%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
EN
Bge Large En V1.5 Quant
Quantized (INT8) ONNX variant of BGE-large-en-v1.5 with inference acceleration via DeepSparse
Downloads 1,094
Release Time : 10/3/2023
Model Overview
This is the quantized version of the BGE-large-en-v1.5 embedding model, optimized using Sparsify for quantization and accelerated for inference via DeepSparseSentenceTransformers. Suitable for scenarios requiring efficient text embeddings.
Model Features
Efficient Inference
Achieves 4.8x latency improvement on a 10-core laptop and 3.5x improvement on a 16-core AWS instance via DeepSparse
Quantization Optimization
Utilizes INT8 quantization with Sparsify, reducing computational resource requirements while maintaining model performance
Multi-Task Support
Supports various NLP tasks including semantic text similarity, text classification, and pair classification
Model Capabilities
Text Embedding Generation
Semantic Similarity Calculation
Text Classification
Sentence Pair Classification
Use Cases
Text Similarity
Document Retrieval
Calculate semantic similarity between documents for information retrieval systems
Achieves 86.6% Pearson correlation coefficient for cosine similarity on the STS benchmark
Duplicate Question Detection
Identify semantically similar duplicate questions
Achieves 99.85% accuracy on the SprintDuplicateQuestions dataset
Text Classification
Sentiment Analysis
Classify text by sentiment polarity
Achieves 75.54% accuracy on the AmazonCounterfactual classification task
license: mit language:
- en tags:
- sparse
- sparsity
- quantized
- onnx
- embeddings
- int8
- mteb
- deepsparse model-index:
- name: bge-large-en-v1.5-quant
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy value: 75.53731343283583
- type: ap value: 38.30609312253564
- type: f1 value: 69.42802757893695
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson value: 89.27346145216443
- type: cos_sim_spearman value: 88.36526647458979
- type: euclidean_pearson value: 86.83053354694746
- type: euclidean_spearman value: 87.56223612880584
- type: manhattan_pearson value: 86.59250609226758
- type: manhattan_spearman value: 87.70681773644885
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson value: 86.18998669716373
- type: cos_sim_spearman value: 82.06129973984048
- type: euclidean_pearson value: 83.65969509485801
- type: euclidean_spearman value: 81.91666612708826
- type: manhattan_pearson value: 83.6906794731384
- type: manhattan_spearman value: 81.91752705367436
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson value: 86.93407086985752
- type: cos_sim_spearman value: 78.82992283957066
- type: euclidean_pearson value: 83.39733473832982
- type: euclidean_spearman value: 78.86999229850214
- type: manhattan_pearson value: 83.39397058098533
- type: manhattan_spearman value: 78.85397971200753
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson value: 87.2586009863056
- type: cos_sim_spearman value: 87.99415514558852
- type: euclidean_pearson value: 86.98993652364359
- type: euclidean_spearman value: 87.72725335668807
- type: manhattan_pearson value: 86.897205761048
- type: manhattan_spearman value: 87.65231103509018
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson value: 85.41417660460755
- type: cos_sim_spearman value: 83.50291886604928
- type: euclidean_pearson value: 84.67758839660924
- type: euclidean_spearman value: 83.4368059512681
- type: manhattan_pearson value: 84.66027228213025
- type: manhattan_spearman value: 83.43472054456252
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson value: 88.02513262365703
- type: cos_sim_spearman value: 89.00430907638267
- type: euclidean_pearson value: 88.16290361497319
- type: euclidean_spearman value: 88.6645154822661
- type: manhattan_pearson value: 88.15337528825458
- type: manhattan_spearman value: 88.66202950081507
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson value: 85.10194022827035
- type: cos_sim_spearman value: 86.45367112223394
- type: euclidean_pearson value: 85.45292931769094
- type: euclidean_spearman value: 86.06607589083283
- type: manhattan_pearson value: 85.4111233047049
- type: manhattan_spearman value: 86.04379654118996
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson value: 89.86966589113663
- type: cos_sim_spearman value: 89.5617056243649
- type: euclidean_pearson value: 89.018495917952
- type: euclidean_spearman value: 88.387335721179
- type: manhattan_pearson value: 89.07568042943448
- type: manhattan_spearman value: 88.51733863475219
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson value: 68.38465344518238
- type: cos_sim_spearman value: 68.15219488291783
- type: euclidean_pearson value: 68.99169681132668
- type: euclidean_spearman value: 68.01334641045888
- type: manhattan_pearson value: 68.84952679202642
- type: manhattan_spearman value: 67.85430179655137
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson value: 86.60574360222778
- type: cos_sim_spearman value: 87.8878986593873
- type: euclidean_pearson value: 87.11557232168404
- type: euclidean_spearman value: 87.40944677043365
- type: manhattan_pearson value: 87.10395398212532
- type: manhattan_spearman value: 87.35977283466168
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy value: 99.84752475247525
- type: cos_sim_ap value: 96.49316696572335
- type: cos_sim_f1 value: 92.35352532274081
- type: cos_sim_precision value: 91.71597633136095
- type: cos_sim_recall value: 93.0
- type: dot_accuracy value: 99.77326732673268
- type: dot_ap value: 93.5497681978726
- type: dot_f1 value: 88.35582208895552
- type: dot_precision value: 88.31168831168831
- type: dot_recall value: 88.4
- type: euclidean_accuracy value: 99.84653465346534
- type: euclidean_ap value: 96.36378999360083
- type: euclidean_f1 value: 92.33052944087086
- type: euclidean_precision value: 91.38099902056807
- type: euclidean_recall value: 93.30000000000001
- type: manhattan_accuracy value: 99.84455445544555
- type: manhattan_ap value: 96.36035171233175
- type: manhattan_f1 value: 92.13260761999011
- type: manhattan_precision value: 91.1851126346719
- type: manhattan_recall value: 93.10000000000001
- type: max_accuracy value: 99.84752475247525
- type: max_ap value: 96.49316696572335
- type: max_f1 value: 92.35352532274081
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy value: 87.26828396018358
- type: cos_sim_ap value: 77.79878217023162
- type: cos_sim_f1 value: 71.0425694621463
- type: cos_sim_precision value: 68.71301775147928
- type: cos_sim_recall value: 73.53562005277044
- type: dot_accuracy value: 84.01978899684092
- type: dot_ap value: 66.12134149171163
- type: dot_f1 value: 63.283507097098365
- type: dot_precision value: 60.393191081275475
- type: dot_recall value: 66.46437994722955
- type: euclidean_accuracy value: 87.24444179531503
- type: euclidean_ap value: 77.84821131946212
- type: euclidean_f1 value: 71.30456661215247
- type: euclidean_precision value: 68.1413801394566
- type: euclidean_recall value: 74.77572559366754
- type: manhattan_accuracy value: 87.19079692436074
- type: manhattan_ap value: 77.78054941055291
- type: manhattan_f1 value: 71.13002127393318
- type: manhattan_precision value: 67.65055939062128
- type: manhattan_recall value: 74.9868073878628
- type: max_accuracy value: 87.26828396018358
- type: max_ap value: 77.84821131946212
- type: max_f1 value: 71.30456661215247
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy value: 88.91023402025847
- type: cos_sim_ap value: 85.94088151184411
- type: cos_sim_f1 value: 78.25673997223645
- type: cos_sim_precision value: 74.45433059919367
- type: cos_sim_recall value: 82.46843239913767
- type: dot_accuracy value: 87.91865564481701
- type: dot_ap value: 82.75373957440969
- type: dot_f1 value: 75.97383507276201
- type: dot_precision value: 72.67294713160854
- type: dot_recall value: 79.5888512473052
- type: euclidean_accuracy value: 88.8539604921023
- type: euclidean_ap value: 85.71590936389937
- type: euclidean_f1 value: 77.82902261742242
- type: euclidean_precision value: 74.7219270279844
- type: euclidean_recall value: 81.20572836464429
- type: manhattan_accuracy value: 88.78992509799356
- type: manhattan_ap value: 85.70200619366904
- type: manhattan_f1 value: 77.85875848203065
- type: manhattan_precision value: 72.94315506222671
- type: manhattan_recall value: 83.48475515860795
- type: max_accuracy value: 88.91023402025847
- type: max_ap value: 85.94088151184411
- type: max_f1 value: 78.25673997223645
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
bge-large-en-v1.5-quant
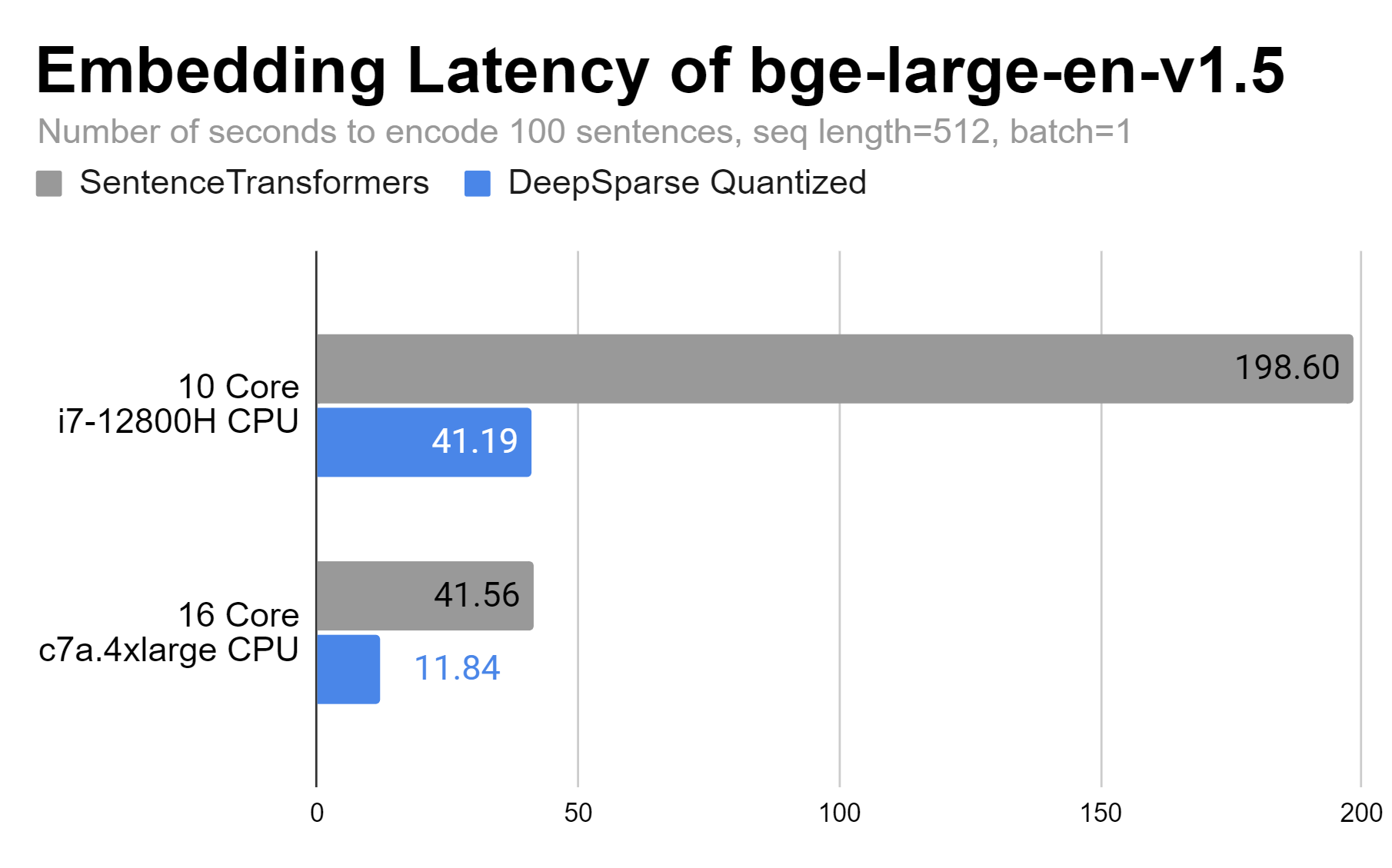
DeepSparse is able to improve latency performance on a 10 core laptop by 4.8X and up to 3.5X on a 16 core AWS instance.
Usage
This is the quantized (INT8) ONNX variant of the bge-large-en-v1.5 embeddings model accelerated with Sparsify for quantization and DeepSparseSentenceTransformers for inference.
pip install -U deepsparse-nightly[sentence_transformers]
from deepsparse.sentence_transformers import DeepSparseSentenceTransformer
model = DeepSparseSentenceTransformer('neuralmagic/bge-large-en-v1.5-quant', export=False)
# Our sentences we like to encode
sentences = ['This framework generates embeddings for each input sentence',
'Sentences are passed as a list of string.',
'The quick brown fox jumps over the lazy dog.']
# Sentences are encoded by calling model.encode()
embeddings = model.encode(sentences)
# Print the embeddings
for sentence, embedding in zip(sentences, embeddings):
print("Sentence:", sentence)
print("Embedding:", embedding.shape)
print("")
For general questions on these models and sparsification methods, reach out to the engineering team on our community Slack.
Jina Embeddings V3
Jina Embeddings V3 is a multilingual sentence embedding model supporting over 100 languages, specializing in sentence similarity and feature extraction tasks.
Text Embedding Transformers Supports Multiple Languages
Transformers Supports Multiple Languages
J
jinaai
3.7M
911
Ms Marco MiniLM L6 V2
Apache-2.0
A cross-encoder model trained on the MS Marco passage ranking task for query-passage relevance scoring in information retrieval
Text Embedding English
M
cross-encoder
2.5M
86
Opensearch Neural Sparse Encoding Doc V2 Distill
Apache-2.0
A sparse retrieval model based on distillation technology, optimized for OpenSearch, supporting inference-free document encoding with improved search relevance and efficiency over V1
Text Embedding Transformers English
O
opensearch-project
1.8M
7
Sapbert From PubMedBERT Fulltext
Apache-2.0
A biomedical entity representation model based on PubMedBERT, optimized for semantic relation capture through self-aligned pre-training
Text Embedding English
S
cambridgeltl
1.7M
49
Gte Large
MIT
GTE-Large is a powerful sentence transformer model focused on sentence similarity and text embedding tasks, excelling in multiple benchmark tests.
Text Embedding English
G
thenlper
1.5M
278
Gte Base En V1.5
Apache-2.0
GTE-base-en-v1.5 is an English sentence transformer model focused on sentence similarity tasks, excelling in multiple text embedding benchmarks.
Text Embedding Transformers Supports Multiple Languages
G
Alibaba-NLP
1.5M
63
Gte Multilingual Base
Apache-2.0
GTE Multilingual Base is a multilingual sentence embedding model supporting over 50 languages, suitable for tasks like sentence similarity calculation.
Text Embedding Transformers Supports Multiple Languages
G
Alibaba-NLP
1.2M
246
Polybert
polyBERT is a chemical language model designed to achieve fully machine-driven ultrafast polymer informatics. It maps PSMILES strings into 600-dimensional dense fingerprints to numerically represent polymer chemical structures.
Text Embedding Transformers
P
kuelumbus
1.0M
5
Bert Base Turkish Cased Mean Nli Stsb Tr
Apache-2.0
A sentence embedding model based on Turkish BERT, optimized for semantic similarity tasks
Text Embedding Transformers Other
B
emrecan
1.0M
40
GIST Small Embedding V0
MIT
A text embedding model fine-tuned based on BAAI/bge-small-en-v1.5, trained with the MEDI dataset and MTEB classification task datasets, optimized for query encoding in retrieval tasks.
Text Embedding Safetensors English
Safetensors English
Safetensors EnglishG
avsolatorio
945.68k
29
Featured Recommended AI Models