🚀 Kandinsky 2.2
Kandinsky继承了Dall - E 2和潜在扩散模型的最佳实践,同时引入了一些新的理念。它使用CLIP模型作为文本和图像编码器,并在CLIP模态的潜在空间之间进行扩散图像先验(映射)。这种方法提升了模型的视觉表现,为图像融合和文本引导的图像操作开辟了新的可能性。
该Kandinsky模型由Arseniy Shakhmatov、Anton Razzhigaev、Aleksandr Nikolich、Igor Pavlov、Andrey Kuznetsov和Denis Dimitrov创建。
🚀 快速开始
Kandinsky 2.2可在diffusers中使用!
pip install diffusers transformers accelerate
✨ 主要特性
Kandinsky 2.2是一个基于unCLIP和潜在扩散的文本条件扩散模型,由基于Transformer的图像先验模型、Unet扩散模型和解码器组成。它使用CLIP模型作为文本和图像编码器,并在CLIP模态的潜在空间之间进行扩散图像先验(映射),提升了模型的视觉表现,为图像融合和文本引导的图像操作开辟了新的可能性。
💻 使用示例
基础用法
文本到图像
from diffusers import AutoPipelineForText2Image
import torch
pipe = AutoPipelineForText2Image.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "portrait of a young women, blue eyes, cinematic"
negative_prompt = "low quality, bad quality"
image = pipe(prompt=prompt, negative_prompt=negative_prompt, prior_guidance_scale =1.0, height=768, width=768).images[0]
image.save("portrait.png")

高级用法
文本引导的图像到图像生成
from PIL import Image
import requests
from io import BytesIO
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
response = requests.get(url)
original_image = Image.open(BytesIO(response.content)).convert("RGB")
original_image = original_image.resize((768, 512))

from diffusers import AutoPipelineForImage2Image
import torch
pipe = AutoPipelineForImage2Image.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16)
pipe.enable_model_cpu_offload()
prompt = "A fantasy landscape, Cinematic lighting"
negative_prompt = "low quality, bad quality"
image = pipe(prompt=prompt, image=original_image, strength=0.3, height=768, width=768).images[0]
out.images[0].save("fantasy_land.png")

图像插值
from diffusers import KandinskyV22PriorPipeline, KandinskyV22Pipeline
from diffusers.utils import load_image
import PIL
import torch
pipe_prior = KandinskyV22PriorPipeline.from_pretrained(
"kandinsky-community/kandinsky-2-2-prior", torch_dtype=torch.float16
)
pipe_prior.to("cuda")
img1 = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/cat.png"
)
img2 = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/starry_night.jpeg"
)
images_texts = ["a cat", img1, img2]
weights = [0.3, 0.3, 0.4]
prompt = ""
prior_out = pipe_prior.interpolate(images_texts, weights)
pipe = KandinskyV22Pipeline.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16)
pipe.to("cuda")
image = pipe(**prior_out, height=768, width=768).images[0]
image.save("starry_cat.png")

📚 详细文档
模型架构概述
Kandinsky 2.2是一个基于unCLIP和潜在扩散的文本条件扩散模型,由基于Transformer的图像先验模型、Unet扩散模型和解码器组成。
模型架构如下图所示 - 左侧的图表描述了训练图像先验模型的过程,中间的图是文本到图像的生成过程,右侧的图是图像插值。
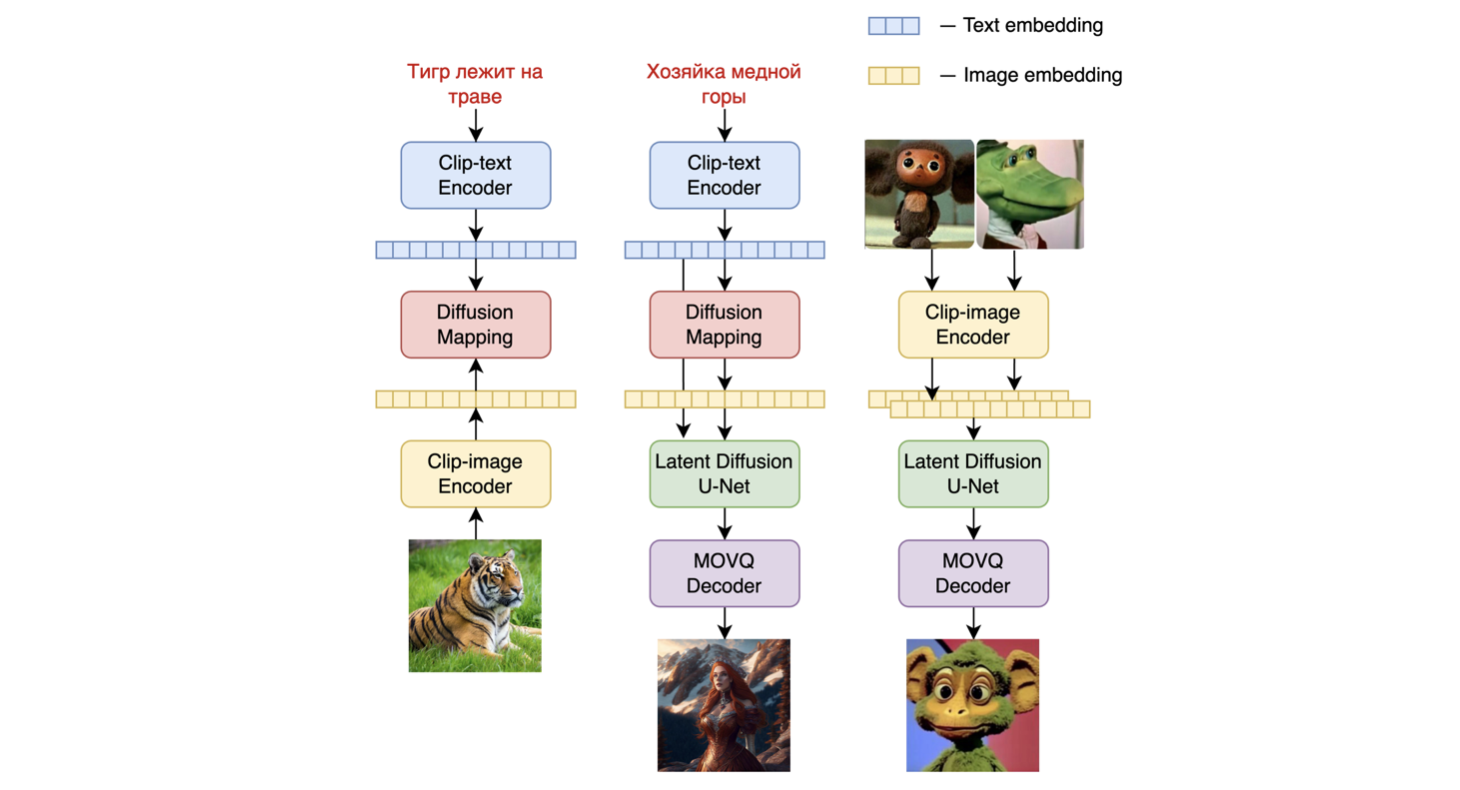
具体而言,图像先验模型是在使用预训练的CLIP - ViT - G模型生成的CLIP文本和图像嵌入上进行训练的。训练好的图像先验模型随后用于为输入的文本提示生成CLIP图像嵌入。输入的文本提示及其CLIP图像嵌入都将用于扩散过程。MoVQGAN模型作为模型的最后一部分,将潜在表示解码为实际图像。
模型训练细节
该模型的图像先验训练是在LAION Improved Aesthetics数据集上进行的,然后在LAION HighRes数据上进行微调。
主要的文本到图像扩散模型是在LAION HighRes数据集上进行训练的,然后使用从开放源单独收集的包含200万个非常高质量高分辨率图像及其描述的数据集(COYO、动漫、俄罗斯地标等)进行微调。
Kandinsky 2.2的主要变化是替换了CLIP - ViT - G。其图像编码器显著提高了模型生成更具美感图片和更好理解文本的能力,从而提升了其整体性能。
由于更换了CLIP模型,图像先验模型进行了重新训练,文本到图像扩散模型进行了2000次迭代的微调。Kandinsky 2.2在各种分辨率(从512 x 512到1536 x 1536)以及不同宽高比的数据上进行了训练。因此,Kandinsky 2.2可以生成任意宽高比的1024 x 1024输出。
模型评估
我们在COCO_30k数据集上以零样本模式对Kandinsky 2.1的性能进行了定量测量。下表展示了FID值。
生成模型在COCO_30k上的FID指标值
| 模型 |
FID (30k) |
| eDiff - I (2022) |
6.95 |
| Image (2022) |
7.27 |
| Kandinsky 2.1 (2023) |
8.21 |
| Stable Diffusion 2.1 (2022) |
8.59 |
| GigaGAN, 512x512 (2023) |
9.09 |
| DALL - E 2 (2022) |
10.39 |
| GLIDE (2022) |
12.24 |
| Kandinsky 1.0 (2022) |
15.40 |
| DALL - E (2021) |
17.89 |
| Kandinsky 2.0 (2022) |
20.00 |
| GLIGEN (2022) |
21.04 |
更多信息,请参考即将发布的技术报告。
📄 许可证
本项目采用Apache - 2.0许可证。
BibTex
如果您在研究中发现此仓库有用,请引用:
@misc{kandinsky 2.2,
title = {kandinsky 2.2},
author = {Arseniy Shakhmatov, Anton Razzhigaev, Aleksandr Nikolich, Vladimir Arkhipkin, Igor Pavlov, Andrey Kuznetsov, Denis Dimitrov},
year = {2023},
howpublished = {},
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors Transformers 支持多种语言
Transformers 支持多种语言