🚀 DISTIL-ITA-LEGAL-BERT
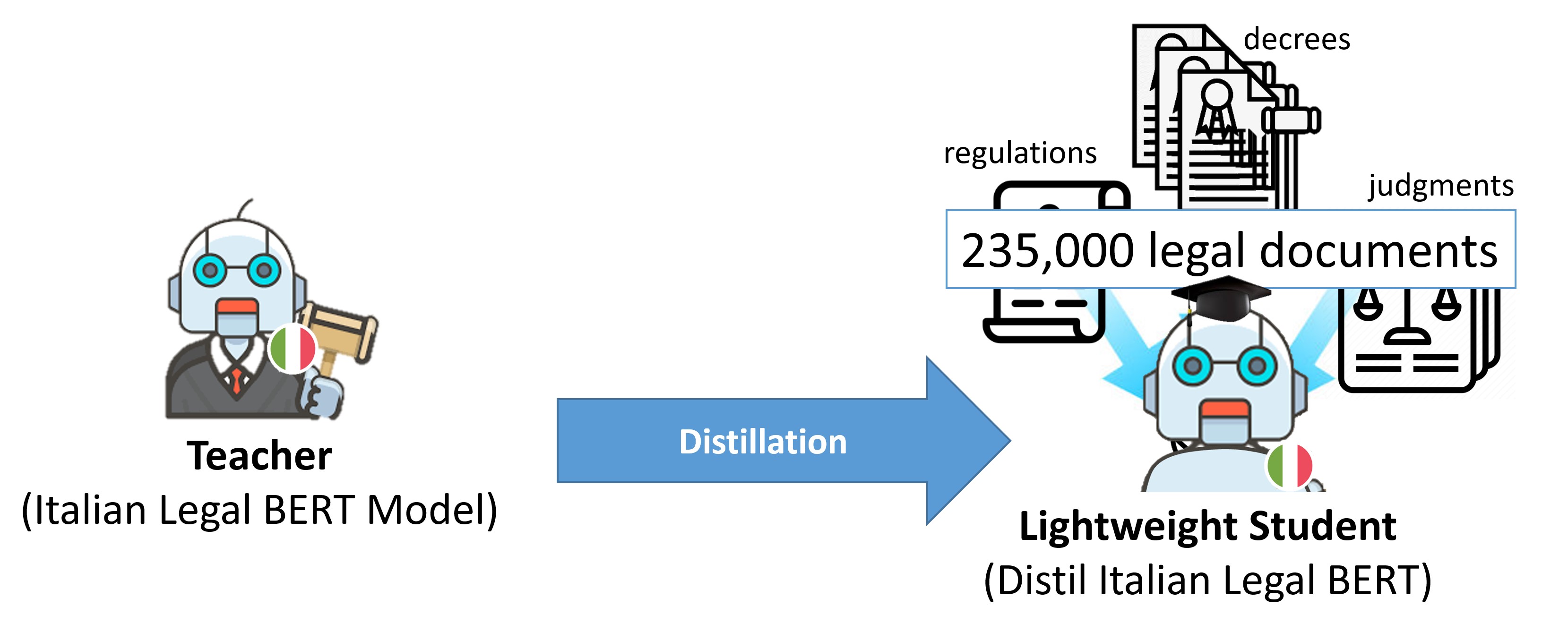
このモデルは、知識蒸留のプロセスを用いて、Transformerが4レベルのみの高速で軽量な生徒モデルを作成しました。このモデルは、より複雑なITALIAN-LEGAL-BERT教師モデルが生成するものと同様の文埋め込みを生成することができます。
このモデルは、Sentence-BERTライブラリを使用して、ITALIAN-LEGAL-BERTのトレーニングセット(3.7 GB)で、自身の埋め込みと教師モデルが生成する埋め込みの間の平均二乗誤差(MSE)を最小化することで最適化されています。
これはsentence-transformersモデルです。文や段落を768次元の密なベクトル空間にマッピングし、クラスタリングや意味検索などのタスクに使用できます。
🚀 クイックスタート
このモデルは、sentence-transformersをインストールすると簡単に使用できます。
✨ 主な機能
- 知識蒸留を用いて、高速で軽量な生徒モデルを作成。
- ITALIAN-LEGAL-BERTのトレーニングセットで最適化されている。
- 文や段落を768次元の密なベクトル空間にマッピングできる。
- クラスタリングや意味検索などのタスクに使用できる。
📦 インストール
pip install -U sentence-transformers
💻 使用例
基本的な使用法
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('dlicari/distil-ita-legal-bert')
embeddings = model.encode(sentences)
print(embeddings)
高度な使用法
from transformers import AutoTokenizer, AutoModel
import torch
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0]
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
sentences = ['This is an example sentence', 'Each sentence is converted']
tokenizer = AutoTokenizer.from_pretrained('dlicari/distil-ita-legal-bert')
model = AutoModel.from_pretrained('dlicari/distil-ita-legal-bert')
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
with torch.no_grad():
model_output = model(**encoded_input)
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
📚 ドキュメント
評価結果
このモデルの自動評価については、Sentence Embeddings Benchmarkを参照してください: https://seb.sbert.net
トレーニング
このモデルは以下のパラメータでトレーニングされました。
DataLoader:
torch.utils.data.dataloader.DataLoader of length 409633 with parameters:
{'batch_size': 24, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
Loss:
sentence_transformers.losses.MSELoss.MSELoss
Parameters of the fit()-Method:
{
"epochs": 4,
"evaluation_steps": 5000,
"evaluator": "sentence_transformers.evaluation.SequentialEvaluator.SequentialEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"correct_bias": false,
"eps": 1e-06,
"lr": 0.0001
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 1000,
"weight_decay": 0.01
}
全モデルアーキテクチャ
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
📄 ライセンス
このモデルはafl-3.0ライセンスの下で提供されています。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors Transformers 複数言語対応
Transformers 複数言語対応