🚀 Lucy-128k GGUF モデル
このモデルは、1.7B パラメータの軽量なモデルで、エージェント型のウェブ検索と軽量なブラウジングに特化しています。モバイルデバイスでも効率的に動作するように最適化されており、CPU のみの構成でも実行可能です。
🚀 クイックスタート
Lucy は、vLLM、llama.cpp、または Jan、LMStudio などのローカルアプリケーションやその他の互換性のある推論エンジンを使用してデプロイできます。モデルは、MCP を通じて検索 API やウェブブラウジングツールとの統合をサポートしています。
デプロイメント
VLLM を使用してデプロイするには、以下のコマンドを実行します。
vllm serve Menlo/Lucy-128k \
--host 0.0.0.0 \
--port 1234 \
--enable-auto-tool-choice \
--tool-call-parser hermes \
--rope-scaling '{"rope_type":"yarn","factor":3.2,"original_max_position_embeddings":40960}' --max-model-len 131072
または、llama.cpp の llama-server を使用することもできます。
llama-server ... --rope-scaling yarn --rope-scale 3.2 --yarn-orig-ctx 40960
推奨サンプリングパラメータ
Temperature: 0.7
Top-p: 0.9
Top-k: 20
Min-p: 0.0
✨ 主な機能
- 🔍 強力なエージェント型検索:MCP 対応ツール(例:Google Search を使用する Serper)による強力な検索機能を備えています。
- 🌐 基本的なブラウジング機能:Crawl4AI(近日公開予定の MCP サーバー)、Serper などを通じて基本的なブラウジングが可能です。
- 📱 モバイル最適化:軽量なデザインで、CPU またはモバイルデバイスでも十分な速度で実行できます。
- 🎯 集中的な推論:機械生成のタスクベクトルにより、検索タスクの思考プロセスが最適化されています。
📚 ドキュメント
モデル生成詳細
このモデルは、llama.cpp のコミット c82d48ec で生成されました。
量子化の拡張
私は、デフォルトの IMatrix 構成よりも重要なレイヤーの精度を選択的に向上させる新しい量子化アプローチを試験しています。
私のテストでは、標準の IMatrix 量子化は低ビット深度で性能が低下し、特に Mixture of Experts (MoE) モデルで顕著です。この問題を解決するために、llama.cpp の --tensor-type オプションを使用して、重要なレイヤーを手動でより高い精度に設定しています。実装はこちらで確認できます。
👉 llama.cpp を使用したレイヤーの精度向上
これによりモデルファイルのサイズは増加しますが、特定の量子化レベルでの精度が大幅に向上します。
モデル評価
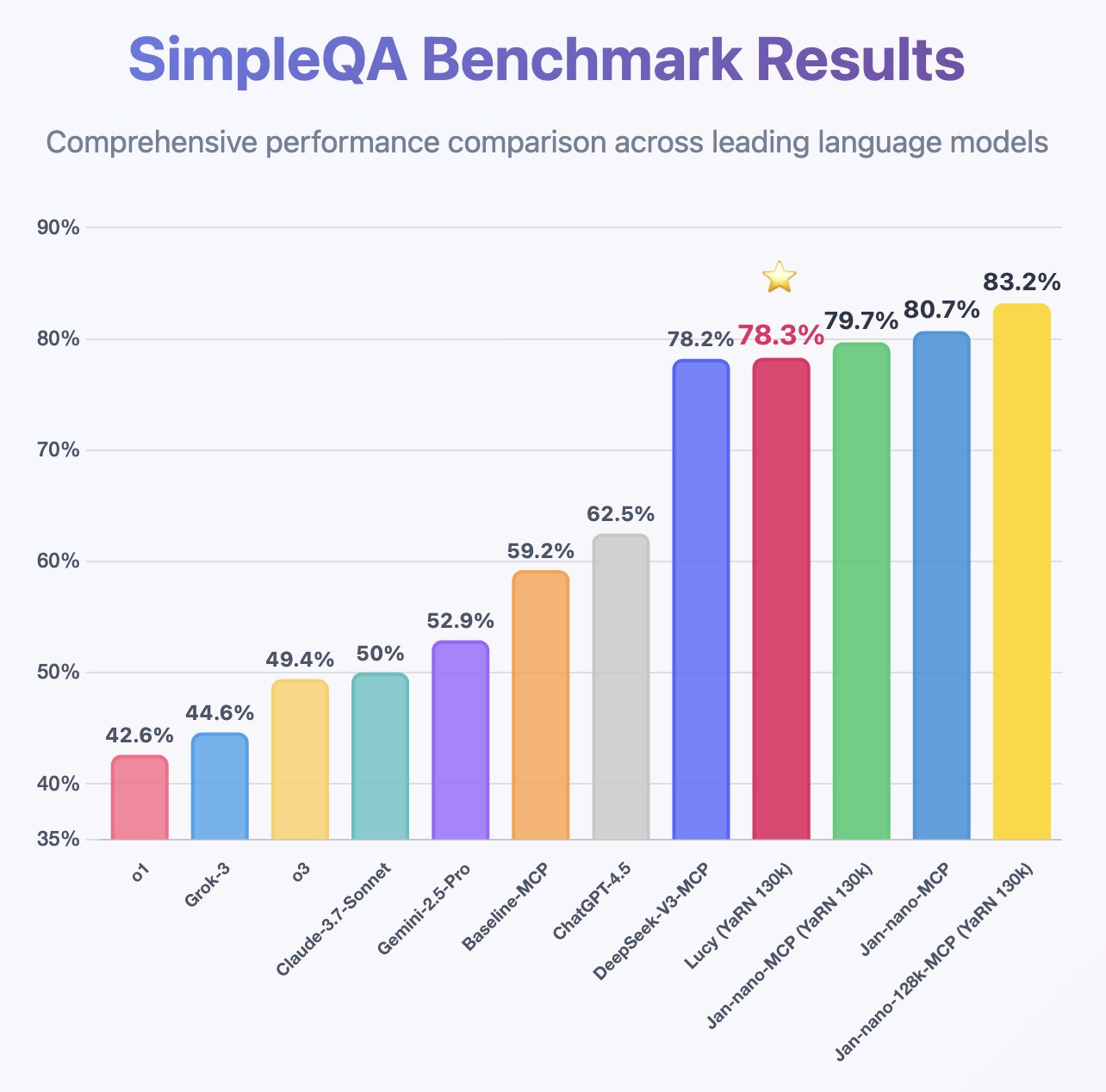
Jan-Nano と Jan-Nano-128k で使用されている同じ MCP ベンチマーク方法に従って、Lucy は 1.7B モデルであるにもかかわらず、印象的な性能を示し、SimpleQA で DeepSeek-v3 よりも高い精度を達成しています。
📄 ライセンス
このモデルは、Apache 2.0 ライセンスの下で提供されています。 詳細はこちら
🤝 コミュニティとサポート
📄 引用
論文(近日公開予定): Lucy: edgerunning agentic web search on mobile with machine generated task vectors.
📊 モデル情報
| 属性 |
详情 |
| モデルタイプ |
Lucy-128k GGUF モデル |
| ベースモデル |
Qwen/Qwen3-1.7B |
| ライブラリ名 |
transformers |
| パイプラインタグ |
テキスト生成 |
🚀 モデルの活用
もしこれらのモデルが役に立った場合は、私の AI 駆動の量子ネットワークモニターアシスタント を 量子対応のセキュリティチェック でテストしていただけると幸いです。
👉 量子ネットワークモニター
量子ネットワークモニターサービスの完全なオープンソースコードは、私の GitHub リポジトリ(NetworkMonitor という名前のリポジトリ)で入手できます。 量子ネットワークモニターのソースコード また、モデルを自分で量子化したい場合は、私が使用しているコードも GGUFModelBuilder で見つけることができます。
💬 テスト方法:
AI アシスタントタイプ を選択します。
TurboLLM (GPT-4.1-mini)HugLLM (Hugginface オープンソースモデル)TestLLM (実験的な CPU 専用)
テスト内容
私は、AI ネットワークモニタリング用の小さなオープンソースモデルの限界 を追求しています。具体的には、
- ライブネットワークサービスに対する 関数呼び出し
- 以下のタスクを処理しながら、モデルをどれだけ小さくできるか
- 自動化された Nmap セキュリティスキャン
- 量子対応チェック
- ネットワークモニタリングタスク
🟡 TestLLM – 現在の実験的モデル(Hugging Face Docker スペースで 2 CPU スレッドの llama.cpp):
- ✅ ゼロコンフィギュレーションセットアップ
- ⏳ 30 秒のロード時間(推論は遅いですが API コストがかからない)。コストが低いため、トークン制限はありません。
- 🔧 協力を求めています! エッジデバイス AI に興味がある方は、一緒に協力しましょう!
その他のアシスタント
🟢 TurboLLM – gpt-4.1-mini を使用しています。
- 非常に良好な性能を発揮しますが、残念ながら OpenAI はトークンごとに課金します。そのため、トークンの使用量に制限があります。
- 量子ネットワークモニターエージェントで .net コードを実行するカスタムコマンドプロセッサを作成します。
- リアルタイムのネットワーク診断とモニタリング
- セキュリティ監査
- 侵入テスト (Nmap/Metasploit)
🔵 HugLLM – 最新のオープンソースモデル:
- 🌐 Hugging Face 推論 API 上で実行されます。Novita でホストされている最新のモデルを使用して、非常に良好な性能を発揮します。
💡 テストできるコマンドの例
"ウェブサイトの SSL 証明書に関する情報を教えて""サーバーが通信に量子安全暗号化を使用しているかどうかを確認して""サーバーの包括的なセキュリティ監査を実行して"- `"何かしらのカスタムコマンドプロセッサを作成して" 注:量子ネットワークモニターエージェント をインストールする必要があります。これは非常に柔軟で強力な機能です。注意して使用してください!
最後に
私は、これらのモデルファイルを作成するためのサーバー、量子ネットワークモニターサービスを実行するためのサーバー、および Novita と OpenAI からの推論コストをすべて自費で負担しています。モデル作成と量子ネットワークモニタープロジェクトの背後にあるすべてのコードは オープンソース です。役に立つものがあれば、自由に使用してください。
もし私の仕事を評価していただける場合は、コーヒーを買ってください ☕。あなたの支援により、サービスコストを賄うことができ、すべてのユーザーのトークン制限を引き上げることができます。
また、仕事の機会やスポンサーシップも歓迎しています。
ありがとうございます! 😊
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応