🚀 ERNIE-Code
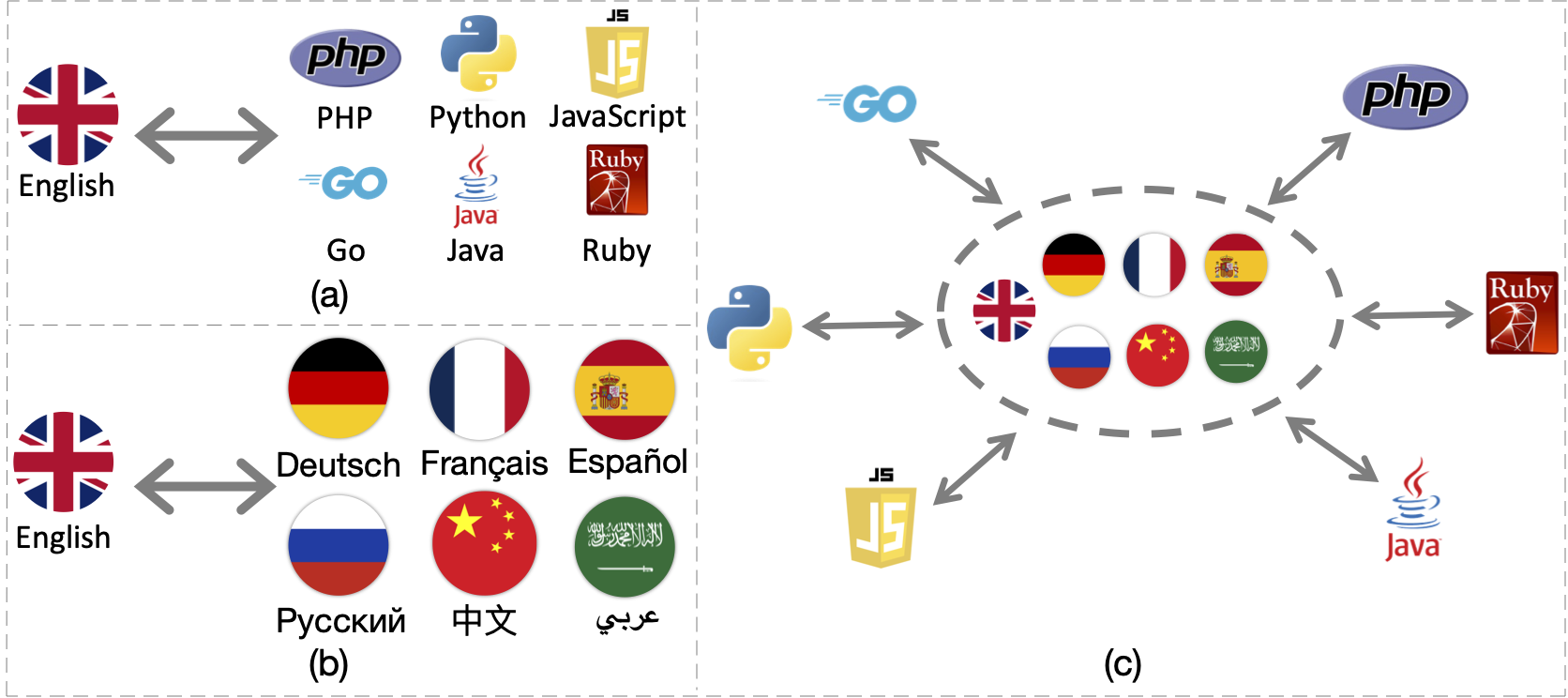
ERNIE-Codeは、116の自然言語と6つのプログラミング言語をつなぐ統一型大規模言語モデル(LLM)です。広範なコードインテリジェンスのエンドタスクにおいて、従来の多言語LLMを上回る性能を発揮します。
🚀 クイックスタート
ERNIE-Codeは、116の自然言語と6つのプログラミング言語をつなぐ統一型大規模言語モデル(LLM)です。2つの事前学習方法を用いて、普遍的な多言語事前学習を行います。広範な結果から、ERNIE-Codeはコードインテリジェンスの幅広いエンドタスクにおいて、以前の多言語LLMを上回ることが示されています。
ERNIE-Code: Beyond English-Centric Cross-lingual Pretraining for Programming Languages
ACL 2023 (Findings) | arXiv
✨ 主な機能
ERNIE-Codeは、以下のような主な機能を備えています。
- 116の自然言語と6つのプログラミング言語をつなぐ統一型大規模言語モデル
- 広範なコードインテリジェンスのエンドタスクにおいて、従来の多言語LLMを上回る性能
- 多言語コードからテキスト、テキストからコード、コードからコード、テキストからテキストの生成などのタスクに対応
- 多言語コード要約とテキスト翻訳におけるゼロショットプロンプトの利点を示す
💻 使用例
基本的な使用法
import torch
from transformers import (
AutoModelForSeq2SeqLM,
AutoModelForCausalLM,
AutoTokenizer
)
model_name = "baidu/ernie-code-560m"
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
def format_code_with_spm_compatablity(line: str):
format_dict = {
" " : "<|space|>"
}
tokens = list(line)
i = 0
while i < len(tokens):
if line[i] == "\n":
while i+1 < len(tokens) and tokens[i+1] == " ":
tokens[i+1] = format_dict.get(" ")
i += 1
i += 1
formatted_line = ''.join(tokens)
return formatted_line
"""
TYPE="code" # define input type in ("code", "text")
input="arr.sort()"
prompt="translate python to java: \n%s" % (input) # your prompt here
"""
TYPE="text"
input="quick sort"
prompt="translate English to Japanese: \n%s" % (input)
assert TYPE in ("code", "text")
if TYPE=="code":
prompt = format_code_with_spm_compatablity(prompt)
model_inputs = tokenizer(prompt, max_length=512, padding=False, truncation=True, return_tensors="pt")
model = model.cuda()
input_ids = model_inputs.input_ids.cuda()
attention_mask = model_inputs.attention_mask.cuda()
output = model.generate(input_ids=input_ids, attention_mask=attention_mask,
num_beams=5, max_length=20)
output = tokenizer.decode(output.flatten(), skip_special_tokens=True)
def clean_up_code_spaces(s: str):
new_tokens = ["<pad>", "</s>", "<unk>", "\n", "\t", "<|space|>"*4, "<|space|>"*2, "<|space|>"]
for tok in new_tokens:
s = s.replace(f"{tok} ", tok)
cleaned_tokens = ["<pad>", "</s>", "<unk>"]
for tok in cleaned_tokens:
s = s.replace(tok, "")
s = s.replace("<|space|>", " ")
return s
output = [clean_up_code_spaces(pred) for pred in output]
高度な使用法
📚 ドキュメント
ゼロショットの例



📄 ライセンス
このプロジェクトはMITライセンスの下で提供されています。
BibTeX
@inproceedings{chai-etal-2023-ernie,
title = "{ERNIE}-Code: Beyond {E}nglish-Centric Cross-lingual Pretraining for Programming Languages",
author = "Chai, Yekun and
Wang, Shuohuan and
Pang, Chao and
Sun, Yu and
Tian, Hao and
Wu, Hua",
booktitle = "Findings of the Association for Computational Linguistics: ACL 2023",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.findings-acl.676",
pages = "10628--10650",
abstract = "Software engineers working with the same programming language (PL) may speak different natural languages (NLs) and vice versa, erecting huge barriers to communication and working efficiency. Recent studies have demonstrated the effectiveness of generative pre-training in computer programs, yet they are always English-centric. In this work, we step towards bridging the gap between multilingual NLs and multilingual PLs for large language models (LLMs). We release ERNIE-Code, a unified pre-trained language model for 116 NLs and 6 PLs. We employ two methods for universal cross-lingual pre-training: span-corruption language modeling that learns patterns from monolingual NL or PL; and pivot-based translation language modeling that relies on parallel data of many NLs and PLs. Extensive results show that ERNIE-Code outperforms previous multilingual LLMs for PL or NL across a wide range of end tasks of code intelligence, including multilingual code-to-text, text-to-code, code-to-code, and text-to-text generation. We further show its advantage of zero-shot prompting on multilingual code summarization and text-to-text translation. We release our code and pre-trained checkpoints.",
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応