%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Donut Base Japanese Visual Novel
该模型是在视觉小说风格图像的合成数据集上对naver-clova-ix/donut-base进行训练的成果,专门用于识别视觉小说中的文本和选项。
Downloads 14
Release Time : 5/3/2023
Model Overview
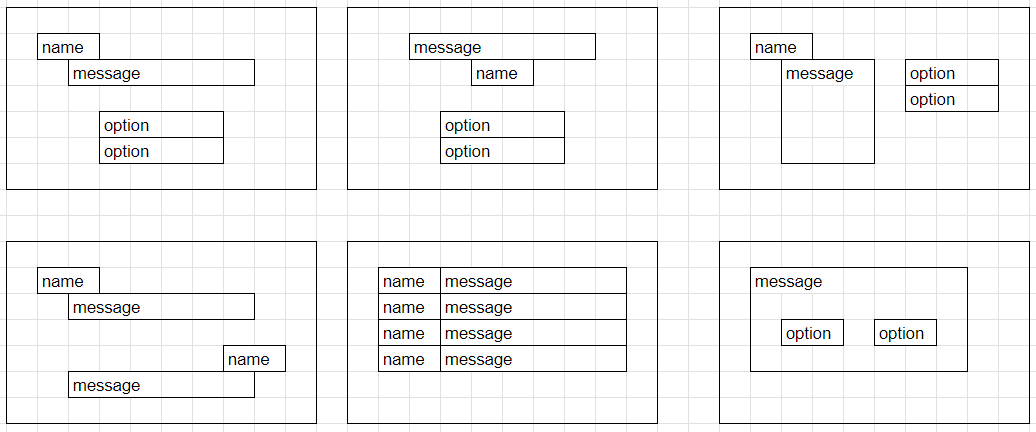
Donut模型经过微调,专门用于识别视觉小说风格的图像中的文本内容,包括对话、选项和角色名称。
Model Features
视觉小说专用
专门针对视觉小说风格的图像进行优化,能准确识别对话、选项和角色名称。
布局适应
训练包含多种常见视觉小说布局及其变体,能处理不同排版格式。
注音过滤
设计目标是不受注音假名影响,专注于准确读取正文内容。
UI元素过滤
能尽量避免读取SAVE、LOAD等UI元素及日期显示等非对话内容。
Model Capabilities
视觉小说图像识别
日语文本提取
对话选项解析
角色名称识别
Use Cases
游戏开发
视觉小说文本提取
自动识别视觉小说游戏截图中的对话内容和选项
输出结构化JSON格式的对话信息
游戏测试自动化
用于自动化测试视觉小说游戏中的文本显示
验证游戏文本是否正确显示
本地化工具
翻译辅助
提取视觉小说文本用于翻译工作
提供待翻译文本的准确提取





Featured Recommended AI Models
Llama 3 Typhoon V1.5x 8b Instruct
专为泰语设计的80亿参数指令模型,性能媲美GPT-3.5-turbo,优化了应用场景、检索增强生成、受限生成和推理任务
大型语言模型 Transformers Supports Multiple Languages
Transformers Supports Multiple Languages
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-Tiny是一个基于SODA数据集训练的超小型对话模型,专为边缘设备推理设计,体积仅为Cosmo-3B模型的2%左右。
对话系统 Transformers English
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
基于RoBERTa架构的中文抽取式问答模型,适用于从给定文本中提取答案的任务。
问答系统 Chinese
R
uer
2,694
98