🚀 BERT (base-multilingual-cased) 針對多語言問答的微調模型
本模型由 Google 創建,並在類似 XQuAD 的數據集上進行微調,以用於多語言(11 種不同語言)的問答下游任務。該模型能夠有效解決多語言環境下的問答需求,為不同語言的用戶提供準確的答案。
📚 詳細文檔
語言模型('bert-base-multilingual-cased')詳情
語言模型
| 語言數量 |
注意力頭數量 |
層數 |
隱藏層維度 |
參數數量 |
| 104 |
12 |
12 |
768 |
1 億 |
下游任務(多語言問答)詳情 - 數據集
Deepmind XQuAD
涵蓋的語言:
- 阿拉伯語:
ar
- 德語:
de
- 希臘語:
el
- 英語:
en
- 西班牙語:
es
- 印地語:
hi
- 俄語:
ru
- 泰語:
th
- 土耳其語:
tr
- 越南語:
vi
- 中文:
zh
由於該數據集基於 SQuAD v1.1,數據中沒有無法回答的問題。我們選擇這種設置是為了讓模型能夠專注於跨語言遷移。
我們在下表中展示了每種語言每個段落、問題和答案的平均標記數。中文使用 Jieba 進行統計,其他語言使用 Moses 分詞器 進行統計。
|
英語 |
西班牙語 |
德語 |
希臘語 |
俄語 |
土耳其語 |
阿拉伯語 |
越南語 |
泰語 |
中文 |
印地語 |
| 段落 |
142.4 |
160.7 |
139.5 |
149.6 |
133.9 |
126.5 |
128.2 |
191.2 |
158.7 |
147.6 |
232.4 |
| 問題 |
11.5 |
13.4 |
11.0 |
11.7 |
10.0 |
9.8 |
10.7 |
14.8 |
11.5 |
10.5 |
18.7 |
| 答案 |
3.1 |
3.6 |
3.0 |
3.3 |
3.1 |
3.1 |
3.1 |
4.5 |
4.1 |
3.5 |
5.6 |
引用:
@article{Artetxe:etal:2019,
author = {Mikel Artetxe and Sebastian Ruder and Dani Yogatama},
title = {On the cross-lingual transferability of monolingual representations},
journal = {CoRR},
volume = {abs/1910.11856},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.11856}
}
由於 XQuAD 只是一個評估數據集,我使用了 數據增強技術(網絡抓取、神經機器翻譯等)來獲取更多樣本,並對數據集進行分割,以得到訓練集和測試集。測試集的創建方式是每種語言包含相同數量的樣本。最後,我得到了:
| 數據集 |
樣本數量 |
| XQUAD 訓練集 |
5 萬個 |
| XQUAD 測試集 |
8 千個 |
模型訓練
該模型在 Tesla P100 GPU 和 25GB 內存上進行訓練。
微調腳本可在 此處 找到。
💻 使用示例
基礎用法
使用 pipelines 快速使用:
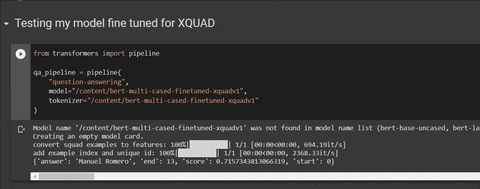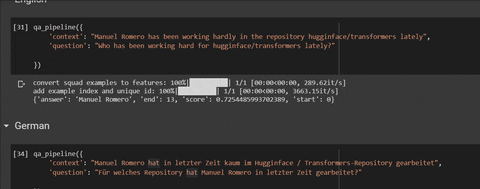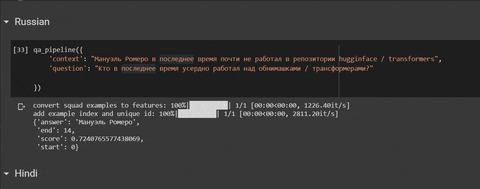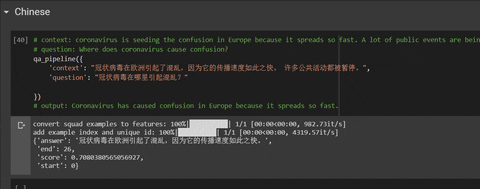
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="mrm8488/bert-multi-cased-finetuned-xquadv1",
tokenizer="mrm8488/bert-multi-cased-finetuned-xquadv1"
)
qa_pipeline({
'context': "कोरोनावायरस पश्चिम में आतंक बो रहा है क्योंकि यह इतनी तेजी से फैलता है।",
'question': "कोरोनावायरस घबराहट कहां है?"
})
qa_pipeline({
'context': "Manuel Romero has been working hardly in the repository hugginface/transformers lately",
'question': "Who has been working hard for hugginface/transformers lately?"
})
qa_pipeline({
'context': "Manuel Romero a travaillé à peine dans le référentiel hugginface / transformers ces derniers temps",
'question': "Pour quel référentiel a travaillé Manuel Romero récemment?"
})
你可以在 Colab 中嘗試:

由 Manuel Romero/@mrm8488 創建
在西班牙用心打造
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多種語言
Transformers 支持多種語言