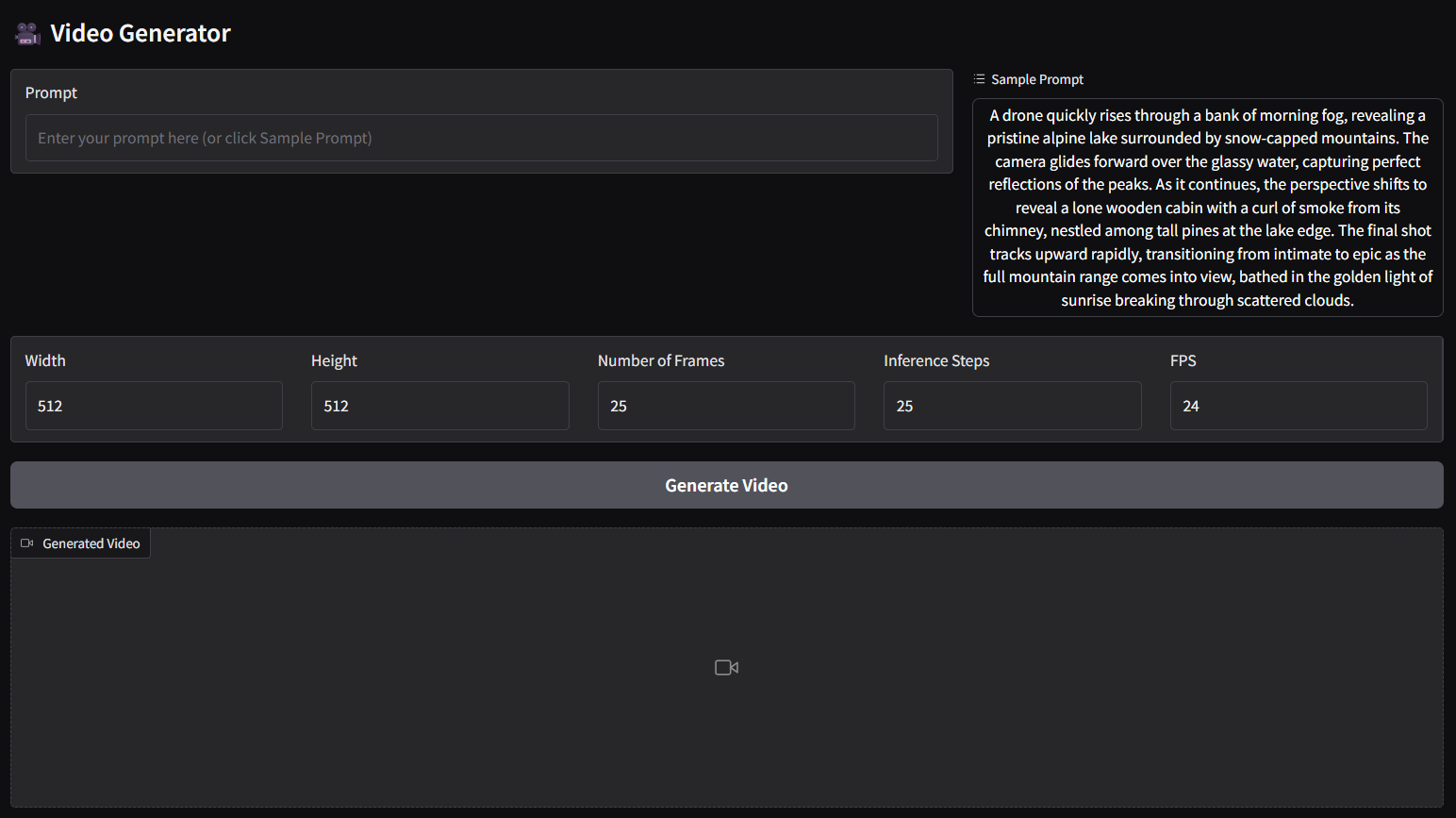
🚀 LTX-VideoのGGUF量子化およびfp8スケーリングバージョン

🚀 クイックスタート
セットアップ(一度だけ)
- ltx-video-2b-v0.9.1-r2-q4_0.gguf (1.09GB) を > ./ComfyUI/models/diffusion_models にドラッグします。
- t5xxl_fp16-q4_0.gguf (2.9GB) を > ./ComfyUI/models/text_encoders にドラッグします。
- ltxv_vae_fp32-f16.gguf (838MB) を > ./ComfyUI/models/vae にドラッグします。
直接実行(インストール不要な方法)
- メインディレクトリの .bat ファイルを実行します(以下の gguf-node パック を使用していると仮定します)。
- ワークフローのJSONファイル(以下)を > ブラウザにドラッグします。
ワークフロー
レビュー
q2_k gguf は非常に高速ですが、使用できません。テストのみに留めてください。- 意外なことに、
0.9_fp8_e4m3fn と 0.9-vae_fp8_e4m3fn はかなり良好に動作します。
- 混合使用が可能です。ここで利用可能な vae と異なるモデルファイルを組み合わせることができます。どの組み合わせが最適かをテストしてください。
- テキストエンコーダとして、t5xxl スケールの safetensors または t5xxl gguf を選択できます(t5xxl のより多くの量子化バージョンは こちら で見つけることができます)。
- このパックには、新しいセットの 拡張 vae(fp8 から fp32)が追加されています。低RAMバージョンの gguf vae もすぐに利用できます。新機能の gguf vae loader 用にノードをアップグレードしてください。
- gguf-node が利用可能です(詳細は こちら を参照)。新機能を実行するためのものです(以下のポイントはモデルに直接関係していない場合があります)。
- 新しいノードを介して、独自の
fp8_e4m3fn スケールの safetensors を作成し、gguf に変換することができます。
diffusers🧨 で実行(代替方法1)
import torch
from transformers import T5EncoderModel
from diffusers import LTXPipeline, GGUFQuantizationConfig, LTXVideoTransformer3DModel
from diffusers.utils import export_to_video
model_path = (
"https://huggingface.co/calcuis/ltxv-gguf/blob/main/ltx-video-2b-v0.9-q8_0.gguf"
)
transformer = LTXVideoTransformer3DModel.from_single_file(
model_path,
quantization_config=GGUFQuantizationConfig(compute_dtype=torch.bfloat16),
torch_dtype=torch.bfloat16,
)
text_encoder = T5EncoderModel.from_pretrained(
"calcuis/ltxv-gguf",
gguf_file="t5xxl_fp16-q4_0.gguf",
torch_dtype=torch.bfloat16,
)
pipe = LTXPipeline.from_pretrained(
"callgg/ltxv-decoder",
text_encoder=text_encoder,
transformer=transformer,
torch_dtype=torch.bfloat16
).to("cuda")
prompt = "A woman with long brown hair and light skin smiles at another woman with long blonde hair. The woman with brown hair wears a black jacket and has a small, barely noticeable mole on her right cheek. The camera angle is a close-up, focused on the woman with brown hair's face. The lighting is warm and natural, likely from the setting sun, casting a soft glow on the scene. The scene appears to be real-life footage"
negative_prompt = "worst quality, inconsistent motion, blurry, jittery, distorted"
video = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
width=704,
height=480,
num_frames=25,
num_inference_steps=50,
).frames[0]
export_to_video(video, "output.mp4", fps=24)
gguf-connector で実行(代替方法2)
- コンソール/ターミナルで以下のコマンドを実行します。
- 注意: 初回起動時には、モデルファイルが自動的にローカルキャッシュに取得されます。その後、完全にオフラインで実行することができます。つまり、ローカルURL: http://127.0.0.1:7860 で lazy webui を使用できます。
- ベースモデルを 0.9 から 0.9.6 蒸留版にアップグレードして、より良い結果を得ることができます。
ggc vg
- 上記のコマンドは、テキストからビデオ(t2v)パネル用です。
- 画像 - テキストからビデオ(i2v)パネルの場合は、以下のコマンドを実行してください。
ggc v1
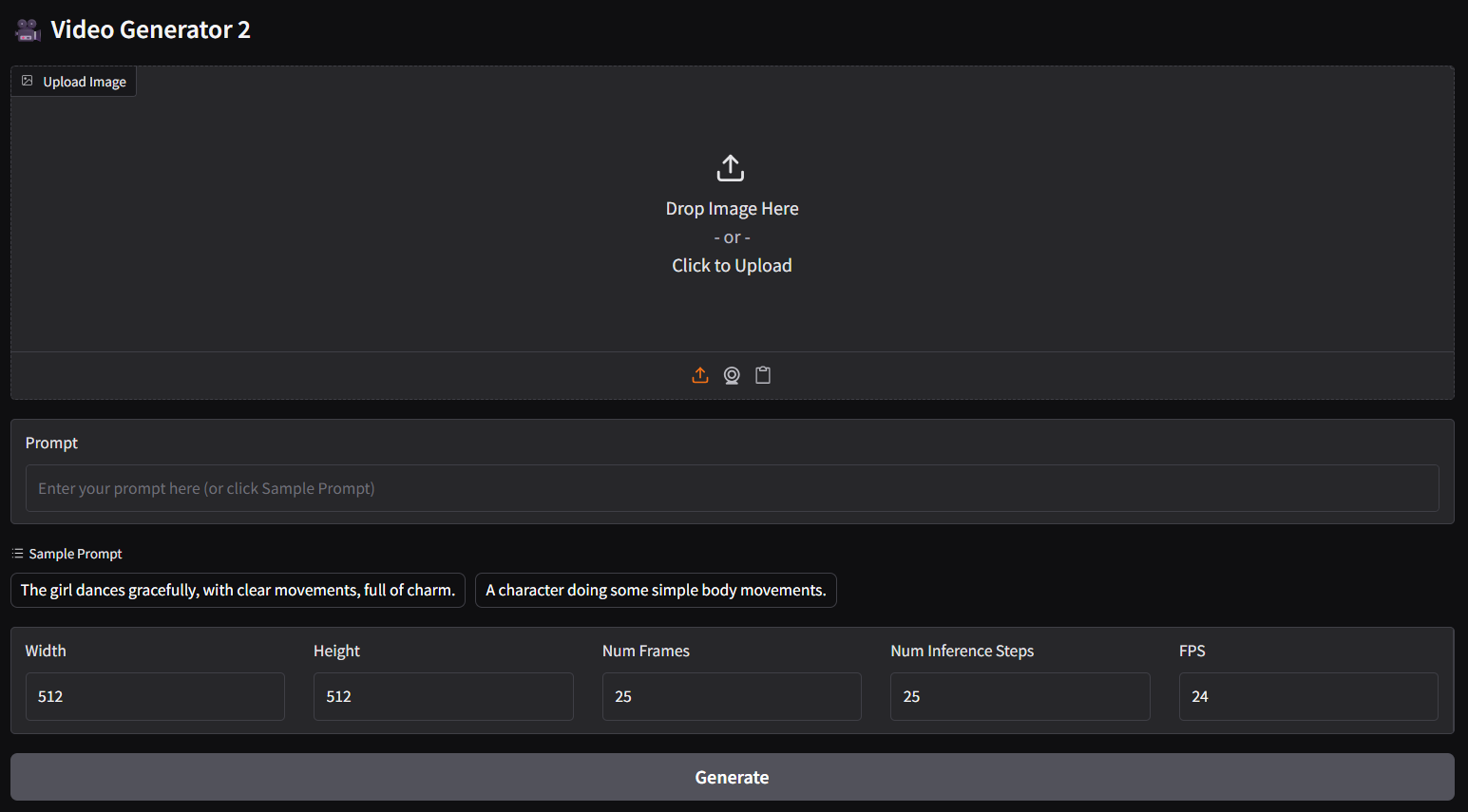
参考
📄 ライセンス
このプロジェクトは other ライセンスの下で提供されています。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応