🚀 RT-DETR-H_layout_3cls
这是一个高精度的布局区域定位模型,基于RT-DETR-H在自建的中英文论文、杂志和研究报告数据集上训练得到。该模型为3类布局检测模型,可检测表格、图像和印章。
🚀 快速开始
📦 安装指南
1. 安装PaddlePaddle
请参考以下命令,使用pip安装PaddlePaddle:
python -m pip install paddlepaddle-gpu==3.0.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
python -m pip install paddlepaddle-gpu==3.0.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
python -m pip install paddlepaddle==3.0.0 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/
PaddlePaddle安装详情请参考PaddlePaddle官方网站。
2. 安装PaddleOCR
从PyPI安装最新版本的PaddleOCR推理包:
python -m pip install paddleocr
💻 使用示例
基础用法
你可以使用单条命令快速体验模型功能:
paddleocr layout_detection \
--model_name RT-DETR-H_layout_3cls \
-i https://cdn-uploads.huggingface.co/production/uploads/63d7b8ee07cd1aa3c49a2026/N5C68HPVAI-xQAWTxpbA6.jpeg
你也可以将布局检测模块的模型推理集成到你的项目中。在运行以下代码前,请将示例图像下载到本地:
from paddleocr import LayoutDetection
model = LayoutDetection(model_name="RT-DETR-H_layout_3cls")
output = model.predict("N5C68HPVAI-xQAWTxpbA6.jpeg", batch_size=1, layout_nms=True)
for res in output:
res.print()
res.save_to_img(save_path="./output/")
res.save_to_json(save_path="./output/res.json")
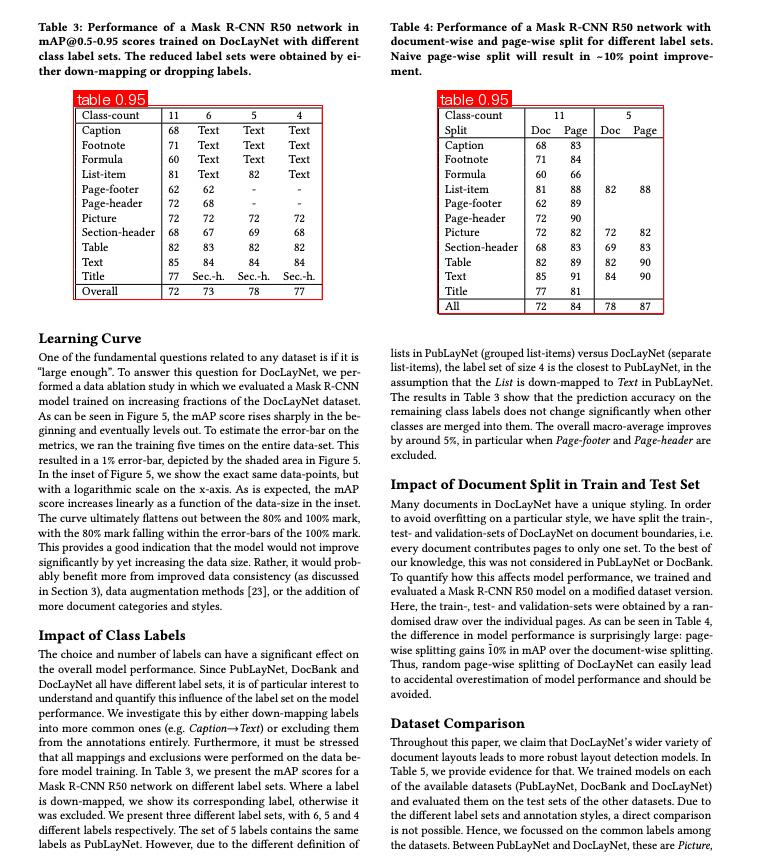
运行后,得到的结果如下:
{'res': {'input_path': '/root/.paddlex/predict_input/N5C68HPVAI-xQAWTxpbA6.jpeg', 'page_index': None, 'boxes': [{'cls_id': 1, 'label': 'table', 'score': 0.9491576552391052, 'coordinate': [73.66756, 105.629265, 322.29645, 299.0941]}, {'cls_id': 1, 'label': 'table', 'score': 0.9472811222076416, 'coordinate': [437.03156, 105.77351, 663.26776, 313.97778]}]}}
可视化图像如下:
 使用命令和参数说明详情请参考文档。
使用命令和参数说明详情请参考文档。
高级用法
单个模型的能力有限,但由多个模型组成的管道可以为解决现实场景中的难题提供更强的能力。
PP-ChatOCRv4-doc
PP-ChatOCRv4-doc是PaddlePaddle推出的独特的文档和图像智能分析解决方案,它结合了大语言模型(LLM)、多模态大语言模型(MLLM)和OCR技术,以应对复杂的文档信息提取挑战,如布局分析、生僻字符、多页PDF、表格和印章识别等。它集成了ERNIE Bot,融合了海量数据和知识,实现了高精度和广泛的适用性。
文档场景信息提取v4管道包括布局区域检测、表格结构识别、表格分类、表格单元格定位、文本检测、文本识别、印章文本检测、文本图像矫正和文档图像方向分类等模块。
你可以使用单条命令快速体验PP-ChatOCRv4-doc管道:
paddleocr pp_chatocrv4_doc -i vehicle_certificate-1.png -k 驾驶室准乘人数 --qianfan_api_key your_api_key
如果指定了save_path,可视化结果将保存到save_path下。
命令行方法适用于快速体验。对于项目集成,也只需要几行代码:
from paddleocr import PPChatOCRv4Doc
chat_bot_config = {
"module_name": "chat_bot",
"model_name": "ernie-3.5-8k",
"base_url": "https://qianfan.baidubce.com/v2",
"api_type": "openai",
"api_key": "api_key",
}
retriever_config = {
"module_name": "retriever",
"model_name": "embedding-v1",
"base_url": "https://qianfan.baidubce.com/v2",
"api_type": "qianfan",
"api_key": "api_key",
}
mllm_chat_bot_config = {
"module_name": "chat_bot",
"model_name": "PP-DocBee2",
"base_url": "http://127.0.0.1:8080/",
"api_type": "openai",
"api_key": "api_key",
}
pipeline = PPChatOCRv4Doc()
visual_predict_res = pipeline.visual_predict(
input="vehicle_certificate-1.png",
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_common_ocr=True,
use_seal_recognition=True,
use_table_recognition=True,
)
visual_info_list = []
for res in visual_predict_res:
visual_info_list.append(res["visual_info"])
layout_parsing_result = res["layout_parsing_result"]
vector_info = pipeline.build_vector(
visual_info_list, flag_save_bytes_vector=True, retriever_config=retriever_config
)
mllm_predict_res = pipeline.mllm_pred(
input="vehicle_certificate-1.png",
key_list=["驾驶室准乘人数"],
mllm_chat_bot_config=mllm_chat_bot_config,
)
mllm_predict_info = mllm_predict_res["mllm_res"]
chat_result = pipeline.chat(
key_list=["驾驶室准乘人数"],
visual_info=visual_info_list,
vector_info=vector_info,
mllm_predict_info=mllm_predict_info,
chat_bot_config=chat_bot_config,
retriever_config=retriever_config,
)
print(chat_result)
管道中使用的默认模型是RT-DETR-H_layout_3cls。使用命令和参数说明详情请参考文档。
📚 详细文档
| 属性 |
详情 |
| 模型类型 |
3类布局检测模型,可检测表格、图像和印章 |
| 训练数据 |
自建的中英文论文、杂志和研究报告数据集 |
🔗 相关链接
📄 许可证
本项目使用Apache-2.0许可证。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多种语言
Transformers 支持多种语言