%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Contentv 8B
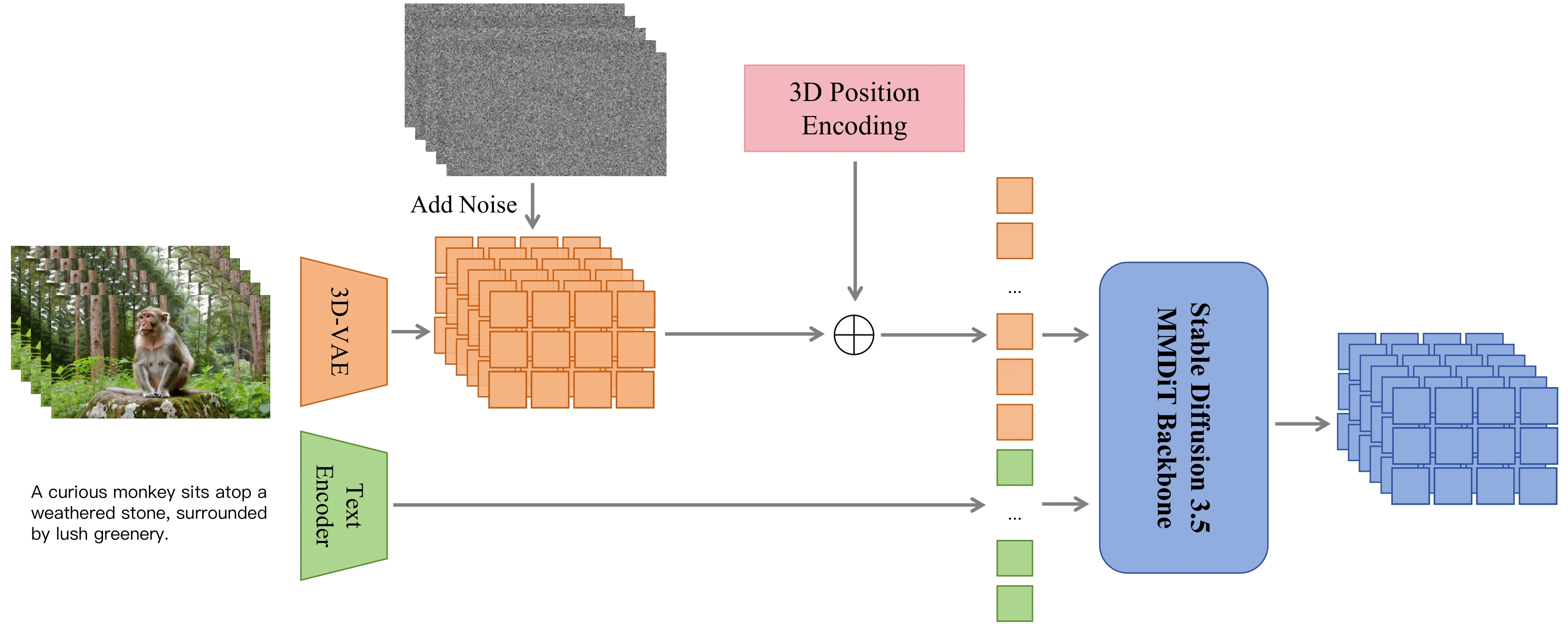
ContentV is an efficient video generation model framework that achieves high-quality video generation with limited computing resources through a minimalist architecture, multi-stage training strategy, and cost-effective reinforcement learning framework.
Downloads 417
Release Time : 6/3/2025
Model Overview
ContentV is a video generation model based on DiT. By reusing pre-trained image generation models, flow matching training strategies, and a reinforcement learning framework without manual annotation, it significantly improves training efficiency and generation quality.
Model Features
Minimalist architecture
Maximize the reuse of pre-trained image generation models for video synthesis to reduce training costs
Multi-stage training strategy
Adopt a systematic multi-stage training strategy and use flow matching to improve training efficiency
Cost-effective reinforcement learning
Introduce a reinforcement learning framework based on human feedback without additional manual annotation to improve generation quality
Model Capabilities
Text-to-video generation
High-quality video synthesis
Long video generation
Short video generation
Use Cases
Video content creation
Short video generation
Automatically generate short video content based on text descriptions
Achieved 84.11 points in the VBench evaluation (short video)
Long video generation
Automatically generate long video content based on text descriptions
Achieved 85.14 points in the VBench evaluation (long video)

Featured Recommended AI Models