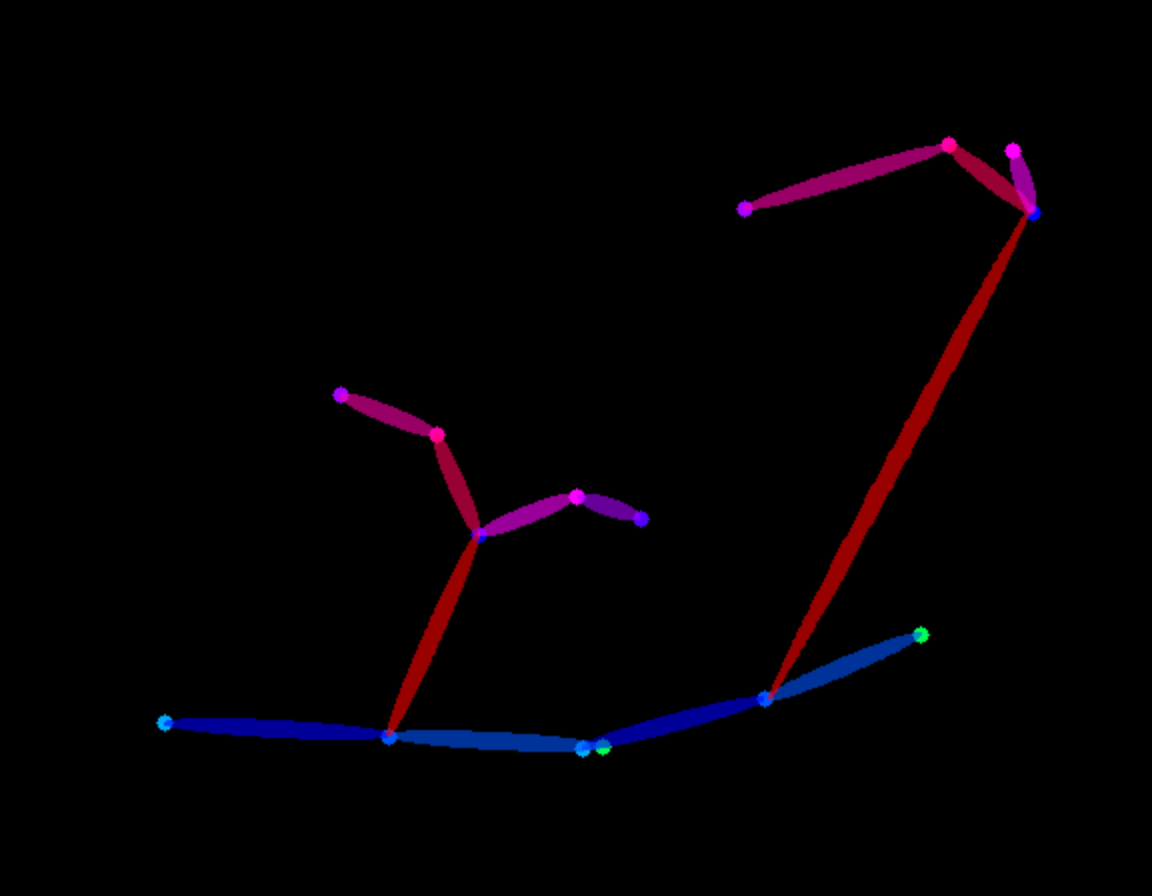
🚀 T2I-Adapter-SDXL - Sketch
T2I Adapter is a network that provides additional conditioning for Stable Diffusion. Each T2I checkpoint takes a different type of conditioning as input and is used with a specific base Stable Diffusion checkpoint. This checkpoint offers sketch conditioning for the StableDiffusionXL checkpoint. It was a collaborative effort between Tencent ARC and Hugging Face.
🚀 Quick Start
To get started, first install the required dependencies:
pip install -U git+https://github.com/huggingface/diffusers.git
pip install -U controlnet_aux==0.0.7
pip install transformers accelerate safetensors
- Download images in the appropriate control image format.
- Pass the control image and prompt to the
StableDiffusionXLAdapterPipeline.
✨ Features
T2I Adapter provides additional conditioning to Stable Diffusion, enabling more controllable image generation. Different T2I checkpoints support various types of conditioning, such as sketches, canny edges, line art, depth, and poses.
📦 Installation
pip install -U git+https://github.com/huggingface/diffusers.git
pip install -U controlnet_aux==0.0.7
pip install transformers accelerate safetensors
💻 Usage Examples
Basic Usage
Let's have a look at a simple example using the Canny Adapter.
from diffusers import StableDiffusionXLAdapterPipeline, T2IAdapter, EulerAncestralDiscreteScheduler, AutoencoderKL
from diffusers.utils import load_image, make_image_grid
from controlnet_aux.pidi import PidiNetDetector
import torch
adapter = T2IAdapter.from_pretrained(
"TencentARC/t2i-adapter-sketch-sdxl-1.0", torch_dtype=torch.float16, varient="fp16"
).to("cuda")
model_id = 'stabilityai/stable-diffusion-xl-base-1.0'
euler_a = EulerAncestralDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
vae=AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16)
pipe = StableDiffusionXLAdapterPipeline.from_pretrained(
model_id, vae=vae, adapter=adapter, scheduler=euler_a, torch_dtype=torch.float16, variant="fp16",
).to("cuda")
pipe.enable_xformers_memory_efficient_attention()
pidinet = PidiNetDetector.from_pretrained("lllyasviel/Annotators").to("cuda")
url = "https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/org_sketch.png"
image = load_image(url)
image = pidinet(
image, detect_resolution=1024, image_resolution=1024, apply_filter=True
)

prompt = "a robot, mount fuji in the background, 4k photo, highly detailed"
negative_prompt = "extra digit, fewer digits, cropped, worst quality, low quality, glitch, deformed, mutated, ugly, disfigured"
gen_images = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
image=image,
num_inference_steps=30,
adapter_conditioning_scale=0.9,
guidance_scale=7.5,
).images[0]
gen_images.save('out_sketch.png')

📚 Documentation
Model Details
| Property |
Details |
| Developed by |
T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models |
| Model Type |
Diffusion-based text-to-image generation model |
| Language(s) |
English |
| License |
Apache 2.0 |
| Resources for more information |
GitHub Repository, Paper. |
| Model complexity |
|
| Cite as |
@misc{
title={T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models},
author={Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, Ying Shan, Xiaohu Qie},
year={2023},
eprint={2302.08453},
archivePrefix={arXiv},
primaryClass={cs.CV}
} |
Checkpoints
Demo
Try out the model with your own hand-drawn sketches/doodles in the Doodly Space!
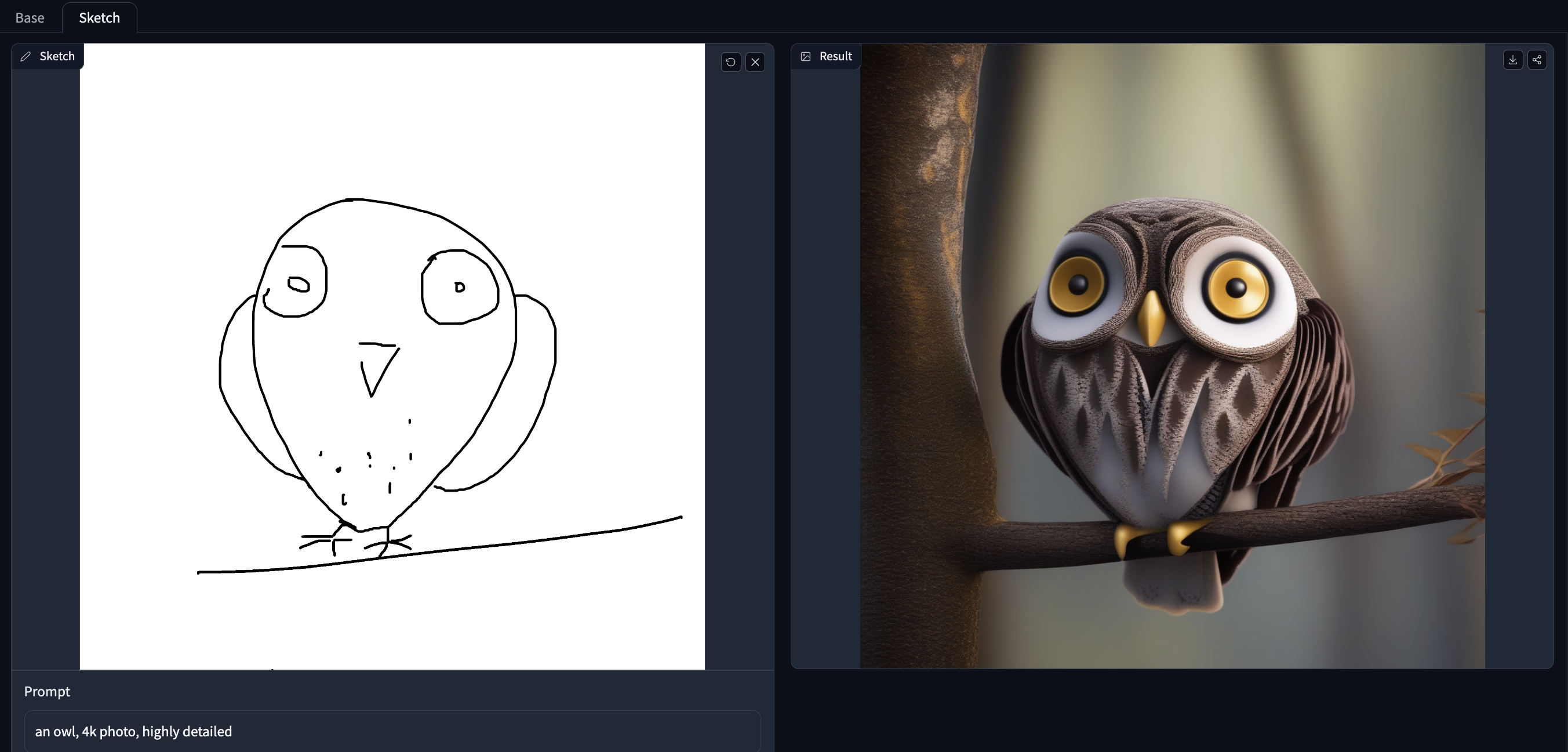
Training
Our training script was built on top of the official training script that we provide here.
The model is trained on 3M high-resolution image-text pairs from LAION-Aesthetics V2 with:
- Training steps: 20000
- Batch size: Data parallel with a single gpu batch size of
16 for a total batch size of 256.
- Learning rate: Constant learning rate of
1e-5.
- Mixed precision: fp16
📄 License
This project is licensed under the Apache 2.0 license.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)