%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Mctct Large
Meta AIが開発した大規模多言語音声認識モデルで、10億のパラメータを持ち、60言語の文字レベル転写をサポート
ダウンロード数 21
リリース時間 : 5/5/2022
モデル概要
M-CTC-TはTransformerエンコーダーを基にした大規模多言語音声認識モデルで、CTCヘッドと言語識別ヘッドを備え、60言語の音声入力を処理し文字レベルの転写テキスト(句読点や大文字小文字を保持)を出力できます。
モデル特徴
多言語サポート
60言語の音声認識をサポートし、言語識別機能を備えています
大規模トレーニング
10億パラメータ規模のTransformerアーキテクチャで、Common VoiceとVoxPopuliのデータでトレーニング
文字レベル転写
出力には元のテキストの句読点や大文字小文字の形式が保持されます
エンドツーエンドモデル
16kHz音声信号から直接抽出したメルフィルターバンク特徴量で認識を行います
モデル能力
多言語音声認識
言語識別
文字レベルテキスト転写
使用事例
音声からテキストへ
会議議事録自動転写
多言語会議録音を自動的にテキスト記録に変換
音声アシスタント
多言語音声コマンド認識をサポート
音声分析
多言語コンテンツ分析
異なる言語の音声コンテンツを分析
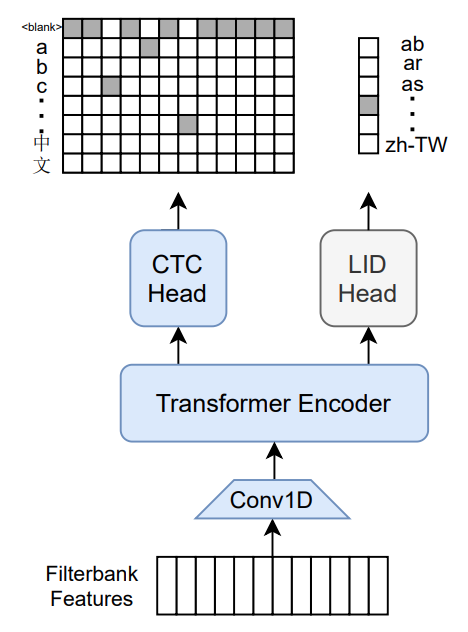
 注意: 論文の訓練図で置き換える予定
注意: 論文の訓練図で置き換える予定おすすめAIモデル
Llama 3 Typhoon V1.5x 8b Instruct
タイ語専用に設計された80億パラメータの命令モデルで、GPT-3.5-turboに匹敵する性能を持ち、アプリケーションシナリオ、検索拡張生成、制限付き生成、推論タスクを最適化
大規模言語モデル Transformers 複数言語対応
Transformers 複数言語対応
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-TinyはSODAデータセットでトレーニングされた超小型対話モデルで、エッジデバイス推論向けに設計されており、体積はCosmo-3Bモデルの約2%です。
対話システム Transformers 英語
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
RoBERTaアーキテクチャに基づく中国語抽出型QAモデルで、与えられたテキストから回答を抽出するタスクに適しています。
質問応答システム 中国語
R
uer
2,694
98