🚀 FLAN - T5 XXLのモデルカード
FLAN - T5 XXLは、T5モデルをベースに、1000以上の追加タスクでファインチューニングされた言語モデルです。同じパラメータ数で、様々な言語に対応し、ゼロショットやフィーショット学習タスクで優れた性能を発揮します。
🚀 クイックスタート
このセクションでは、FLAN - T5 XXLモデルの概要と使用方法について説明します。
✨ 主な機能
- 多言語対応:英語、ドイツ語、フランス語など、複数の言語に対応しています。
- 多様なタスク対応:文章生成、質問応答、論理推論、数学的推論など、様々なタスクに対応しています。
📦 インストール
transformersライブラリを使用して、FLAN - T5 XXLモデルを簡単にインストールできます。必要な依存関係をインストールしてください。
pip install transformers
💻 使用例
基本的な使用法
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-xxl")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xxl")
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
高度な使用法
GPUでの実行
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-xxl")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xxl", device_map="auto")
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
異なる精度でGPUで実行 - FP16
import torch
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-xxl")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xxl", device_map="auto", torch_dtype=torch.float16)
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
異なる精度でGPUで実行 - INT8
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-xxl")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xxl", device_map="auto", load_in_8bit=True)
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
📚 ドキュメント
モデルの詳細
| 属性 |
詳情 |
| モデルタイプ |
言語モデル |
| 言語 |
英語、ドイツ語、フランス語 |
| ライセンス |
Apache - 2.0 |
| 関連モデル |
[All FLAN - T5 Checkpoints](https://huggingface.co/models?search=flan - t5) |
| オリジナルチェックポイント |
[All Original FLAN - T5 Checkpoints](https://github.com/google - research/t5x/blob/main/docs/models.md#flan - t5 - checkpoints) |
| 詳細情報リソース |
Research paper、[GitHub Repo](https://github.com/google - research/t5x)、Hugging Face FLAN - T5 Docs (Similar to T5) |
使用目的
直接使用と下流使用
モデルの主な使用目的は、言語モデルの研究です。ゼロショットNLPタスクやコンテキスト内のフィーショット学習NLPタスク(推論、質問応答など)の研究、公正性と安全性の研究の推進、および現在の大規模言語モデルの制限の理解が含まれます。詳細はresearch paperを参照してください。
範囲外の使用
詳細情報は必要です。
バイアス、リスク、および制限
倫理的考慮事項とリスク
Flan - T5は、明示的なコンテンツについてフィルタリングされていない、または既存のバイアスについて評価されていない大量のテキストデータでファインチューニングされています。その結果、モデル自体は、同等に不適切なコンテンツを生成したり、基盤となるデータに内在するバイアスを複製したりする可能性があります。
既知の制限
Flan - T5は、実世界のアプリケーションでテストされていません。
敏感な使用
Flan - T5は、許容できないユースケース(例:虐待的なスピーチの生成)には適用しないでください。
トレーニングの詳細
トレーニングデータ
モデルは、以下の表に記載されているタスクを含むタスクの混合物でトレーニングされています(元の論文、図2より)。
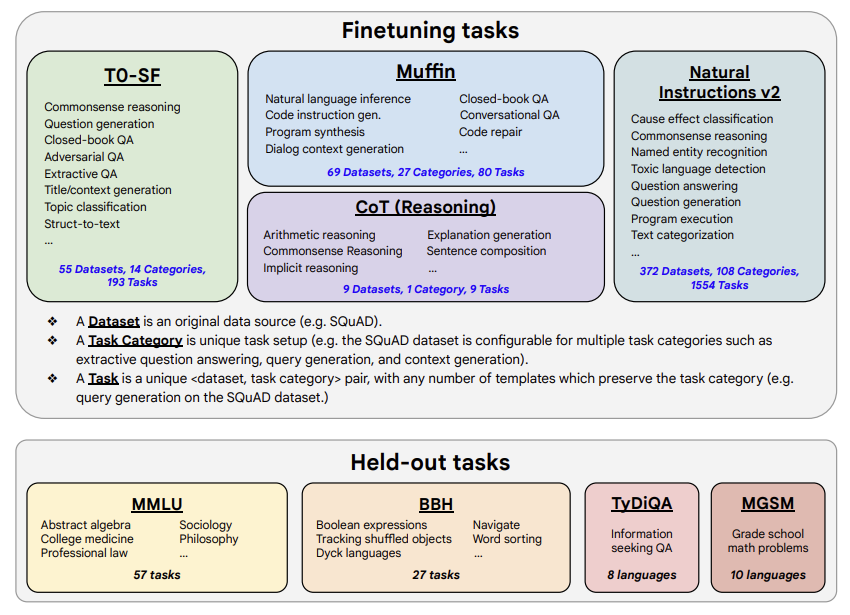
トレーニング手順
これらのモデルは、事前学習されたT5(Raffel et al., 2020)をベースに、ゼロショットとフィーショット性能を向上させるために命令でファインチューニングされています。T5モデルのサイズごとに1つのファインチューニングされたFlanモデルがあります。モデルは、TPU v3またはTPU v4ポッドで、[t5x](https://github.com/google - research/t5x)コードベースとjaxを使用してトレーニングされています。
評価
テストデータ、要因、およびメトリクス
著者らは、様々な言語(合計1836種類)をカバーする様々なタスクでモデルを評価しました。定量的評価の一部については、以下の表を参照してください。
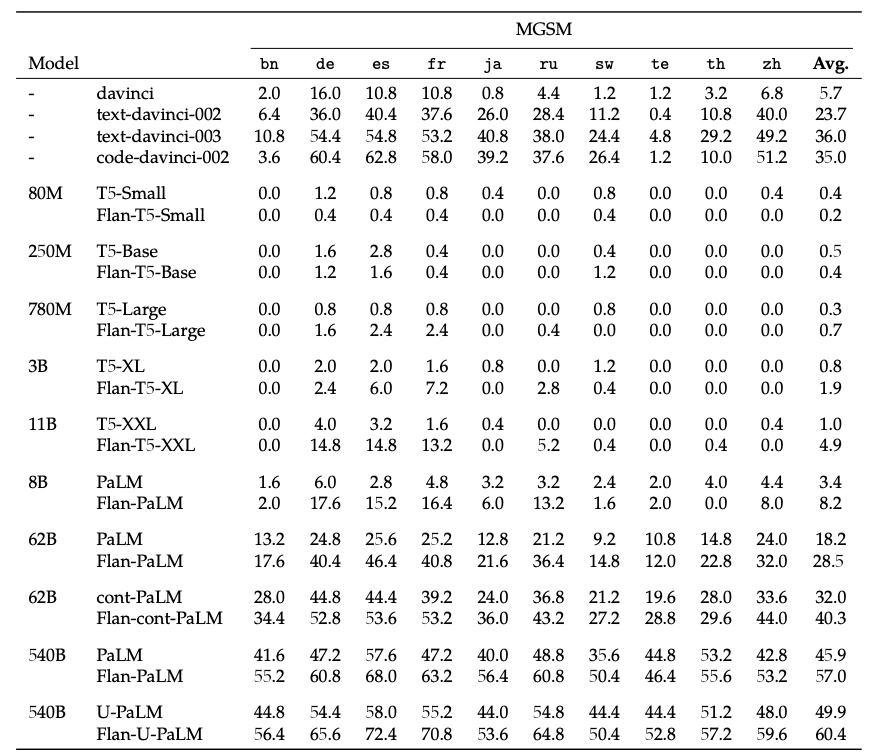 詳細については、research paperを確認してください。
詳細については、research paperを確認してください。
結果
FLAN - T5 - XXLの完全な結果については、research paperの表3を参照してください。
環境への影響
炭素排出量は、Lacoste et al. (2019)で提示されたMachine Learning Impact calculatorを使用して推定できます。
- ハードウェアタイプ:Google Cloud TPU Pods - TPU v3またはTPU v4 | チップ数 ≥ 4。
- 使用時間:詳細情報は必要です。
- クラウドプロバイダー:GCP
- コンピュートリージョン:詳細情報は必要です。
- 排出された炭素量:詳細情報は必要です。
引用
BibTeX:
@misc{https://doi.org/10.48550/arxiv.2210.11416,
doi = {10.48550/ARXIV.2210.11416},
url = {https://arxiv.org/abs/2210.11416},
author = {Chung, Hyung Won and Hou, Le and Longpre, Shayne and Zoph, Barret and Tay, Yi and Fedus, William and Li, Eric and Wang, Xuezhi and Dehghani, Mostafa and Brahma, Siddhartha and Webson, Albert and Gu, Shixiang Shane and Dai, Zhuyun and Suzgun, Mirac and Chen, Xinyun and Chowdhery, Aakanksha and Narang, Sharan and Mishra, Gaurav and Yu, Adams and Zhao, Vincent and Huang, Yanping and Dai, Andrew and Yu, Hongkun and Petrov, Slav and Chi, Ed H. and Dean, Jeff and Devlin, Jacob and Roberts, Adam and Zhou, Denny and Le, Quoc V. and Wei, Jason},
keywords = {Machine Learning (cs.LG), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Scaling Instruction-Finetuned Language Models},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
📄 ライセンス
このモデルは、Apache - 2.0ライセンスの下で提供されています。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応