🚀 BERT (base-multilingual-cased) 多言語Q&A用にファインチューニングされたモデル
このモデルはGoogleによって作成され、XQuADのようなデータを使用して、多言語(11種類の異なる言語)のQ&A下流タスクに対してファインチューニングされました。
📚 言語モデル('bert-base-multilingual-cased')の詳細
言語モデル
| 言語数 |
ヘッド数 |
レイヤー数 |
隠れ層サイズ |
パラメータ数 |
| 104 |
12 |
12 |
768 |
100 M |
📊 下流タスク(多言語Q&A) - データセットの詳細
DeepmindのXQuAD
対象言語:
- アラビア語:
ar
- ドイツ語:
de
- ギリシャ語:
el
- 英語:
en
- スペイン語:
es
- ヒンディー語:
hi
- ロシア語:
ru
- タイ語:
th
- トルコ語:
tr
- ベトナム語:
vi
- 中国語:
zh
このデータセットはSQuAD v1.1に基づいているため、データには回答不能な質問はありません。この設定を選んだのは、モデルがクロスリンガルな転移学習に集中できるようにするためです。
以下の表に、各言語の段落、質問、回答あたりの平均トークン数を示します。統計は、中国語にはJiebaを、その他の言語にはMosesトークナイザーを使用して取得しました。
|
en |
es |
de |
el |
ru |
tr |
ar |
vi |
th |
zh |
hi |
| 段落 |
142.4 |
160.7 |
139.5 |
149.6 |
133.9 |
126.5 |
128.2 |
191.2 |
158.7 |
147.6 |
232.4 |
| 質問 |
11.5 |
13.4 |
11.0 |
11.7 |
10.0 |
9.8 |
10.7 |
14.8 |
11.5 |
10.5 |
18.7 |
| 回答 |
3.1 |
3.6 |
3.0 |
3.3 |
3.1 |
3.1 |
3.1 |
4.5 |
4.1 |
3.5 |
5.6 |
引用:
@article{Artetxe:etal:2019,
author = {Mikel Artetxe and Sebastian Ruder and Dani Yogatama},
title = {On the cross-lingual transferability of monolingual representations},
journal = {CoRR},
volume = {abs/1910.11856},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.11856}
}
XQuADは評価用のデータセットに過ぎないため、データ拡張技術(スクレイピング、ニューラル機械翻訳など)を使用してより多くのサンプルを取得し、データセットを分割して訓練セットとテストセットを作成しました。テストセットは、各言語のサンプル数が同じになるように作成されました。最終的に、以下のようなサンプル数を得ました。
| データセット |
サンプル数 |
| XQUAD訓練セット |
50 K |
| XQUADテストセット |
8 K |
🔧 モデルの訓練
このモデルは、Tesla P100 GPUと25GBのRAMを使用して訓練されました。
ファインチューニング用のスクリプトはこちらで確認できます。
💻 モデルの実行例
パイプラインを使用した高速な使い方:
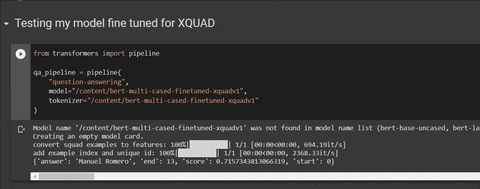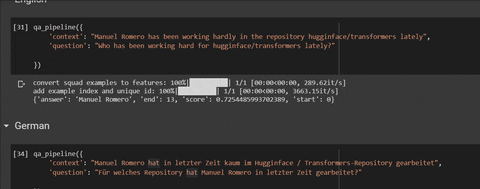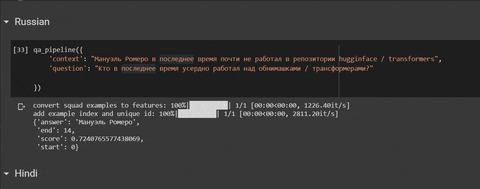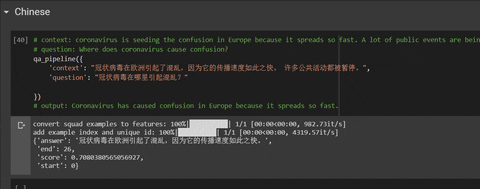
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="mrm8488/bert-multi-cased-finetuned-xquadv1",
tokenizer="mrm8488/bert-multi-cased-finetuned-xquadv1"
)
qa_pipeline({
'context': "कोरोनावायरस पश्चिम में आतंक बो रहा है क्योंकि यह इतनी तेजी से फैलता है।",
'question': "कोरोनावायरस घबराहट कहां है?"
})
qa_pipeline({
'context': "Manuel Romero has been working hardly in the repository hugginface/transformers lately",
'question': "Who has been working hard for hugginface/transformers lately?"
})
qa_pipeline({
'context': "Manuel Romero a travaillé à peine dans le référentiel hugginface / transformers ces derniers temps",
'question': "Pour quel référentiel a travaillé Manuel Romero récemment?"
})
Colabで試してみる:

作成者: Manuel Romero/@mrm8488
スペインで❤️を込めて作成されました
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応