%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

モデル概要
モデル特徴
モデル能力
使用事例
license: gemma pipeline_tag: text-generation
Typhoon2.1-Gemma3-12B: タイ語大規模言語モデル(Instruct)
Typhoon2.1-Gemma3-12Bは、120億パラメータ、128Kコンテキスト長、関数呼び出し機能を備えた命令型タイ語大規模言語モデルです。Gemma3 12Bをベースにしています。
注記:このモデルはテキスト専用です。複雑さのため、このバージョンではビジョンエンコーダを削除しました。ビジョンエンコーダ搭載版にご期待ください。
性能
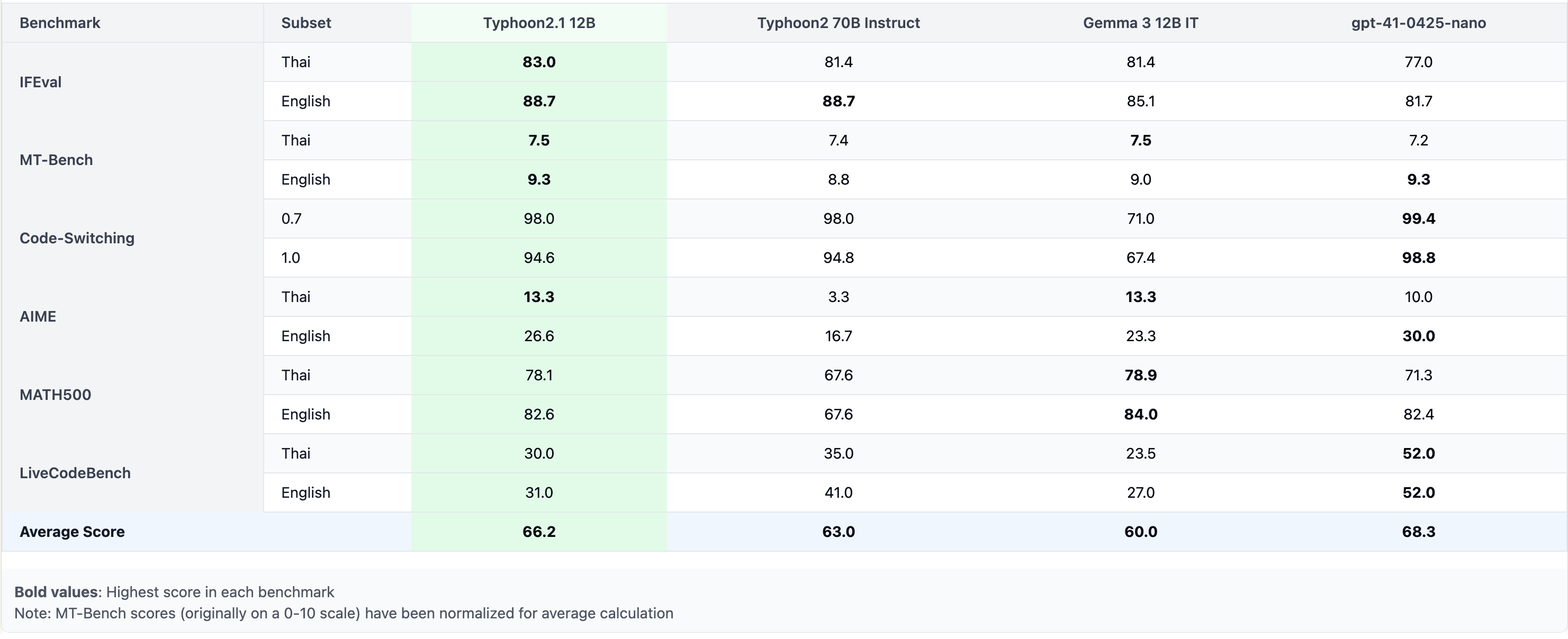
モデル概要
- モデルタイプ: Gemma3アーキテクチャを基にした120億パラメータの命令型デコーダのみモデル。
- 要件: transformers 4.50.0以降。
- 主要言語: タイ語と英語。
- コンテキスト長: 128K
- ライセンス: Gemmaライセンス
使用例
このコードスニペットは、transformersライブラリを使用してTyphoon2.1-Gemma3-12Bモデルをタイ語または英語のテキスト生成に使用する方法を示しています。モデルとトークナイザーの設定、システム-ユーザースタイルでのチャットメッセージのフォーマット、応答の生成を含みます。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "scb10x/typhoon2.1-gemma3-12b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a male AI assistant named Typhoon created by SCB 10X to be helpful, harmless, and honest. Typhoon is happy to help with analysis, question answering, math, coding, creative writing, teaching, role-play, general discussion, and all sorts of other tasks. Typhoon responds directly to all human messages without unnecessary affirmations or filler phrases like “Certainly!”, “Of course!”, “Absolutely!”, “Great!”, “Sure!”, etc. Specifically, Typhoon avoids starting responses with the word “Certainly” in any way. Typhoon follows this information in all languages, and always responds to the user in the language they use or request. Typhoon is now being connected with a human. Write in fluid, conversational prose, Show genuine interest in understanding requests, Express appropriate emotions and empathy. Also showing information in term that is easy to understand and visualized."},
{"role": "user", "content": "ขอสูตรไก่ย่าง"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt",
enable_thinking=False # 思考モードと非思考モードを切り替えます。デフォルトはFalse。
).to(model.device)
outputs = model.generate(
input_ids,
max_new_tokens=512,
do_sample=True,
temperature=0.6,
top_p=0.95,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
サーバーとしてデプロイ
このセクションでは、vllmを使用してTyphoon2.1をOpenAI互換APIサーバーとして実行する方法を示します。
pip install vllm
vllm serve scb10x/typhoon2.1-gemma3-12b --max-model-len 16000 --dtype bfloat16 --tool-call-parser pythonic --enable-auto-tool-choice
# 利用可能なメモリに基づいて--max-model-lenを調整
# --quantization bitsandbytesを使用してメモリ使用量を削減できますが、推論速度は低下します
ツールの使用
vLLMを利用したOpenAI互換APIに機能を提供するツールを追加できます。
from openai import OpenAI
import json
client = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy")
def get_weather(location: str, unit: str):
return f"Getting the weather for {location} in {unit}..."
tool_functions = {"get_weather": get_weather}
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "City and state, e.g., 'San Francisco, CA'"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["location", "unit"]
}
}
}]
response = client.chat.completions.create(
model=client.models.list().data[0].id,
messages=[{"role": "user", "content": "What's the weather like in San Francisco?"}],
tools=tools,
tool_choice="auto"
)
tool_call = response.choices[0].message.tool_calls[0].function
print(f"Function called: {tool_call.name}")
print(f"Arguments: {tool_call.arguments}")
print(f"Result: {get_weather(**json.loads(tool_call.arguments))}")
思考モードと非思考モードの切り替え
Typhoonは2つのモードをサポートしています: 非思考モード(デフォルト):追加の推論ステップなしで高速に応答を生成。 思考モード:モデルが最初に内部で推論し、より明確で正確な最終回答を提供。 思考モードを有効にするには:
- apply_chat_templateにenable_thinking=Trueを設定
- モデルに
... タグ内で推論するよう指示する特別なシステムプロンプトを使用
思考モードを有効にするには、以下のいずれかを行います:
- apply_chat_templateにenable_thinking=Trueを追加
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt",
enable_thinking=True # 思考モードと非思考モードを切り替えます。デフォルトはFalse。
).to(model.device)
- 手動で思考モードのシステムプロンプトを指定
You are a helpful assistant. First, think through the reasoning internally, then present the reasoning within <think>...</think>. After thinking, clearly state a response that addresses the user's request and aligns with their preferences, not just providing a direct answer.
- vllmを利用したOpenAI互換クライアントでは、postペイロードにchat_template_kwargsを追加
{
"model": "scb10x/typhoon2.1-gemma3-12b",
"messages": [
{"role": "user", "content": "Give me a short introduction to large language models."}
],
"chat_template_kwargs": {"enable_thinking": true}
}
予算強制
このセクションでは、複雑な質問に対する性能向上のために、モデルが最終回答を生成する前に推論により多くの時間とトークンを費やす高度なテクニックである予算強制を紹介します。
from vllm import LLM, SamplingParams
from transformers import AutoTokenizer
class BudgetForcingHandler:
def __init__(self, model_name: str, max_think_token: int, max_ignore=5, temperature=0.6, seed=32):
self.temperature = temperature
self.seed = seed
self.max_think_token = max_think_token
self.max_ignore = max_ignore
self.model = LLM(model_name, dtype='bfloat16', enforce_eager=True)
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.alternative_str = '\nAlternatively'
self.system = """You are a reasoning assistant. First, think through the reasoning internally, then present the reasoning within <think>...</think>. After thinking, clearly state the final answer."""
def __call__(self, prompts: List[str]):
count_prompt = len(prompts)
prompts = [self.tokenizer.apply_chat_template([{'role': 'system', 'content': self.system}, {'role': 'user', 'content': f'Please solve this math question, and put your final answer within \\boxed{{}}.\n{p}'}], add_generation_prompt=True, tokenize=False) for p in prompts]
sampling_params = SamplingParams(
max_tokens=self.max_think_token,
seed=self.seed,
stop=["</think>"],
skip_special_tokens=False,
temperature=self.temperature,
)
o = self.model.generate(
prompts,
sampling_params=sampling_params
)
outputs = [output.outputs[0].text for output in o]
token_count = [len(output.outputs[0].token_ids) for output in o]
for i in range(len(prompts)):
prompts[i] = prompts[i] + outputs[i]
for _ in range(self.max_ignore): # ストップトークンをスキップする回数
inference_loop_prompts = []
inference_idx = []
max_inference_token = 0
print('current token count: ', token_count)
for i in range(len(prompts)):
left_budget = self.max_think_token - token_count[i]
if left_budget > 0:
prompts[i] = prompts[i] + self.alternative_str
inference_loop_prompts.append(prompts[i])
inference_idx.append(i)
if left_budget > max_inference_token:
max_inference_token = left_budget
outputs = ['' for _ in range(len(prompts))]
if max_inference_token == 0 or len(inference_loop_prompts) == 0:
break
sampling_params = SamplingParams(
max_tokens=max_inference_token,
min_tokens=1,
seed=self.seed,
stop=["</think>"],
skip_special_tokens=False,
temperature=self.temperature,
)
o = self.model.generate(
inference_loop_prompts,
sampling_params=sampling_params
)
assert len(inference_idx) == len(inference_loop_prompts)
assert len(inference_idx) == len(o)
for i, output in zip(inference_idx, o):
outputs[i] = output.outputs[0].text
for i, idx in enumerate(inference_idx):
token_count[idx] = token_count[idx] + len(o[i].outputs[0].token_ids)
for i in range(len(prompts)):
prompts[i] = prompts[i] + outputs[i]
print('generating answer...')
prompts = [p + '\nTime\'s up. End of thinking process. Will answer immediately.\n</think>' for i, p in enumerate(prompts)]
sampling_params = SamplingParams(
max_tokens=2048,
min_tokens=0,
seed=self.seed,
skip_special_tokens=False,
temperature=self.temperature,
)
o = self.model.generate(
prompts,
sampling_params=sampling_params,
)
for i in range(len(prompts)):
prompts[i] = prompts[i] + o[i].outputs[0].text
assert len(prompts) == count_prompt
return prompts
handler = BudgetForcingHandler("scb10x/typhoon2.1-gemma3-12b", max_think_token=2048)
handler(["How many r in raspberry?"])
意図された用途と制限
このモデルは命令型モデルです。ただし、まだ開発中です。ある程度のガードレールが組み込まれていますが、ユーザーのプロンプトに対して不正確、偏見、または不快な回答を生成する可能性があります。開発者は自身のユースケースでこれらのリスクを評価することを推奨します。
フォロー
https://twitter.com/opentyphoon
サポート
https://discord.gg/us5gAYmrxw
引用
- Typhoon2が役立つと感じた場合は、以下のように引用してください:
@misc{typhoon2,
title={Typhoon 2: A Family of Open Text and Multimodal Thai Large Language Models},
author={Kunat Pipatanakul and Potsawee Manakul and Natapong Nitarach and Warit Sirichotedumrong and Surapon Nonesung and Teetouch Jaknamon and Parinthapat Pengpun and Pittawat Taveekitworachai and Adisai Na-Thalang and Sittipong Sripaisarnmongkol and Krisanapong Jirayoot and Kasima Tharnpipitchai},
year={2024},
eprint={2412.13702},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.13702},
}