🚀 roberta-large-zeroshot-v2.0-c
このモデルは、Hugging Faceパイプラインを使用した効率的なゼロショット分類を目的として設計されています。学習データがなくても分類が可能で、GPUとCPUの両方で動作します。
🚀 クイックスタート
このモデルを使用することで、ゼロショット分類タスクを効率的に行うことができます。以下のセクションでは、モデルの詳細、学習データ、使用方法、メトリクスについて説明します。
✨ 主な機能
- ゼロショット分類:学習データがなくても分類が可能です。
- 汎用性:任意の分類タスクを自然言語推論タスクに変換して実行できます。
- 商用利用可能:一部のモデルは完全に商用利用可能なデータで学習されています。
📦 インストール
このモデルを使用するには、transformersライブラリが必要です。以下のコマンドでインストールできます。
💻 使用例
基本的な使用法
from transformers import pipeline
text = "Angela Merkel is a politician in Germany and leader of the CDU"
hypothesis_template = "This text is about {}"
classes_verbalized = ["politics", "economy", "entertainment", "environment"]
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-large-zeroshot-v2.0")
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=False)
print(output)
multi_label=False を設定すると、モデルは1つのクラスのみを選択します。multi_label=True を設定すると、複数のクラスを選択できます。
📚 ドキュメント
モデルの説明
zeroshot-v2.0シリーズのモデル
このシリーズのモデルは、Hugging Faceパイプラインを使用した効率的なゼロショット分類を目的として設計されています。これらのモデルは学習データがなくても分類が可能で、GPUとCPUの両方で動作します。最新のゼロショット分類器の概要は、Zeroshot Classifier Collection で確認できます。
zeroshot-v2.0 シリーズのモデルの主な更新点は、いくつかのモデルが厳格なライセンス要件を持つユーザー向けに、完全に商用利用可能なデータで学習されていることです。
これらのモデルは、1つの汎用的な分類タスクを実行できます。つまり、与えられたテキストに対して仮説が "true" または "not true" であるかを判断することができます (entailment vs. not_entailment)。このタスク形式は自然言語推論タスク (NLI) に基づいています。このタスクは非常に汎用的で、任意の分類タスクをHugging Faceパイプラインによってこのタスクに変換することができます。
学習データ
名前に "-c" が含まれるモデルは、2種類の完全に商用利用可能なデータで学習されています。
- Mixtral-8x7B-Instruct-v0.1 を使用して生成された合成データ。まず、Mistral-largeとの会話で25の職種に対する500以上の多様なテキスト分類タスクのリストを作成しました。このデータは手動で精選されました。その後、これをシードデータとして、Mixtral-8x7B-Instruct-v0.1を使用してこれらのタスクに対する数十万のテキストを生成しました。使用された最終的なデータセットは、synthetic_zeroshot_mixtral_v0.1 データセットのサブセット
mixtral_written_text_for_tasks_v4 で利用可能です。データの精選は複数回の反復で行われ、将来的な反復で改善されます。
- 2つの商用利用可能なNLIデータセット: (MNLI, FEVER-NLI)。これらのデータセットは汎化能力を向上させるために追加されました。
- 名前に "
-c" が含まれないモデルは、より広範なライセンスの学習データの混合物も含んでいます: ANLI、WANLI、LingNLI、および このリスト のすべてのデータセットで、used_in_v1.1==True のもの。
🔧 技術詳細
モデルは、f1_macro メトリクスを使用して28の異なるテキスト分類タスクで評価されました。主な参照ポイントは facebook/bart-large-mnli で、これは執筆時点 (2024年4月3日) で最も多く使用されている商用利用可能なゼロショット分類器です。
| Property |
Details |
| Model Type |
roberta-large-zeroshot-v2.0-c |
| Training Data |
名前に "-c" が含まれるモデルは、Mixtral-8x7B-Instruct-v0.1で生成された合成データと2つの商用利用可能なNLIデータセット (MNLI、FEVER-NLI) で学習されています。名前に "-c" が含まれないモデルは、より広範なライセンスの学習データの混合物も含んでいます。 |
メトリクス
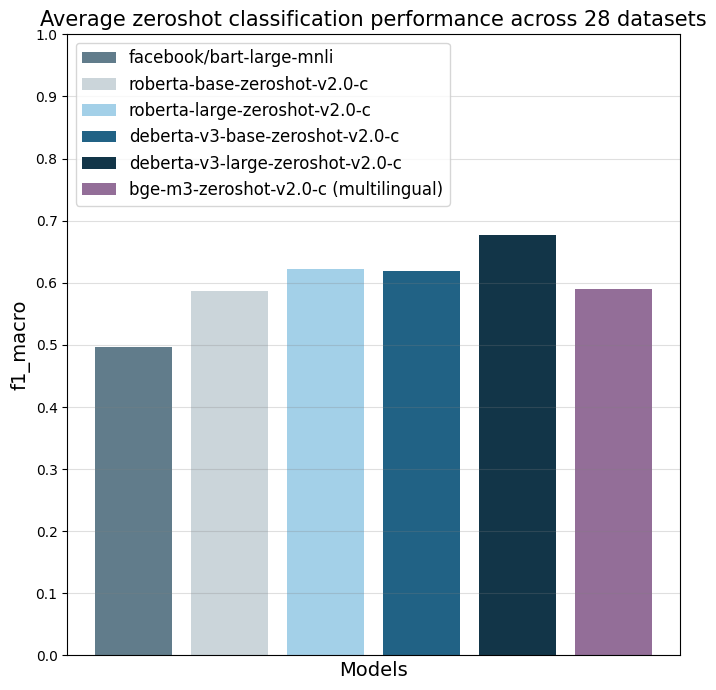
|
facebook/bart-large-mnli |
roberta-base-zeroshot-v2.0-c |
roberta-large-zeroshot-v2.0-c |
deberta-v3-base-zeroshot-v2.0-c |
deberta-v3-base-zeroshot-v2.0 (fewshot) |
deberta-v3-large-zeroshot-v2.0-c |
deberta-v3-large-zeroshot-v2.0 (fewshot) |
bge-m3-zeroshot-v2.0-c |
bge-m3-zeroshot-v2.0 (fewshot) |
| all datasets mean |
0.497 |
0.587 |
0.622 |
0.619 |
0.643 (0.834) |
0.676 |
0.673 (0.846) |
0.59 |
(0.803) |
| amazonpolarity (2) |
0.937 |
0.924 |
0.951 |
0.937 |
0.943 (0.961) |
0.952 |
0.956 (0.968) |
0.942 |
(0.951) |
| imdb (2) |
0.892 |
0.871 |
0.904 |
0.893 |
0.899 (0.936) |
0.923 |
0.918 (0.958) |
0.873 |
(0.917) |
| appreviews (2) |
0.934 |
0.913 |
0.937 |
0.938 |
0.945 (0.948) |
0.943 |
0.949 (0.962) |
0.932 |
(0.954) |
| yelpreviews (2) |
0.948 |
0.953 |
0.977 |
0.979 |
0.975 (0.989) |
0.988 |
0.985 (0.994) |
0.973 |
(0.978) |
| rottentomatoes (2) |
0.83 |
0.802 |
0.841 |
0.84 |
0.86 (0.902) |
0.869 |
0.868 (0.908) |
0.813 |
(0.866) |
| emotiondair (6) |
0.455 |
0.482 |
0.486 |
0.459 |
0.495 (0.748) |
0.499 |
0.484 (0.688) |
0.453 |
(0.697) |
| emocontext (4) |
0.497 |
0.555 |
0.63 |
0.59 |
0.592 (0.799) |
0.699 |
0.676 (0.81) |
0.61 |
(0.798) |
| empathetic (32) |
0.371 |
0.374 |
0.404 |
0.378 |
0.405 (0.53) |
0.447 |
0.478 (0.555) |
0.387 |
(0.455) |
| financialphrasebank (3) |
0.465 |
0.562 |
0.455 |
0.714 |
0.669 (0.906) |
0.691 |
0.582 (0.913) |
0.504 |
(0.895) |
| banking77 (72) |
0.312 |
0.124 |
0.29 |
0.421 |
0.446 (0.751) |
0.513 |
0.567 (0.766) |
0.387 |
(0.715) |
| massive (59) |
0.43 |
0.428 |
0.543 |
0.512 |
0.52 (0.755) |
0.526 |
0.518 (0.789) |
0.414 |
(0.692) |
| wikitoxic_toxicaggreg (2) |
0.547 |
0.751 |
0.766 |
0.751 |
0.769 (0.904) |
0.741 |
0.787 (0.911) |
0.736 |
(0.9) |
| wikitoxic_obscene (2) |
0.713 |
0.817 |
0.854 |
0.853 |
0.869 (0.922) |
0.883 |
0.893 (0.933) |
0.783 |
(0.914) |
| wikitoxic_threat (2) |
0.295 |
0.71 |
0.817 |
0.813 |
0.87 (0.946) |
0.827 |
0.879 (0.952) |
0.68 |
(0.947) |
| wikitoxic_insult (2) |
0.372 |
0.724 |
0.798 |
0.759 |
0.811 (0.912) |
0.77 |
0.779 (0.924) |
0.783 |
(0.915) |
| wikitoxic_identityhate (2) |
0.473 |
0.774 |
0.798 |
0.774 |
0.765 (0.938) |
0.797 |
0.806 (0.948) |
0.761 |
(0.931) |
| hateoffensive (3) |
0.161 |
0.352 |
0.29 |
0.315 |
0.371 (0.862) |
0.47 |
0.461 (0.847) |
0.291 |
(0.823) |
| hatexplain (3) |
0.239 |
0.396 |
0.314 |
0.376 |
0.369 (0.765) |
0.378 |
0.389 (0.764) |
0.29 |
(0.729) |
| biasframes_offensive (2) |
0.336 |
0.571 |
0.583 |
0.544 |
0.601 (0.867) |
0.644 |
0.656 (0.883) |
0.541 |
(0.855) |
| biasframes_sex (2) |
0.263 |
0.617 |
0.835 |
0.741 |
0.809 (0.922) |
0.846 |
0.815 (0.946) |
0.748 |
(0.905) |
| biasframes_intent (2) |
0.616 |
0.531 |
0.635 |
0.554 |
0.61 (0.881) |
0.696 |
0.687 (0.891) |
0.467 |
(0.868) |
| agnews (4) |
0.703 |
0.758 |
0.745 |
0.68 |
0.742 (0.898) |
0.819 |
0.771 (0.898) |
0.687 |
(0.892) |
| yahootopics (10) |
0.299 |
0.543 |
0.62 |
0.578 |
0.564 (0.722) |
0.621 |
0.613 (0.738) |
0.587 |
(0.711) |
| trueteacher (2) |
0.491 |
0.469 |
0.402 |
0.431 |
0.479 (0.82) |
0.459 |
0.538 (0.846) |
0.471 |
(0.518) |
| spam (2) |
0.505 |
0.528 |
0.504 |
0.507 |
0.464 (0.973) |
0.74 |
0.597 (0.983) |
0.441 |
(0.978) |
| wellformedquery (2) |
0.407 |
0.333 |
0.333 |
0.335 |
0.491 (0.769) |
0.334 |
0.429 (0.815) |
0.361 |
(0.718) |
| manifesto (56) |
0.084 |
0.102 |
0.182 |
0.17 |
0.187 (0.376) |
0.258 |
0.256 (0.408) |
0.147 |
(0.331) |
| capsotu (21) |
0.34 |
0.479 |
0.523 |
0.502 |
0.477 (0.664) |
0.603 |
0.502 (0.686) |
0.472 |
(0.644) |
これらの数値はゼロショット性能を示しており、学習データにはこれらのデータセットのデータは含まれていません。名前に "-c" が含まれないモデルは2回評価されています。1回目はこれらの28のデータセットのデータを一切使用せずに純粋なゼロショット性能をテストしています (表の最初の数値)。
📄 ライセンス
このモデルはMITライセンスの下で提供されています。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応