%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
モデル概要
モデル特徴
モデル能力
使用事例
🚀 Distil-Whisper: distil-medium.en
Distil-Whisperは、論文Robust Knowledge Distillation via Large-Scale Pseudo Labellingで提案されたモデルです。 これはWhisperモデルの蒸留バージョンで、6倍高速で、サイズが49%小さく、分布外評価セットでWERが1%以内の性能を発揮します。このリポジトリは、Whisper medium.enの蒸留バリアントであるdistil-medium.en用のものです。
🚀 クイックスタート
このセクションでは、Distil-Whisperを使い始めるための基本的な手順を説明します。
✨ 主な機能
- Distil-Whisperは、Whisperモデルの蒸留バージョンで、6倍高速で、サイズが49%小さく、分布外評価セットでWERが1%以内の性能を発揮します。
- 短い音声ファイル(30秒未満)と長い音声ファイル(30秒以上)の両方を文字起こしできます。
- 推論的デコードを使用することで、Whisperと同じ出力を保証しながら2倍高速になります。
📦 インストール
Distil-Whisperは、Hugging Face 🤗 Transformersのバージョン4.35以降でサポートされています。モデルを実行するには、まずTransformersライブラリの最新バージョンをインストールします。この例では、🤗 Datasetsもインストールして、Hugging Face Hubから玩具用の音声データセットをロードします。
pip install --upgrade pip
pip install --upgrade transformers accelerate datasets[audio]
💻 使用例
基本的な使用法
短い音声ファイルの文字起こし
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-medium.en"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
ローカルの音声ファイルを文字起こしするには、パイプラインを呼び出すときに音声ファイルのパスを渡します。
- result = pipe(sample)
+ result = pipe("audio.mp3")
長い音声ファイルの文字起こし
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-medium.en"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
chunk_length_s=15,
batch_size=16,
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("distil-whisper/librispeech_long", "default", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
推論的デコード
from transformers import pipeline, AutoModelForCausalLM, AutoModelForSpeechSeq2Seq, AutoProcessor
import torch
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
assistant_model_id = "distil-whisper/distil-medium.en"
assistant_model = AutoModelForCausalLM.from_pretrained(
assistant_model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
assistant_model.to(device)
model_id = "openai/whisper-medium.en"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
generate_kwargs={"assistant_model": assistant_model},
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
高度な使用法
Flash Attentionを使用する
pip install flash-attn --no-build-isolation
- model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True)
+ model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True, use_flash_attention_2=True)
Torch Scale-Product-Attention (SDPA)を使用する
pip install --upgrade optimum
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True)
+ model = model.to_bettertransformer()
openai-whisperで実行する
pip install --upgrade openai-whisper
import torch
from datasets import load_dataset
from huggingface_hub import hf_hub_download
from whisper import load_model, transcribe
medium_en = hf_hub_download(repo_id="distil-whisper/distil-medium.en", filename="original-model.bin")
model = load_model(medium_en)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[0]["audio"]["array"]
sample = torch.from_numpy(sample).float()
pred_out = transcribe(model, audio=sample)
print(pred_out["text"])
ローカルの音声ファイルを文字起こしするには、transcribeに音声ファイルのパスを渡します。
pred_out = transcribe(model, audio="audio.mp3")
Whisper.cppで実行する
git clone https://github.com/ggerganov/whisper.cpp.git
cd whisper.cpp
python -c "from huggingface_hub import hf_hub_download; hf_hub_download(repo_id='distil-whisper/distil-medium.en', filename='ggml-medium-32-2.en.bin', local_dir='./models')"
wget https://huggingface.co/distil-whisper/distil-medium.en/resolve/main/ggml-medium-32-2.en.bin -P ./models
make -j && ./main -m models/ggml-medium-32-2.en.bin -f samples/jfk.wav
Transformers.jsで実行する
import { pipeline } from '@xenova/transformers';
let transcriber = await pipeline('automatic-speech-recognition', 'distil-whisper/distil-medium.en');
let url = 'https://huggingface.co/datasets/Xenova/transformers.js-docs/resolve/main/jfk.wav';
let output = await transcriber(url);
// { text: " And so my fellow Americans, ask not what your country can do for you. Ask what you can do for your country." }
Candleで実行する
git clone https://github.com/huggingface/candle.git
cd candle/candle-examples/examples/whisper
cargo run --example whisper --release -- --model distil-medium.en
cargo run --example whisper --release -- --model distil-medium.en --input audio.wav
📚 詳細ドキュメント
モデルの詳細
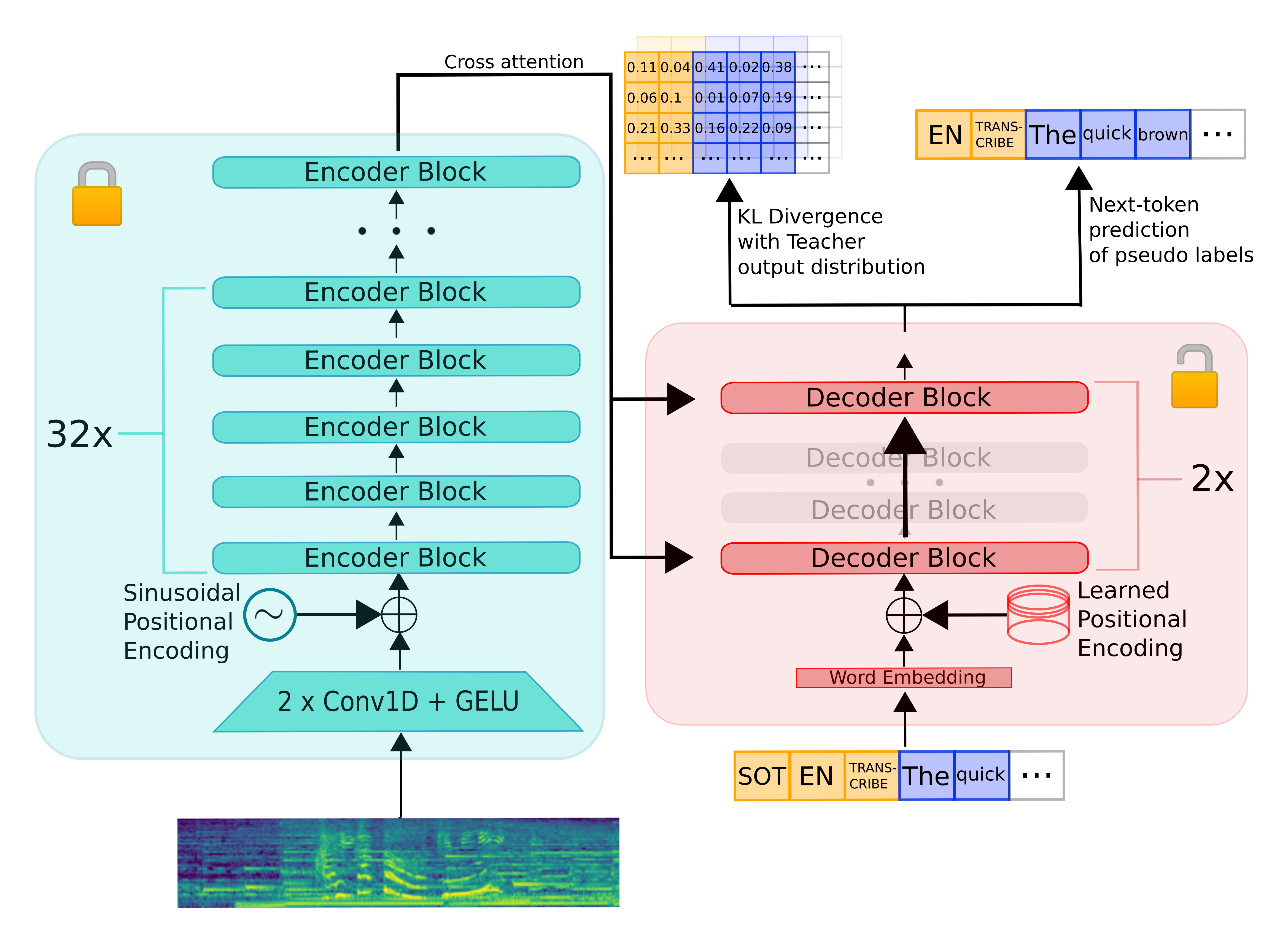
Distil-Whisperは、Whisperからエンコーダー・デコーダーアーキテクチャを継承しています。エンコーダーは音声ベクトル入力のシーケンスを隠れ状態ベクトルのシーケンスにマッピングします。デコーダーは、すべての前のトークンとエンコーダーの隠れ状態に条件付けられたテキストトークンを自己回帰的に予測します。したがって、エンコーダーは一度だけ前方実行され、デコーダーは生成されるトークンの数だけ実行されます。実際には、これはデコーダーが総推論時間の90%以上を占めることを意味します。したがって、レイテンシを最適化するには、デコーダーの推論時間を最小化することに焦点を当てる必要があります。
Whisperモデルを蒸留するために、エンコーダーを固定したままデコーダーのレイヤー数を減らします。エンコーダー(緑色で表示)は教師モデルから学生モデルに完全にコピーされ、学習中は凍結されます。学生のデコーダーは2つのデコーダーレイヤーのみから構成され、教師の最初と最後のデコーダーレイヤーから初期化されます(赤色で表示)。教師の他のすべてのデコーダーレイヤーは破棄されます。その後、モデルはKLダイバージェンスと疑似ラベル損失項の加重和で学習されます。
評価
以下のコードスニペットは、Distil-WhisperモデルをLibriSpeech validation.cleanデータセットで評価する方法を示しています。ストリーミングモードを使用することで、音声データをローカルデバイスにダウンロードする必要はありません。
🔧 技術詳細
Distil-Whisperは、Whisperモデルの蒸留バージョンで、エンコーダー・デコーダーアーキテクチャを採用しています。エンコーダーは音声ベクトル入力を隠れ状態ベクトルにマッピングし、デコーダーはそれらの隠れ状態を使ってテキストトークンを予測します。モデルを蒸留する際には、エンコーダーを固定し、デコーダーのレイヤー数を減らすことで、モデルのサイズを縮小し、推論速度を向上させています。
📄 ライセンス
このプロジェクトはMITライセンスの下で公開されています。