🚀 hotchpotch/japanese-reranker-tiny-v2
A very small and fast Japanese reranker model series (v2).
For more information about rerankers, technical reports, and evaluations, please refer to the following links:
🚀 Quick Start
Prerequisites
The operation requires version 4.48 or higher of the transformers library.
pip install -U "transformers>=4.48.0" sentence-transformers sentencepiece
If your GPU supports Flash Attention 2, you can install the flash-attn library for faster inference:
pip install flash-attn --no-build-isolation
💻 Usage Examples
SentenceTransformers
from sentence_transformers import CrossEncoder
import torch
MODEL_NAME = "hotchpotch/japanese-reranker-tiny-v2"
model = CrossEncoder(MODEL_NAME)
if model.device == "cuda" or model.device == "mps":
model.model.half()
query = "感動的な映画について"
passages = [
"深いテーマを持ちながらも、観る人の心を揺さぶる名作。登場人物の心情描写が秀逸で、ラストは涙なしでは見られない。",
"重要なメッセージ性は評価できるが、暗い話が続くので気分が落ち込んでしまった。もう少し明るい要素があればよかった。",
"どうにもリアリティに欠ける展開が気になった。もっと深みのある人間ドラマが見たかった。",
"アクションシーンが楽しすぎる。見ていて飽きない。ストーリーはシンプルだが、それが逆に良い。",
]
scores = model.predict(
[(query, passage) for passage in passages],
show_progress_bar=True,
)
print("Scores:", scores)
SentenceTransformers + onnx
If you want to run the model faster in a CPU or ARM environment, you can use ONNX or a quantized model.
pip install onnx onnxruntime accelerate optimum
from sentence_transformers import CrossEncoder
onnx_filename = "onnx/model_qint8_arm64.onnx"
if onnx_filename:
model = CrossEncoder(
MODEL_NAME,
device="cpu",
backend="onnx",
model_kwargs={"file_name": onnx_filename},
)
else:
model = CrossEncoder(MODEL_NAME, device="cpu", backend="onnx")
...
HuggingFace transformers
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from torch.nn import Sigmoid
def detect_device():
if torch.cuda.is_available():
return "cuda"
elif hasattr(torch, "mps") and torch.mps.is_available():
return "mps"
return "cpu"
device = detect_device()
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModelForSequenceClassification.from_pretrained(MODEL_NAME)
model.to(device)
model.eval()
if device == "cuda":
model.half()
query = "感動的な映画について"
passages = [
"深いテーマを持ちながらも、観る人の心を揺さぶる名作。登場人物の心情描写が秀逸で、ラストは涙なしでは見られない。",
"重要なメッセージ性は評価できるが、暗い話が続くので気分が落ち込んでしまった。もう少し明るい要素があればよかった。",
"どうにもリアリティに欠ける展開が気になった。もっと深みのある人間ドラマが見たかった。",
"アクションシーンが楽しすぎる。見ていて飽きない。ストーリーはシンプルだが、それが逆に良い。",
]
inputs = tokenizer(
[(query, passage) for passage in passages],
padding=True,
truncation=True,
max_length=512,
return_tensors="pt",
)
inputs = {k: v.to(device) for k, v in inputs.items()}
logits = model(**inputs).logits
activation = Sigmoid()
scores = activation(logits).squeeze().tolist()
print("Scores:", scores)
✨ Features
Characteristics of Small Rerankers
japanese-reranker-tiny-v2 and japanese-reranker-xsmall-v2 are small reranker models with the following features:
- They can operate at a practical speed even in CPU or Apple Silicon environments.
- They can improve the accuracy of RAG systems without expensive GPU resources.
- They can be deployed on edge devices and used in production environments that require low latency.
- They are based on ModernBert's ruri-v3-pt-30m.
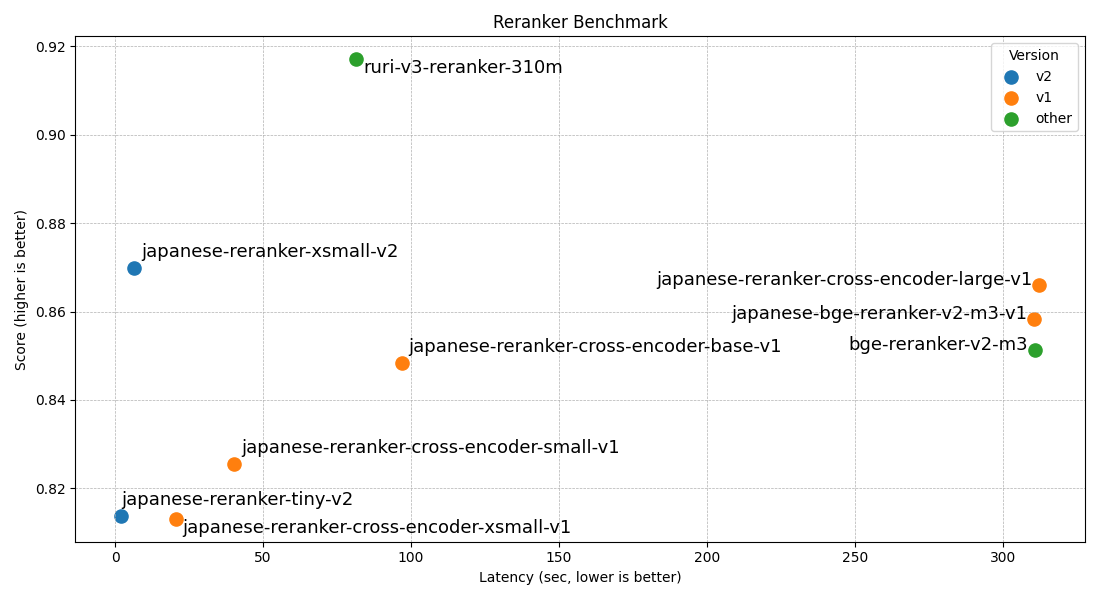
Evaluation Results
Inference Speed
The following are the inference speed results when reranking approximately 150,000 pairs (pure model inference time excluding tokenization time). M4 Max was used for MPS (Apple Silicon) and CPU measurements, and RTX5090 was used for GPU. Flash-attention2 was used for GPU processing.
The script used for the inference speed benchmark is available here.
📄 License
This project is licensed under the MIT License.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
