🚀 COLD2モデル
このモデルは、検索クエリ内の欠落した単語の問題を解決するために設計されています。クエリのコンテキストを利用して、欠落している可能性のある単語を生成します。
🚀 クイックスタート
このモデルを使用する前に、必要なライブラリをインストールする必要があります。以下のコマンドを実行してください。
pip install protobuf sentencepiece
次に、以下のコードを使用してモデルを初期化し、欠落した単語を予測できます。
from transformers import pipeline
unmasker = pipeline("fill-mask", model="fkrasnov2/COLD2", device="cuda")
unmasker("электроника зарядка [MASK] USB")
[{'score': 0.3712620437145233,
'token': 1131,
'token_str': 'автомобильная',
'sequence': 'электроника зарядка автомобильная usb'},
{'score': 0.12239563465118408,
'token': 7436,
'token_str': 'быстрая',
'sequence': 'электроника зарядка быстрая usb'},
{'score': 0.046715956181287766,
'token': 5819,
'token_str': 'проводная',
'sequence': 'электроника зарядка проводная usb'},
{'score': 0.031308457255363464,
'token': 635,
'token_str': 'универсальная',
'sequence': 'электроника зарядка универсальная usb'},
{'score': 0.02941182069480419,
'token': 2371,
'token_str': 'адаптер',
'sequence': 'электроника зарядка адаптер usb'}]
💻 使用例
基本的な使用法
from transformers import pipeline
unmasker = pipeline("fill-mask", model="fkrasnov2/COLD2", device="cuda")
unmasker("электроника зарядка [MASK] USB")
高度な使用法
連結前置詞を使用することで、トークン化を改善できます。
unmasker("одежда женское [MASK] для_праздника")
[{'score': 0.9355553984642029,
'token': 503,
'token_str': 'платье',
'sequence': 'одежда женское платье для_праздника'},
{'score': 0.011321154423058033,
'token': 615,
'token_str': 'кольцо',
'sequence': 'одежда женское кольцо для_праздника'},
{'score': 0.008672593161463737,
'token': 993,
'token_str': 'украшение',
'sequence': 'одежда женское украшение для_праздника'},
{'score': 0.0038903721142560244,
'token': 27100,
'token_str': 'пончо',
'sequence': 'одежда женское пончо для_праздника'},
{'score': 0.003703165566548705,
'token': 453,
'token_str': 'белье',
'sequence': 'одежда женское белье для_праздника'}]
📚 詳細ドキュメント
transformers.jsでの使用
transformers.jsでこのモデルを使用するには、ONNXバージョンのモデルが必要です。以下のコードを使用して、ONNXモデルをロードできます。
from transformers import AutoTokenizer
from optimum.onnxruntime import ORTModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("fkrasnov2/COLD2")
model = ORTModelForMaskedLM.from_pretrained("fkrasnov2/COLD2", file_name='model.onnx')
ブラウザでの使用
このモデルは、ブラウザから直接実行して使用することもできます。以下のHTMLとJavaScriptのコードを使用して、ブラウザ上でモデルを実行できます。
index.html
<!DOCTYPE html>
<html lang="ru">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Mask fill</title>
<link rel="stylesheet" href="styles.css">
<script src="main.js" type="module" defer></script>
</head>
<body>
<div class="container">
<textarea id="long-text-input" placeholder="Enter search query with [MASK]"></textarea>
<button id="generate-button">
Заполнить маску
</button>
<div id="output-div"></div>
</div>
</body>
</html>
main.js
import { pipeline } from 'https://cdn.jsdelivr.net/npm/@huggingface/transformers@3.0.2';
const longTextInput = document.getElementById('long-text-input');
const output = document.getElementById('output-div');
const generateButton = document.getElementById('generate-button');
const pipe = await pipeline(
'fill-mask',
'fkrasnov2/COLD2'
);
generateButton.addEventListener('click', async () => {
const input = longTextInput.value;
const result = await pipe(input);
output.innerHTML = result[0].sequence;
output.style.display = 'block';
});
ブラウザ上での実行例は以下の画像の通りです。
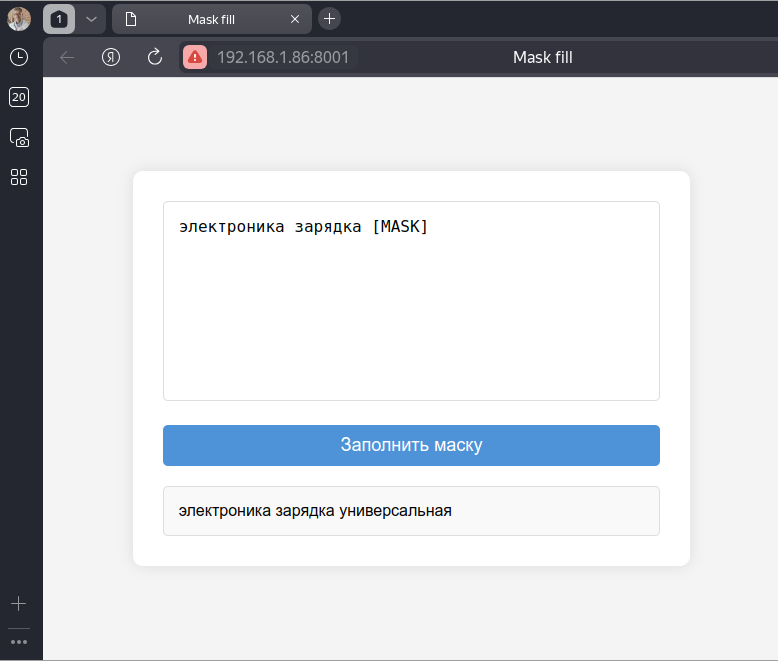
📄 ライセンス
このモデルはUnlicenseのライセンスの下で提供されています。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応