🚀 GGUF quantized and fp8 scaled versions of LTX-Video
This project offers GGUF quantized and fp8 scaled versions of the LTX-Video model, enabling text-to-video, image-to-video, and video-to-video conversions. It provides multiple ways to run the model, including direct execution and integration with diffusers or gguf-connector.
🚀 Quick Start
✨ Setup (Once)
- Drag
ltx-video-2b-v0.9.1-r2-q4_0.gguf (1.09GB) to ./ComfyUI/models/diffusion_models.
- Drag
t5xxl_fp16-q4_0.gguf (2.9GB) to ./ComfyUI/models/text_encoders.
- Drag
ltxv_vae_fp32-f16.gguf (838MB) to ./ComfyUI/models/vae.
🏃♂️ Run it Straight (No Installation Needed Way)
- Run the
.bat file in the main directory (assuming you are using the gguf-node pack below).
- Drag the workflow json file (below) to your browser.
📄 Workflow
- Example workflow for gguf (see demo above).
- Example workflow for the original safetensors.
💻 Usage Examples
🐍 Run it with diffusers🧨 (Alternative 1)
import torch
from transformers import T5EncoderModel
from diffusers import LTXPipeline, GGUFQuantizationConfig, LTXVideoTransformer3DModel
from diffusers.utils import export_to_video
model_path = (
"https://huggingface.co/calcuis/ltxv-gguf/blob/main/ltx-video-2b-v0.9-q8_0.gguf"
)
transformer = LTXVideoTransformer3DModel.from_single_file(
model_path,
quantization_config=GGUFQuantizationConfig(compute_dtype=torch.bfloat16),
torch_dtype=torch.bfloat16,
)
text_encoder = T5EncoderModel.from_pretrained(
"calcuis/ltxv-gguf",
gguf_file="t5xxl_fp16-q4_0.gguf",
torch_dtype=torch.bfloat16,
)
pipe = LTXPipeline.from_pretrained(
"callgg/ltxv-decoder",
text_encoder=text_encoder,
transformer=transformer,
torch_dtype=torch.bfloat16
).to("cuda")
prompt = "A woman with long brown hair and light skin smiles at another woman with long blonde hair. The woman with brown hair wears a black jacket and has a small, barely noticeable mole on her right cheek. The camera angle is a close-up, focused on the woman with brown hair's face. The lighting is warm and natural, likely from the setting sun, casting a soft glow on the scene. The scene appears to be real-life footage"
negative_prompt = "worst quality, inconsistent motion, blurry, jittery, distorted"
video = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
width=704,
height=480,
num_frames=25,
num_inference_steps=50,
).frames[0]
export_to_video(video, "output.mp4", fps=24)
💻 Run it with gguf-connector (Alternative 2)
- Simply execute the command below in console/terminal.
- Note: During the first time launch, it will pull the model file(s) to local cache automatically; then opt to run it entirely offline; i.e., from local URL: http://127.0.0.1:7860 with lazy webui.
- Upgraded the base model from 0.9 to 0.9.6 distilled for better results.
ggc vg
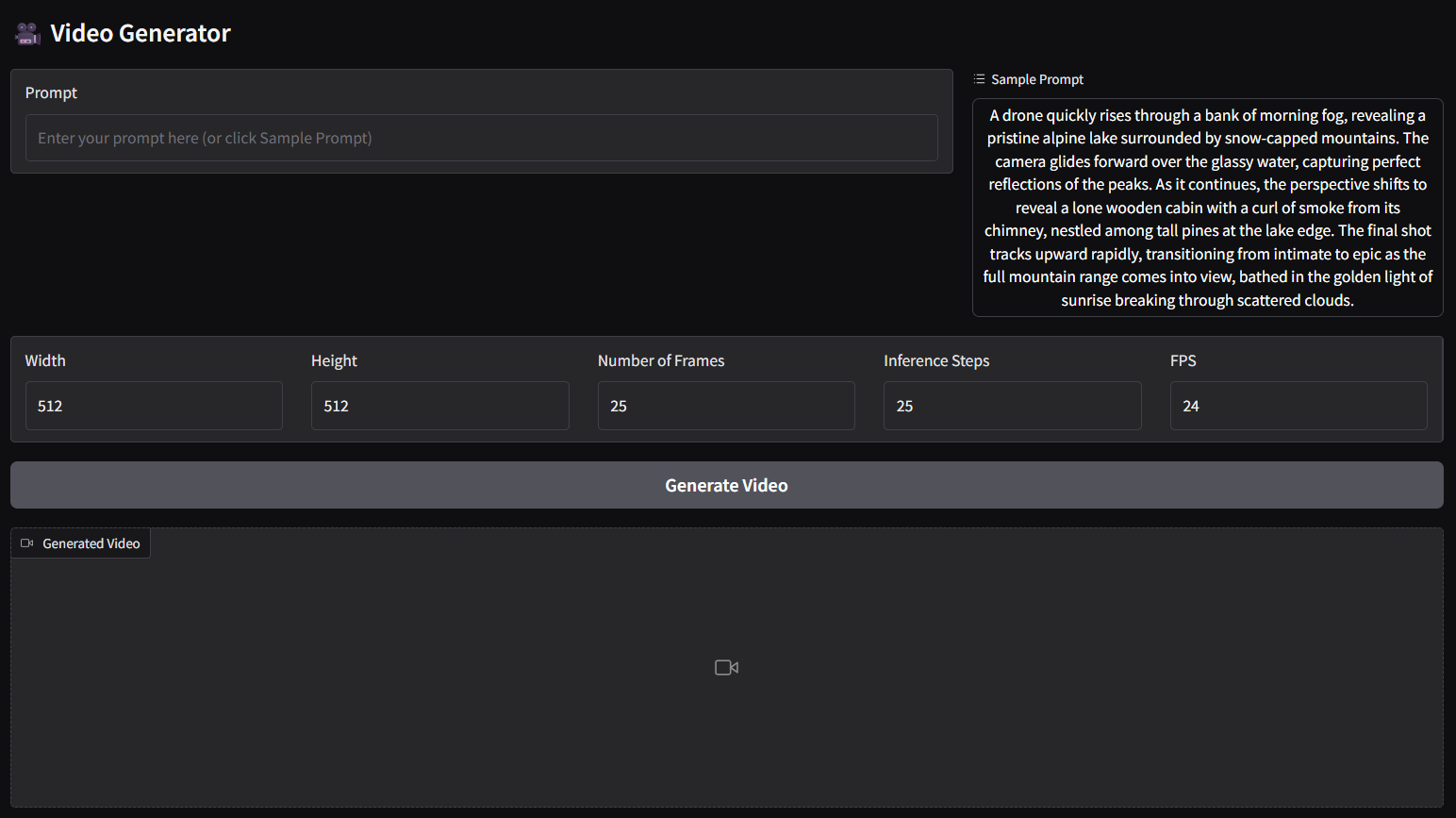
- The above command is for text to video (t2v) panel.
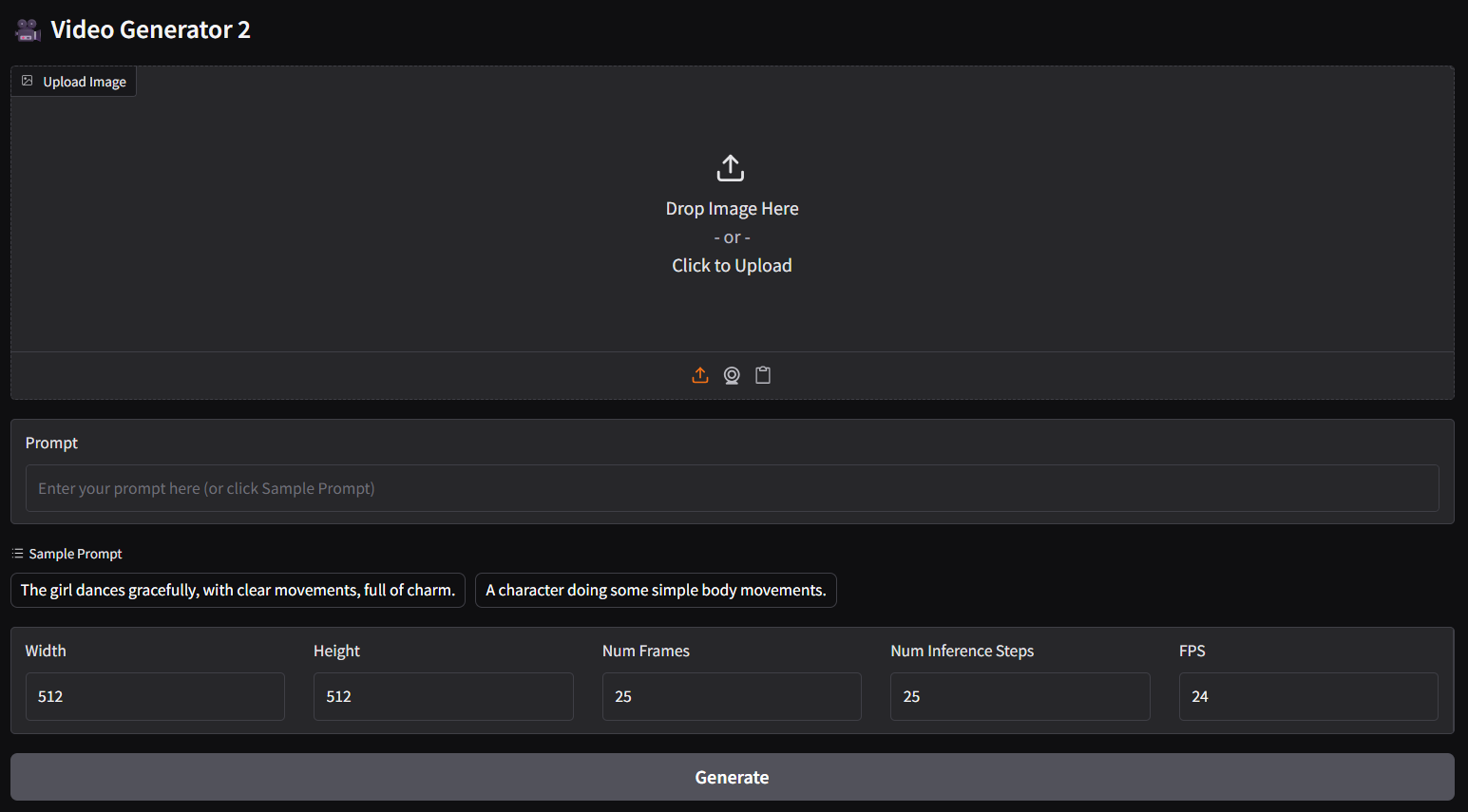
- For image-text to video (i2v) panel, please execute:
ggc v1
📚 Documentation
📋 Review
q2_k gguf is super fast but not usable; keep it for testing only.- Surprisingly
0.9_fp8_e4m3fn and 0.9-vae_fp8_e4m3fn are working pretty good.
- Mix-and-match possible; you could mix up using the vae(s) available with different model file(s) here; test which combination works best.
- You could opt to use the t5xxl scaled safetensors or t5xxl gguf (more quantized versions of t5xxl can be found here) as text encoder.
- New set of enhanced vae (from fp8 to fp32) added in this pack; the low ram version gguf vae is also available right away; upgrade your node for the new feature: gguf vae loader.
- gguf-node is available (see details here) for running the new features (the point below might not be directly related to the model).
- You are able to make your own
fp8_e4m3fn scaled safetensors and/or convert it to gguf with the new node via comfyui.
📖 Reference
📄 License
This project is licensed under the other license.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)