🚀 GLM-4.1V-9B-Thinking
GLM-4.1V-9B-Thinkingは、視覚言語モデルに基づく革新的な成果です。複雑なタスクにおける推論能力を向上させることを目的としており、多くの分野のベンチマークテストで優れた性能を発揮し、インテリジェントシステムの発展に強力なサポートを提供します。
📄 GLM-4.1V-9B-Thinkingの 論文 を確認してください。
🧪 GLM-4.1V-9B-Thinkingの Hugging Face または ModelScope のオンラインデモを試してみてください。
💻 智譜基礎モデルオープンプラットフォーム でGLM-4.1V-9B-Thinking APIを使用してください。
🚀 クイックスタート
高速推論
これは transformers ライブラリを使用して単一画像の推論を行う簡単な例です。
まず、ソースコードから transformers ライブラリをインストールします。
pip install git+https://github.com/huggingface/transformers.git
次に、以下のコードを実行します。
from transformers import AutoProcessor, Glm4vForConditionalGeneration
import torch
MODEL_PATH = "THUDM/GLM-4.1V-9B-Thinking"
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": "https://upload.wikimedia.org/wikipedia/commons/f/fa/Grayscale_8bits_palette_sample_image.png"
},
{
"type": "text",
"text": "describe this image"
}
],
}
]
processor = AutoProcessor.from_pretrained(MODEL_PATH, use_fast=True)
model = Glm4vForConditionalGeneration.from_pretrained(
pretrained_model_name_or_path=MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto",
)
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=8192)
output_text = processor.decode(generated_ids[0][inputs["input_ids"].shape[1]:], skip_special_tokens=False)
print(output_text)
ビデオ推論やウェブデモのデプロイなど、より多くのコードについては、私たちの GitHub をご覧ください。
✨ 主な機能
視覚言語モデル(VLMs)は、インテリジェントシステムの基盤となるコンポーネントになっています。現実世界のAIタスクがますます複雑になるにつれ、VLMsは基本的なマルチモーダル感知を超え、複雑なタスクにおける推論能力を向上させる必要があります。これには、複雑な問題解決、長文脈理解、マルチモーダルエージェントなどのアプリケーションを実現するために、精度、包括性、知性の向上が含まれます。
GLM-4-9B-0414 基礎モデルに基づいて、新しいオープンソースの視覚言語モデル GLM-4.1V-9B-Thinking をリリースしました。このモデルは、視覚言語モデルの推論能力の上限を探求することを目的としています。「思考パラダイム」を導入し、強化学習を利用することで、このモデルはその能力を大幅に向上させました。100億パラメータの視覚言語モデルの中で、最も先進的な性能を達成し、18のベンチマークタスクで、720億パラメータのQwen-2.5-VL-72Bと同等またはそれ以上の性能を発揮します。また、視覚言語モデルの能力限界に関するさらなる研究をサポートするために、基礎モデルGLM-4.1V-9B-Baseをオープンソース化しました。
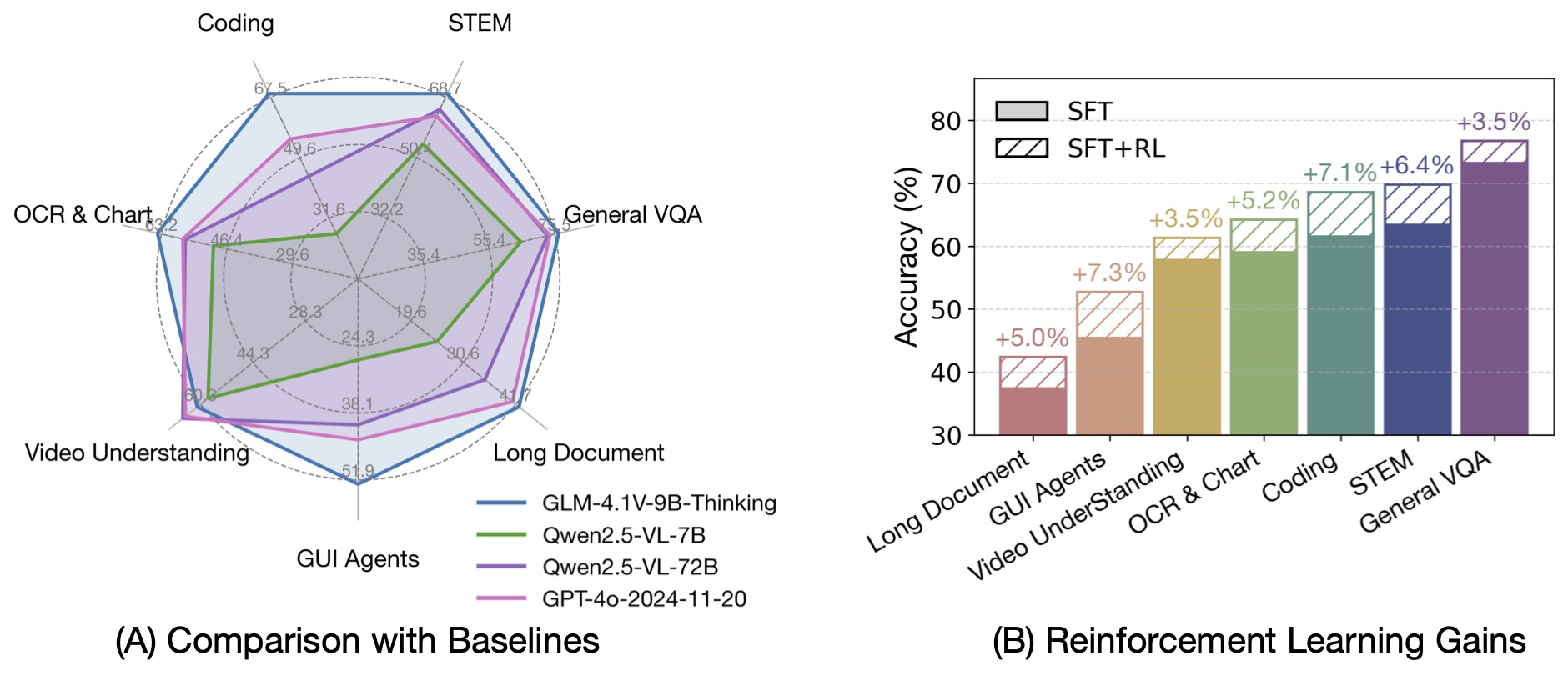
前世代のモデルであるCogVLM2やGLM-4Vシリーズと比較して、GLM-4.1V-Thinking には以下の改善点があります。
- このシリーズで初めて推論に特化したモデルで、数学分野だけでなく、すべてのサブ分野で世界トップレベルの性能を達成しています。
- 64k のコンテキスト長をサポートしています。
- 任意のアスペクト比 を処理でき、最大 4K の画像解像度をサポートしています。
- 中英語のバイリンガル での使用をサポートするオープンソース版が提供されています。
ベンチマークテストの性能
思考連鎖推論パラダイムを導入することで、GLM-4.1V-9B-Thinkingは回答の精度、豊富さ、説明性を大幅に向上させました。これは、従来の非推論型視覚モデルを全面的に上回っています。28のベンチマークタスクのうち、23のタスクで100億パラメータレベルのモデルの中で最高の性能を達成し、18のタスクで720億パラメータのQwen-2.5-VL-72Bを上回っています。

📚 ドキュメント
モデルの概要
視覚言語モデル(VLMs)は、インテリジェントシステムの基盤となるコンポーネントになっています。現実世界のAIタスクがますます複雑になるにつれ、VLMsは基本的なマルチモーダル感知を超え、複雑なタスクにおける推論能力を向上させる必要があります。これには、複雑な問題解決、長文脈理解、マルチモーダルエージェントなどのアプリケーションを実現するために、精度、包括性、知性の向上が含まれます。
GLM-4-9B-0414 基礎モデルに基づいて、新しいオープンソースの視覚言語モデル GLM-4.1V-9B-Thinking をリリースしました。このモデルは、視覚言語モデルの推論能力の上限を探求することを目的としています。「思考パラダイム」を導入し、強化学習を利用することで、このモデルはその能力を大幅に向上させました。100億パラメータの視覚言語モデルの中で、最も先進的な性能を達成し、18のベンチマークタスクで、720億パラメータのQwen-2.5-VL-72Bと同等またはそれ以上の性能を発揮します。また、視覚言語モデルの能力限界に関するさらなる研究をサポートするために、基礎モデルGLM-4.1V-9B-Baseをオープンソース化しました。
📄 ライセンス
このプロジェクトはMITライセンスを採用しています。
| 属性 |
詳細 |
| モデルタイプ |
画像テキストからテキスト |
| 基礎モデル |
THUDM/GLM-4-9B-0414 |
| ライブラリ名 |
transformers |
| タグ |
推論 |
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応