%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Donut Base Japanese Visual Novel
模型概述
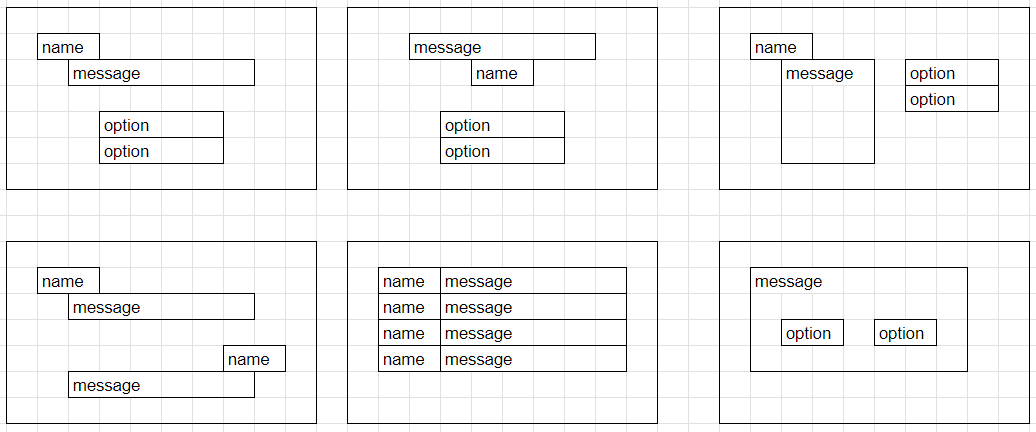
Donut模型經過微調,專門用於識別視覺小說風格的圖像中的文本內容,包括對話、選項和角色名稱。
模型特點
視覺小說專用
專門針對視覺小說風格的圖像進行優化,能準確識別對話、選項和角色名稱。
佈局適應
訓練包含多種常見視覺小說佈局及其變體,能處理不同排版格式。
注音過濾
設計目標是不受注音假名影響,專注於準確讀取正文內容。
UI元素過濾
能儘量避免讀取SAVE、LOAD等UI元素及日期顯示等非對話內容。
模型能力
視覺小說圖像識別
日語文本提取
對話選項解析
角色名稱識別
使用案例
遊戲開發
視覺小說文本提取
自動識別視覺小說遊戲截圖中的對話內容和選項
輸出結構化JSON格式的對話信息
遊戲測試自動化
用於自動化測試視覺小說遊戲中的文本顯示
驗證遊戲文本是否正確顯示
本地化工具
翻譯輔助
提取視覺小說文本用於翻譯工作
提供待翻譯文本的準確提取





精選推薦AI模型
Llama 3 Typhoon V1.5x 8b Instruct
專為泰語設計的80億參數指令模型,性能媲美GPT-3.5-turbo,優化了應用場景、檢索增強生成、受限生成和推理任務
大型語言模型 Transformers 支持多種語言
Transformers 支持多種語言
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-Tiny是一個基於SODA數據集訓練的超小型對話模型,專為邊緣設備推理設計,體積僅為Cosmo-3B模型的2%左右。
對話系統 Transformers 英語
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
基於RoBERTa架構的中文抽取式問答模型,適用於從給定文本中提取答案的任務。
問答系統 中文
R
uer
2,694
98