🚀 M-CTC-T
A massively multilingual speech recognizer from Meta AI. This model is a powerful tool for speech recognition across multiple languages, offering high - performance capabilities.
✨ Features
- Multilingual Support: Capable of recognizing speech in multiple languages.
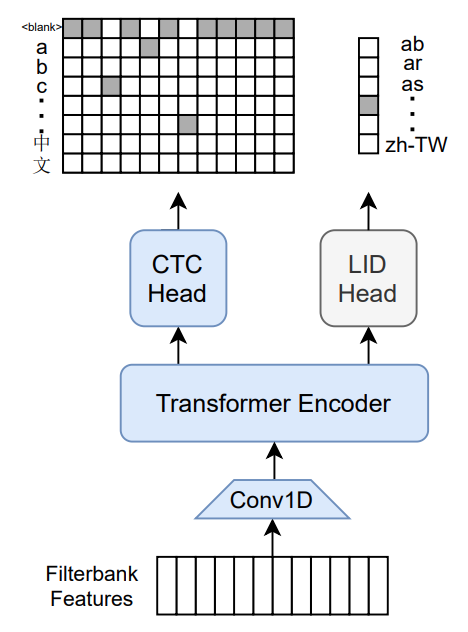
- Model Architecture: It is a 1B - param transformer encoder, equipped with a CTC head over 8065 character labels and a language identification head over 60 language ID labels.
- Training Data: Trained on datasets like Common Voice (version 6.1, December 2020 release), VoxPopuli, and later only on Common Voice. The labels are unnormalized character - level transcripts.
- Input Requirement: Takes Mel filterbank features from a 16Khz audio signal as input.
The original Flashlight code, model checkpoints, and Colab notebook can be found at https://github.com/flashlight/wav2letter/tree/main/recipes/mling_pl.
📦 Installation
No specific installation steps are provided in the original document, so this section is skipped.
💻 Usage Examples
Basic Usage
import torch
import torchaudio
from datasets import load_dataset
from transformers import MCTCTForCTC, MCTCTProcessor
model = MCTCTForCTC.from_pretrained("speechbrain/mctct-large")
processor = MCTCTProcessor.from_pretrained("speechbrain/mctct-large")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
input_features = processor(ds[0]["audio"]["array"], return_tensors="pt").input_features
logits = model(input_features).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
Advanced Usage
No advanced usage code example is provided in the original document, so this part is skipped.
Results for Common Voice, averaged over all languages:
Character error rate (CER):
📚 Documentation
For more information on how the model was trained, please take a look at the official paper.
 TO - DO: replace with the training diagram from paper
TO - DO: replace with the training diagram from paper
🔧 Technical Details
The model is a 1B - param transformer encoder, with a CTC head over 8065 character labels and a language identification head over 60 language ID labels. It is trained on specific datasets and takes Mel filterbank features from a 16Khz audio signal as input.
📄 License
This project is licensed under the apache - 2.0 license.
📄 Citation
Paper
Authors: Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, Ronan Collobert
@article{lugosch2021pseudo,
title={Pseudo-Labeling for Massively Multilingual Speech Recognition},
author={Lugosch, Loren and Likhomanenko, Tatiana and Synnaeve, Gabriel and Collobert, Ronan},
journal={ICASSP},
year={2022}
}
Additional thanks to Chan Woo Kim and Patrick von Platen for porting the model from Flashlight to PyTorch.
| Property |
Details |
| Model Type |
A 1B - param transformer encoder with CTC and language identification heads |
| Training Data |
Common Voice (version 6.1, December 2020 release), VoxPopuli, and later only Common Voice |
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)