🚀 KoMiniLM
🐣 A lightweight Korean language model designed to overcome the limitations of large - scale models in real - world applications.
🚀 Quick Start
Current language models often contain hundreds of millions of parameters, which pose challenges for fine - tuning and online serving in real - life applications due to latency and capacity constraints. In this project, we introduce a lightweight Korean language model to address these shortcomings.
💻 Usage Examples
Basic Usage
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("BM-K/KoMiniLM")
model = AutoModel.from_pretrained("BM-K/KoMiniLM")
inputs = tokenizer("안녕 세상아!", return_tensors="pt")
outputs = model(**inputs)
📈 Update History
** Updates on 2022.06.20 **
- Released KoMiniLM-bert-68M
** Updates on 2022.05.24 **
- Released KoMiniLM-bert-23M
📚 Documentation
Pre - training
Teacher Model: KLUE-BERT(base)
Objective
Self - Attention Distribution and Self - Attention Value - Relation [Wang et al., 2020] were distilled from each discrete layer of the teacher model to the student model. Unlike the approach in [Wang et al., 2020], which distilled in the last layer of the transformer, our project distills from each layer.
Data Sets
| Property |
Details |
| News comments |
10G |
| News article |
10G |
Configuration
{
"architectures": [
"BertForPreTraining"
],
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 384,
"initializer_range": 0.02,
"intermediate_size": 1536,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 6,
"output_attentions": true,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"return_dict": false,
"torch_dtype": "float32",
"transformers_version": "4.13.0",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 32000
}
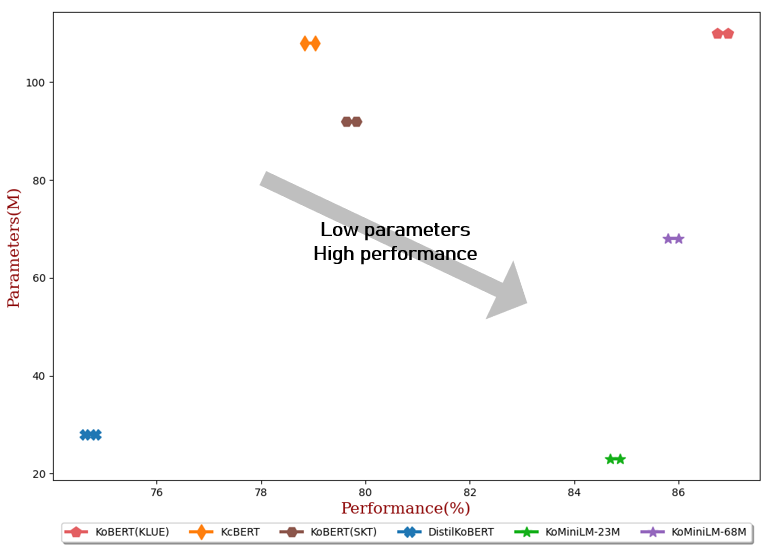
Performance on Subtasks
- The results of our fine - tuning experiments are an average of 3 runs for each task.
cd KoMiniLM-Finetune
bash scripts/run_all_kominilm.sh
| Model |
#Param |
Average |
NSMC
(Acc) |
Naver NER
(F1) |
PAWS
(Acc) |
KorNLI
(Acc) |
KorSTS
(Spearman) |
Question Pair
(Acc) |
KorQuaD
(Dev)
(EM/F1) |
| KoBERT(KLUE) |
110M |
86.84 |
90.20±0.07 |
87.11±0.05 |
81.36±0.21 |
81.06±0.33 |
82.47±0.14 |
95.03±0.44 |
84.43±0.18 /
93.05±0.04 |
| KcBERT |
108M |
78.94 |
89.60±0.10 |
84.34±0.13 |
67.02±0.42 |
74.17±0.52 |
76.57±0.51 |
93.97±0.27 |
60.87±0.27 /
85.01±0.14 |
| KoBERT(SKT) |
92M |
79.73 |
89.28±0.42 |
87.54±0.04 |
80.93±0.91 |
78.18±0.45 |
75.98±2.81 |
94.37±0.31 |
51.94±0.60 /
79.69±0.66 |
| DistilKoBERT |
28M |
74.73 |
88.39±0.08 |
84.22±0.01 |
61.74±0.45 |
70.22±0.14 |
72.11±0.27 |
92.65±0.16 |
52.52±0.48 /
76.00±0.71 |
|
|
|
|
|
|
|
|
|
|
| KoMiniLM† |
68M |
85.90 |
89.84±0.02 |
85.98±0.09 |
80.78±0.30 |
79.28±0.17 |
81.00±0.07 |
94.89±0.37 |
83.27±0.08 /
92.08±0.06 |
| KoMiniLM† |
23M |
84.79 |
89.67±0.03 |
84.79±0.09 |
78.67±0.45 |
78.10±0.07 |
78.90±0.11 |
94.81±0.12 |
82.11±0.42 /
91.21±0.29 |
- NSMC (Naver Sentiment Movie Corpus)
- Naver NER (NER task on Naver NLP Challenge 2018)
- PAWS (Korean Paraphrase Adversaries from Word Scrambling)
- KorNLI/KorSTS (Korean Natural Language Understanding)
- Question Pair (Paired Question)
- KorQuAD (The Korean Question Answering Dataset)
📖 Reference
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)