🚀 ContentV:利用有限计算资源高效训练视频生成模型
本项目推出了 ContentV,这是一个高效的框架,通过三项关键创新加速基于 DiT 的视频生成模型的训练:
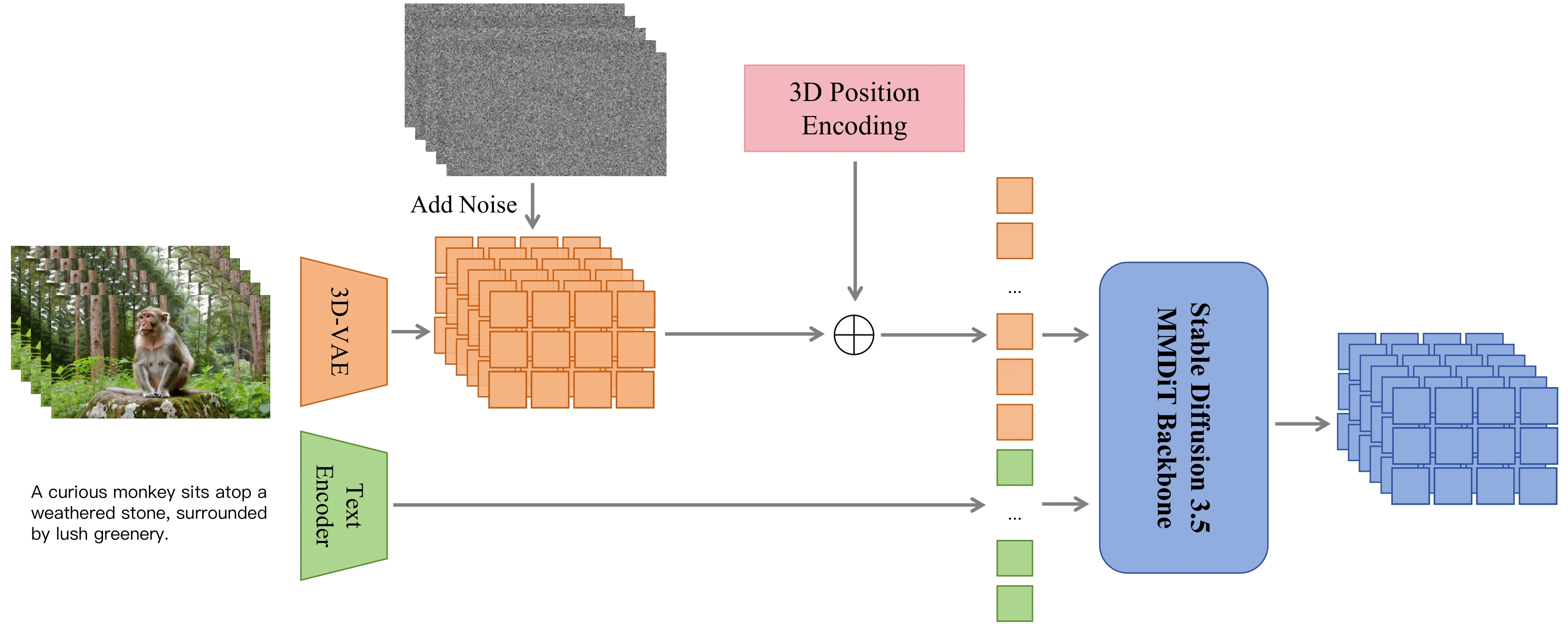
- 极简架构,最大限度地复用预训练图像生成模型进行视频合成。
- 系统的多阶段训练策略,利用流匹配提高效率。
- 一种经济高效的基于人类反馈的强化学习框架,无需额外的人工标注即可提高生成质量。
我们开源的 80 亿参数模型(基于 Stable Diffusion 3.5 Large 和 Wan-VAE)仅用 256×64GB 的 NPU 训练 4 周,就在 VBench 上取得了 85.14 的最优成绩。
🚀 快速开始
推荐的 PyTorch 版本
安装
git clone https://github.com/bytedance/ContentV.git
cd ContentV
pip3 install -r requirements.txt
文本到视频生成
python3 demo.py
USE_ASCEND_NPU=1 python3 demo.py
✨ 主要特性
- 提出了一种极简架构,可最大限度地复用预训练图像生成模型进行视频合成。
- 采用了系统的多阶段训练策略,利用流匹配提高训练效率。
- 引入了一种经济高效的基于人类反馈的强化学习框架,无需额外的人工标注即可提高生成质量。
📊 VBench 评测结果
| 模型 |
总分 |
质量得分 |
语义得分 |
人类动作 |
场景 |
动态程度 |
多对象 |
外观风格 |
| Wan2.1-14B |
86.22 |
86.67 |
84.44 |
99.20 |
61.24 |
94.26 |
86.59 |
21.59 |
| ContentV (长视频) |
85.14 |
86.64 |
79.12 |
96.80 |
57.38 |
83.05 |
71.41 |
23.02 |
| Goku† |
84.85 |
85.60 |
81.87 |
97.60 |
57.08 |
76.11 |
79.48 |
23.08 |
| Open-Sora 2.0 |
84.34 |
85.40 |
80.12 |
95.40 |
52.71 |
71.39 |
77.72 |
22.98 |
| Sora† |
84.28 |
85.51 |
79.35 |
98.20 |
56.95 |
79.91 |
70.85 |
24.76 |
| ContentV (短视频) |
84.11 |
86.23 |
75.61 |
89.60 |
44.02 |
79.26 |
74.58 |
21.21 |
| EasyAnimate 5.1 |
83.42 |
85.03 |
77.01 |
95.60 |
54.31 |
57.15 |
66.85 |
23.06 |
| Kling 1.6† |
83.40 |
85.00 |
76.99 |
96.20 |
55.57 |
62.22 |
63.99 |
20.75 |
| HunyuanVideo |
83.24 |
85.09 |
75.82 |
94.40 |
53.88 |
70.83 |
68.55 |
19.80 |
| CogVideoX-5B |
81.61 |
82.75 |
77.04 |
99.40 |
53.20 |
70.97 |
62.11 |
24.91 |
| Pika-1.0† |
80.69 |
82.92 |
71.77 |
86.20 |
49.83 |
47.50 |
43.08 |
22.26 |
| VideoCrafter-2.0 |
80.44 |
82.20 |
73.42 |
95.00 |
55.29 |
42.50 |
40.66 |
25.13 |
| AnimateDiff-V2 |
80.27 |
82.90 |
69.75 |
92.60 |
50.19 |
40.83 |
36.88 |
22.42 |
| OpenSora 1.2 |
79.23 |
80.71 |
73.30 |
85.80 |
42.47 |
47.22 |
58.41 |
23.89 |
📄 待办事项
- [x] 推理代码和检查点
- [ ] 基于人类反馈的强化学习训练代码
📄 许可证
本代码仓库和部分模型权重遵循 Apache 2.0 许可证。请注意:
🙏 致谢
感谢以下开源项目的贡献:
📖 引用
@article{contentv2025,
title = {ContentV: Efficient Training of Video Generation Models with Limited Compute},
author = {Bytedance Douyin Content Team},
journal = {arXiv preprint arXiv:2506.05343},
year = {2025}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

 Transformers 支持多种语言
Transformers 支持多种语言