🚀 Apollo2-7B-GGUF
このモデルは、医療分野の質問応答に特化した言語モデルで、多言語に対応しています。元のモデルを量子化したもので、多くのアプリケーションで利用できます。
🚀 クイックスタート
このモデルは、llama.cpp互換のアプリケーションで実行できます。例えば、Text-Generation-WebUI、KoboldCpp、Jan、LM Studioなどです。
✨ 主な機能
- 多言語対応:英語、中国語、フランス語、ヒンディー語、スペイン語、アラビア語、ロシア語、日本語、韓国語、ドイツ語、イタリア語、ポルトガル語などの12の主要言語と、38のマイナー言語に対応。
- 医療分野特化:生物学や医学に関する質問応答に特化したモデル。
- 量子化モデル:llama.cpp-b3938を使用して量子化されたモデルで、実行効率が高い。
📦 インストール
インストールに関する具体的な手順は提供されていません。
💻 使用例
基本的な使用法
モデルの使用方法は、モデルの種類によって異なります。以下に例を示します。
Apollo2
- 0.5B, 1.5B, 7B:
User:{query}\nAssistant:{response}<|endoftext|>
- 2B, 9B:
User:{query}\nAssistant:{response}\<eos\>
- 3.8B:
<|user|>\n{query}<|end|><|assisitant|>\n{response}<|end|>
Apollo-MoE
- 0.5B, 1.5B, 7B:
User:{query}\nAssistant:{response}<|endoftext|>
高度な使用法
モデルの訓練や評価に関する具体的な手順は、以下の通りです。
- プロジェクトのデータセットをダウンロードします。
bash 0.download_data.sh
- 特定のモデルのテストデータと開発データを準備します。
bash 1.data_process_test&dev.sh
- 特定のモデルの訓練データを準備します(事前にトークン化されたデータを作成します)。
bash 2.data_process_train.sh
- モデルを訓練します。
bash 3.single_node_train.sh
- モデルを評価します。
bash 4.eval.sh
📚 ドキュメント
元のモデルカード
より多くの言語で医療用LLMを民主化する
英語、中国語、フランス語、ヒンディー語、スペイン語、アラビア語、ロシア語、日本語、韓国語、ドイツ語、イタリア語、ポルトガル語を含む12の主要言語と、これまでに38のマイナー言語をカバーしています。
📃 論文 • 🌐 デモ • 🤗 ApolloMoEDataset • 🤗 ApolloMoEBench • 🤗 モデル • 🌐 Apollo • 🌐 ApolloMoE

更新情報
- [2024.10.15] ApolloMoEリポジトリが公開されました!🎉
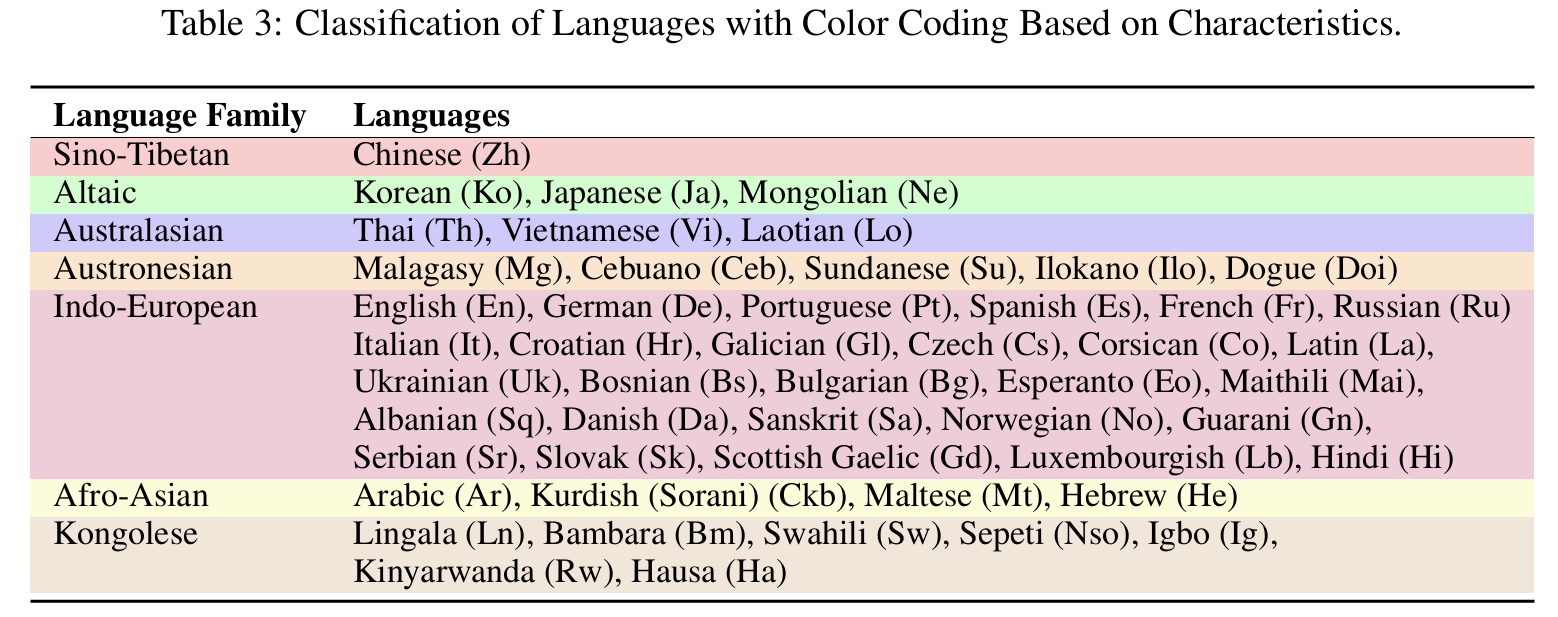
言語カバレッジ
12の主要言語と38のマイナー言語をカバーしています。
言語カバレッジを表示するにはクリック
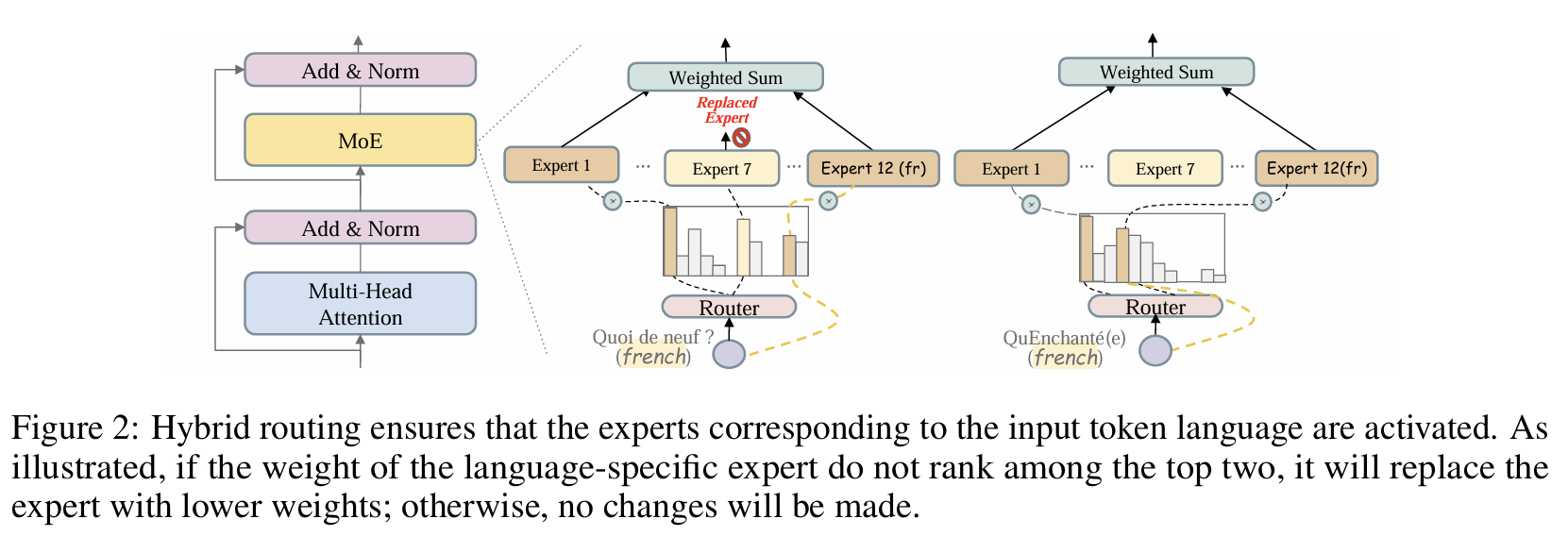
アーキテクチャ
MoEルーティング画像を表示するにはクリック
結果
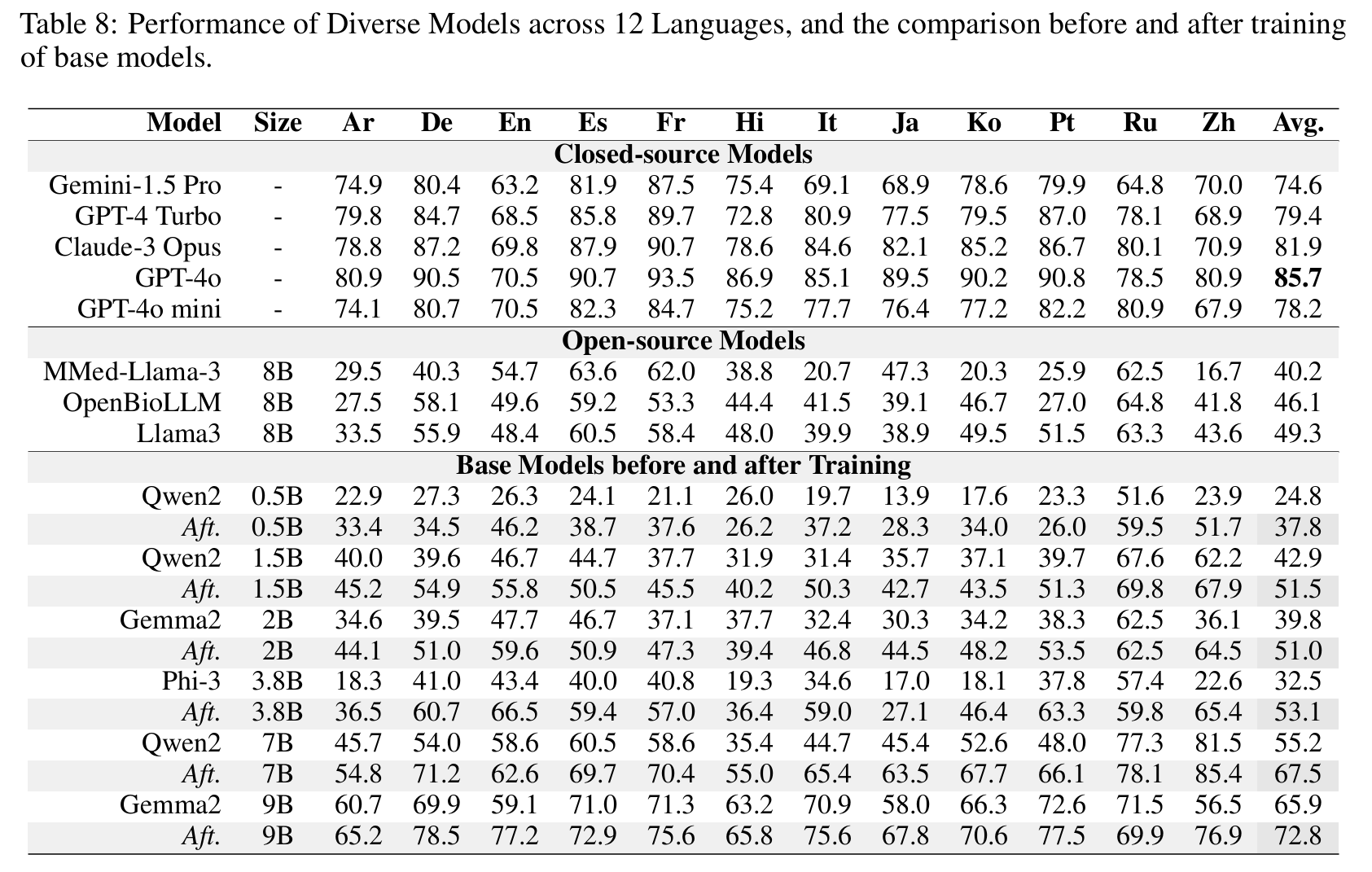
密モデル
🤗 Apollo2-0.5B • 🤗 Apollo2-1.5B • 🤗 Apollo2-2B
🤗 Apollo2-3.8B • 🤗 Apollo2-7B • 🤗 Apollo2-9B
密モデルの結果を表示するにはクリック
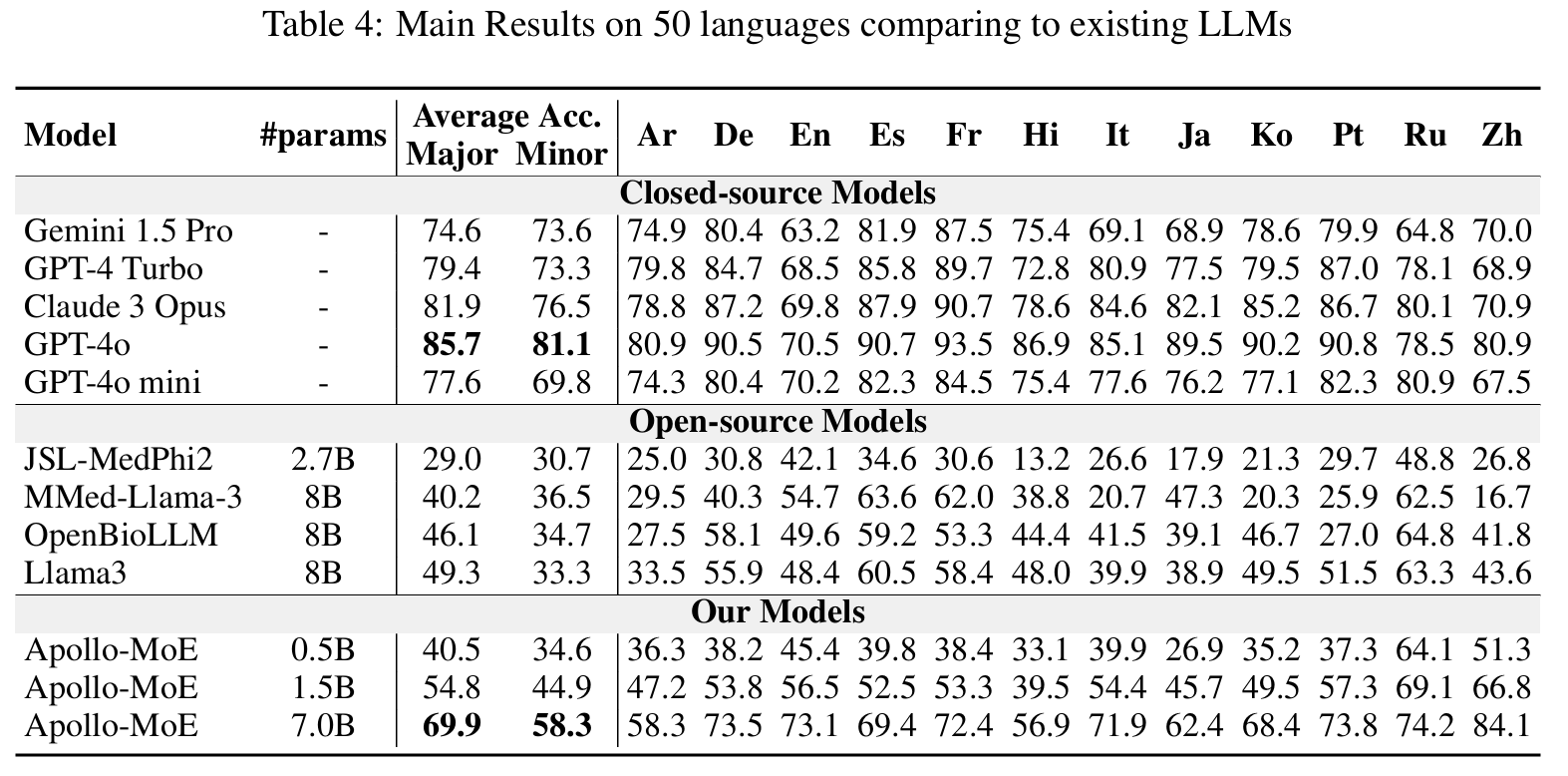
事後MoEモデル
🤗 Apollo-MoE-0.5B • 🤗 Apollo-MoE-1.5B • 🤗 Apollo-MoE-7B
事後MoEモデルの結果を表示するにはクリック
データセットと評価
展開するにはクリック
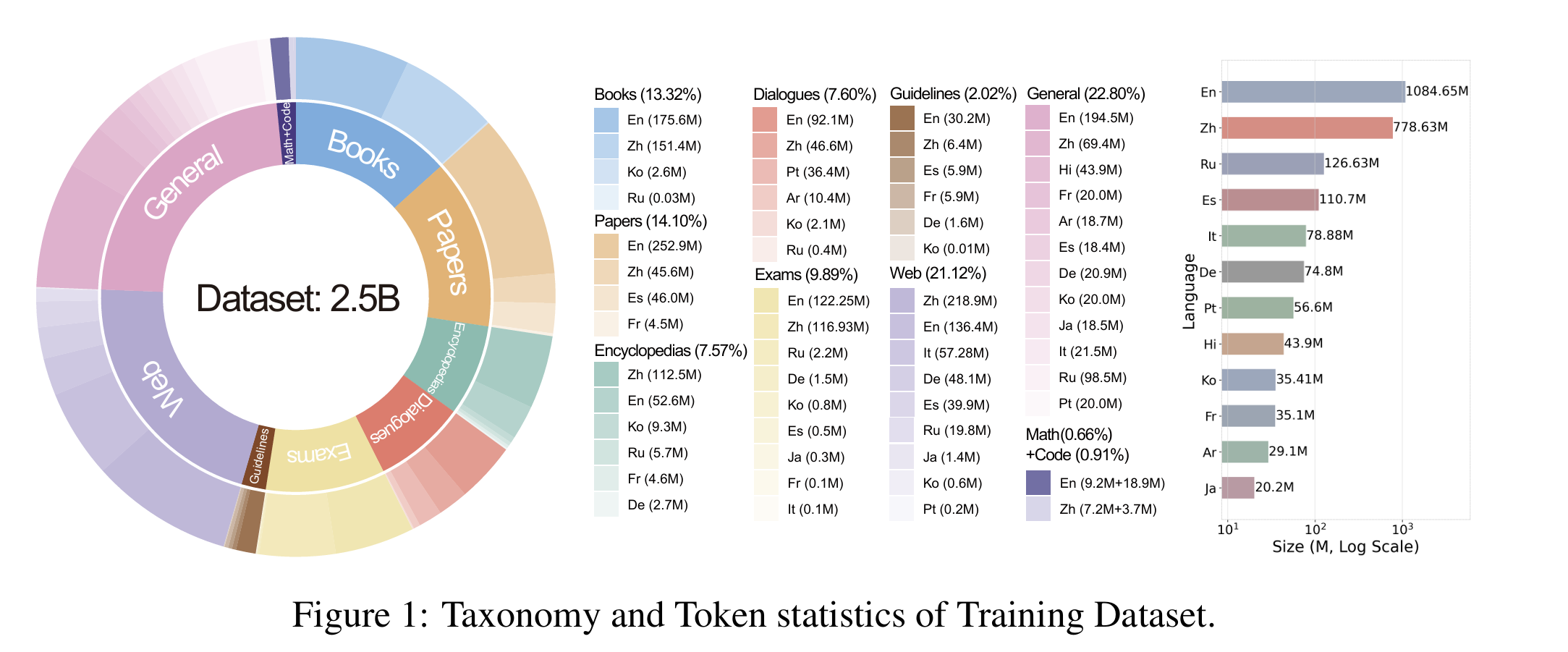
- [データカテゴリ](https://huggingface.co/datasets/FreedomIntelligence/ApolloCorpus/tree/main/train)
- **評価**:🤗 [ApolloMoEBench](https://huggingface.co/datasets/FreedomIntelligence/ApolloMoEBench)
展開するにはクリック
- **英語**:
- [MedQA-USMLE](https://huggingface.co/datasets/GBaker/MedQA-USMLE-4-options)
- [MedMCQA](https://huggingface.co/datasets/medmcqa/viewer/default/test)
- [PubMedQA](https://huggingface.co/datasets/pubmed_qa):結果の変動が大きすぎたため、論文では使用されていません。
- [MMLU-Medical](https://huggingface.co/datasets/cais/mmlu)
- 臨床知識、医学遺伝学、解剖学、専門医学、大学生物学、大学医学
- **中国語**:
- [MedQA-MCMLE](https://huggingface.co/datasets/bigbio/med_qa/viewer/med_qa_zh_4options_bigbio_qa/test)
- [CMB-single](https://huggingface.co/datasets/FreedomIntelligence/CMB):論文では使用されていません。
- 2,000の単一回答の選択問題をランダムにサンプリング。
- [CMMLU-Medical](https://huggingface.co/datasets/haonan-li/cmmlu)
- 解剖学、臨床知識、大学医学、遺伝学、栄養学、漢方医学、ウイルス学
- [CExam](https://github.com/williamliujl/CMExam):論文では使用されていません。
- 2,000の選択問題をランダムにサンプリング。
- **スペイン語**:[Head_qa](https://huggingface.co/datasets/head_qa)
- **フランス語**:
- [Frenchmedmcqa](https://github.com/qanastek/FrenchMedMCQA)
- [MMLU_FR]
- 臨床知識、医学遺伝学、解剖学、専門医学、大学生物学、大学医学
- **ヒンディー語**:[MMLU_HI](https://huggingface.co/datasets/FreedomIntelligence/MMLU_Hindi)
- 臨床知識、医学遺伝学、解剖学、専門医学、大学生物学、大学医学
- **アラビア語**:[MMLU_AR](https://huggingface.co/datasets/FreedomIntelligence/MMLU_Arabic)
- 臨床知識、医学遺伝学、解剖学、専門医学、大学生物学、大学医学
- **日本語**:[IgakuQA](https://github.com/jungokasai/IgakuQA)
- **韓国語**:[KorMedMCQA](https://huggingface.co/datasets/sean0042/KorMedMCQA)
- **イタリア語**:
- [MedExpQA](https://huggingface.co/datasets/HiTZ/MedExpQA)
- [MMLU_IT]
- 臨床知識、医学遺伝学、解剖学、専門医学、大学生物学、大学医学
- **ドイツ語**:[BioInstructQA](https://huggingface.co/datasets/BioMistral/BioInstructQA):ドイツ語部分
- **ポルトガル語**:[BioInstructQA](https://huggingface.co/datasets/BioMistral/BioInstructQA):ポルトガル語部分
- **ロシア語**:[RuMedBench](https://github.com/sb-ai-lab/MedBench)
結果の再現
展開するにはクリック
Apollo2-7BまたはApollo-MoE-0.5Bを例に説明します。
1. プロジェクトのデータセットをダウンロードします。
```
bash 0.download_data.sh
```
2. 特定のモデルのテストデータと開発データを準備します。
```
bash 1.data_process_test&dev.sh
```
3. 特定のモデルの訓練データを準備します(事前にトークン化されたデータを作成します)。
```
bash 2.data_process_train.sh
```
4. モデルを訓練します。
```
bash 3.single_node_train.sh
```
5. モデルを評価します。
```
bash 4.eval.sh
```
🔧 技術詳細
元のモデルは、llama.cpp-b3938を使用して、Exllamav2のキャリブレーションデータセットに基づくimatrixファイルで量子化されています。
2024年12月17日:READMEを更新しました。最近のllama.cppでは、Q4_0_4_4、Q4_0_4_8、Q4_0_8_8のサポートが削除されたようです。これらを保持しますが、もはや有用でない可能性があります。
2025年2月3日:新しいllama.cppバージョンのARMデバイス用に、Q4_0_X_Y量子化の代わりにQ4_0とIQ4_NL量子化を追加しました。
📄 ライセンス
このモデルは、Apache-2.0ライセンスの下で提供されています。
📋 引用
データセットを訓練または評価に使用する場合は、以下の引用を使用してください。
@misc{zheng2024efficientlydemocratizingmedicalllms,
title={Efficiently Democratizing Medical LLMs for 50 Languages via a Mixture of Language Family Experts},
author={Guorui Zheng and Xidong Wang and Juhao Liang and Nuo Chen and Yuping Zheng and Benyou Wang},
year={2024},
eprint={2410.10626},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2410.10626},
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応