🚀 RT-DETR-H_layout_3cls
A high-precision layout area localization model trained on a self-built dataset of Chinese and English papers, magazines, and research reports, offering accurate layout detection for tables, images, and seals.
🚀 Quick Start
✨ Features
- A high-precision layout area localization model trained on a self - built dataset of Chinese and English papers, magazines, and research reports.
- It is a 3 - Class Layout Detection Model, including Table, Image, and Seal.
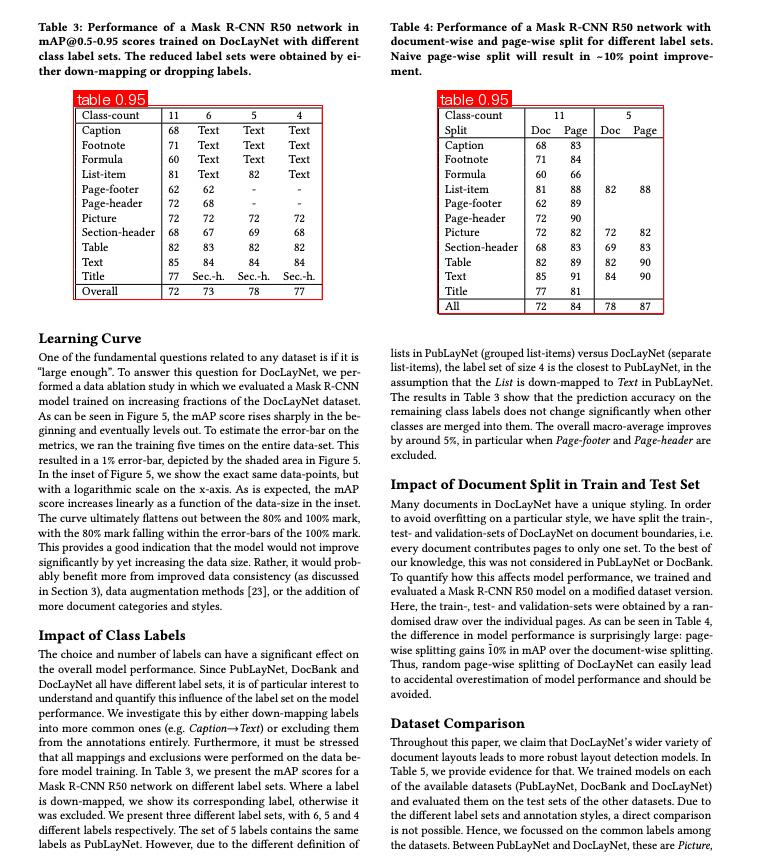
- The mAP(0.5) of RT - DETR - H_layout_3cls reaches 95.8%.
- PP - ChatOCRv4 - doc pipeline combines LLM, MLLM, and OCR technologies to address complex document information extraction challenges.
📦 Installation
- PaddlePaddle
Please refer to the following commands to install PaddlePaddle using pip:
python -m pip install paddlepaddle-gpu==3.0.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
python -m pip install paddlepaddle-gpu==3.0.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
python -m pip install paddlepaddle==3.0.0 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/
For details about PaddlePaddle installation, please refer to the PaddlePaddle official website.
- PaddleOCR
Install the latest version of the PaddleOCR inference package from PyPI:
python -m pip install paddleocr
💻 Usage Examples
Basic Usage
You can quickly experience the functionality with a single command:
paddleocr layout_detection \
--model_name RT-DETR-H_layout_3cls \
-i https://cdn-uploads.huggingface.co/production/uploads/63d7b8ee07cd1aa3c49a2026/N5C68HPVAI-xQAWTxpbA6.jpeg
You can also integrate the model inference of the layout detection module into your project. Before running the following code, please download the sample image to your local machine.
from paddleocr import LayoutDetection
model = LayoutDetection(model_name="RT-DETR-H_layout_3cls")
output = model.predict("N5C68HPVAI-xQAWTxpbA6.jpeg", batch_size=1, layout_nms=True)
for res in output:
res.print()
res.save_to_img(save_path="./output/")
res.save_to_json(save_path="./output/res.json")
After running, the obtained result is as follows:
{'res': {'input_path': '/root/.paddlex/predict_input/N5C68HPVAI-xQAWTxpbA6.jpeg', 'page_index': None, 'boxes': [{'cls_id': 1, 'label': 'table', 'score': 0.9491576552391052, 'coordinate': [73.66756, 105.629265, 322.29645, 299.0941]}, {'cls_id': 1, 'label': 'table', 'score': 0.9472811222076416, 'coordinate': [437.03156, 105.77351, 663.26776, 313.97778]}]}}
The visualized image is as follows:
For details about usage command and descriptions of parameters, please refer to the Document.
Advanced Usage - Pipeline Usage
The ability of a single model is limited. But the pipeline consists of several models can provide more capacity to resolve difficult problems in real - world scenarios.
PP - ChatOCRv4 - doc
PP - ChatOCRv4 - doc is a unique document and image intelligent analysis solution from PaddlePaddle, combining LLM, MLLM, and OCR technologies to address complex document information extraction challenges such as layout analysis, rare characters, multi - page PDFs, tables, and seal recognition. Integrated with ERNIE Bot, it fuses massive data and knowledge, achieving high accuracy and wide applicability.
The Document Scene Information Extraction v4 pipeline includes modules for Layout Region Detection, Table Structure Recognition, Table Classification, Table Cell Localization, Text Detection, Text Recognition, Seal Text Detection, Text Image Rectification, and Document Image Orientation Classification.
You can quickly experience the PP - ChatOCRv4 - doc pipeline with a single command.
paddleocr pp_chatocrv4_doc -i vehicle_certificate-1.png -k 驾驶室准乘人数 --qianfan_api_key your_api_key
If save_path is specified, the visualization results will be saved under save_path.
The command - line method is for quick experience. For project integration, also only a few codes are needed as well:
from paddleocr import PPChatOCRv4Doc
chat_bot_config = {
"module_name": "chat_bot",
"model_name": "ernie-3.5-8k",
"base_url": "https://qianfan.baidubce.com/v2",
"api_type": "openai",
"api_key": "api_key",
}
retriever_config = {
"module_name": "retriever",
"model_name": "embedding-v1",
"base_url": "https://qianfan.baidubce.com/v2",
"api_type": "qianfan",
"api_key": "api_key",
}
mllm_chat_bot_config = {
"module_name": "chat_bot",
"model_name": "PP-DocBee2",
"base_url": "http://127.0.0.1:8080/",
"api_type": "openai",
"api_key": "api_key",
}
pipeline = PPChatOCRv4Doc()
visual_predict_res = pipeline.visual_predict(
input="vehicle_certificate-1.png",
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_common_ocr=True,
use_seal_recognition=True,
use_table_recognition=True,
)
visual_info_list = []
for res in visual_predict_res:
visual_info_list.append(res["visual_info"])
layout_parsing_result = res["layout_parsing_result"]
vector_info = pipeline.build_vector(
visual_info_list, flag_save_bytes_vector=True, retriever_config=retriever_config
)
mllm_predict_res = pipeline.mllm_pred(
input="vehicle_certificate-1.png",
key_list=["驾驶室准乘人数"],
mllm_chat_bot_config=mllm_chat_bot_config,
)
mllm_predict_info = mllm_predict_res["mllm_res"]
chat_result = pipeline.chat(
key_list=["驾驶室准乘人数"],
visual_info=visual_info_list,
vector_info=vector_info,
mllm_predict_info=mllm_predict_info,
chat_bot_config=chat_bot_config,
retriever_config=retriever_config,
)
print(chat_result)
The default model used in pipeline is RT - DETR - H_layout_3cls. For details about usage command and descriptions of parameters, please refer to the Document.
📚 Documentation
-
Model Metrics
| Property | Details |
|----------|---------|
| Model Type | RT - DETR - H_layout_3cls |
| mAP(0.5) | 95.8% |
-
PaddlePaddle Installation
Please refer to the PaddlePaddle official website for detailed installation instructions.
-
Model Usage Details
For details about usage command and descriptions of parameters, please refer to the Document.
-
Pipeline Usage Details
For details about usage command and descriptions of parameters of PP - ChatOCRv4 - doc pipeline, please refer to the Document.
📄 License
This project is licensed under the Apache - 2.0 license.
🔗 Links
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)