeline.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16)
pipe.to("cuda")
image = pipe(**prior_out, height=768, width=768).images[0]
image.save("starry_cat.png")

📚 詳細文檔
模型架構概述
Kandinsky 2.2是一個基於unCLIP和潛在擴散的文本條件擴散模型,由基於Transformer的圖像先驗模型、Unet擴散模型和解碼器組成。
模型架構如下圖所示 - 左側的圖表描述了訓練圖像先驗模型的過程,中間的圖是文本到圖像的生成過程,右側的圖是圖像插值。
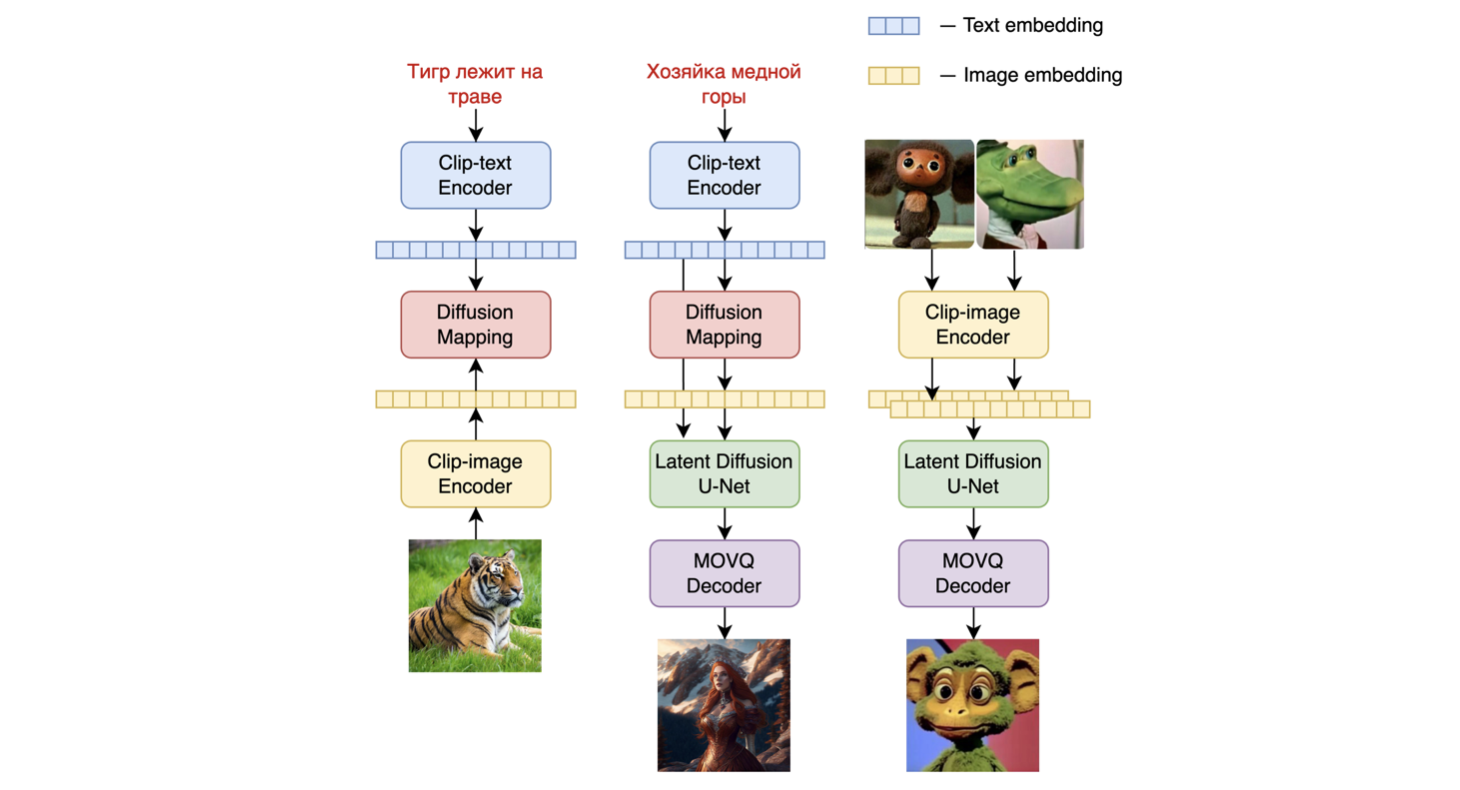
具體而言,圖像先驗模型是在使用預訓練的CLIP - ViT - G模型生成的CLIP文本和圖像嵌入上進行訓練的。訓練好的圖像先驗模型隨後用於為輸入的文本提示生成CLIP圖像嵌入。輸入的文本提示及其CLIP圖像嵌入都將用於擴散過程。MoVQGAN模型作為模型的最後一部分,將潛在表示解碼為實際圖像。
模型訓練細節
該模型的圖像先驗訓練是在LAION Improved Aesthetics數據集上進行的,然後在LAION HighRes數據上進行微調。
主要的文本到圖像擴散模型是在LAION HighRes數據集上進行訓練的,然後使用從開放源單獨收集的包含200萬個非常高質量高分辨率圖像及其描述的數據集(COYO、動漫、俄羅斯地標等)進行微調。
Kandinsky 2.2的主要變化是替換了CLIP - ViT - G。其圖像編碼器顯著提高了模型生成更具美感圖片和更好理解文本的能力,從而提升了其整體性能。
由於更換了CLIP模型,圖像先驗模型進行了重新訓練,文本到圖像擴散模型進行了2000次迭代的微調。Kandinsky 2.2在各種分辨率(從512 x 512到1536 x 1536)以及不同寬高比的數據上進行了訓練。因此,Kandinsky 2.2可以生成任意寬高比的1024 x 1024輸出。
模型評估
我們在COCO_30k數據集上以零樣本模式對Kandinsky 2.1的性能進行了定量測量。下表展示了FID值。
生成模型在COCO_30k上的FID指標值
| 模型 |
FID (30k) |
| eDiff - I (2022) |
6.95 |
| Image (2022) |
7.27 |
| Kandinsky 2.1 (2023) |
8.21 |
| Stable Diffusion 2.1 (2022) |
8.59 |
| GigaGAN, 512x512 (2023) |
9.09 |
| DALL - E 2 (2022) |
10.39 |
| GLIDE (2022) |
12.24 |
| Kandinsky 1.0 (2022) |
15.40 |
| DALL - E (2021) |
17.89 |
| Kandinsky 2.0 (2022) |
20.00 |
| GLIGEN (2022) |
21.04 |
更多信息,請參考即將發佈的技術報告。
📄 許可證
本項目採用Apache - 2.0許可證。
BibTex
如果您在研究中發現此倉庫有用,請引用:
@misc{kandinsky 2.2,
title = {kandinsky 2.2},
author = {Arseniy Shakhmatov, Anton Razzhigaev, Aleksandr Nikolich, Vladimir Arkhipkin, Igor Pavlov, Andrey Kuznetsov, Denis Dimitrov},
year = {2023},
howpublished = {},
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors Transformers 支持多種語言
Transformers 支持多種語言