%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型简介
模型特点
模型能力
使用案例
🚀 xLAM模型家族
xLAM模型家族属于大型动作模型(LAMs),这类先进的大语言模型旨在增强决策能力,并将用户意图转化为与外界交互的可执行动作。LAMs能够自主规划和执行任务以实现特定目标,可作为AI智能体的核心,具备自动化各领域工作流程的潜力,在众多应用场景中价值巨大。
🚀 快速开始
欢迎来到xLAM模型家族!大型动作模型(LAMs)是先进的大语言模型,旨在增强决策能力,并将用户意图转化为与外界交互的可执行动作。LAMs能够自主规划和执行任务以实现特定目标,可作为AI智能体的核心。它们有潜力自动化各个领域的工作流程,在广泛的应用中具有重要价值。

[主页] | [论文] | [Discord] | [数据集] | [Github]
✨ 主要特性
- 提供不同大小的xLAM模型系列,以满足各种应用需求。
- “fc”系列模型针对函数调用能力进行了优化,能基于输入查询和可用API提供快速、准确和结构化的响应。
- 提供量化的GGUF文件,便于在资源有限的本地设备上高效部署和执行。
- 在伯克利函数调用排行榜(BFCL)上表现出色,展现出强大的函数调用能力。
📦 安装指南
使用Huggingface的基本安装
要从Huggingface使用xLAM-7b-fc-r模型,请先安装transformers库:
pip install transformers>=4.41.0
使用vLLM的安装
要使用vllm部署模型并运行推理,首先安装所需的包:
pip install vllm openai argparse jinja2
💻 使用示例
基础用法 - Huggingface
以下示例展示了如何使用xLAM-7b-fc-r模型执行函数调用任务。请注意,使用我们提供的提示格式能让模型达到最佳效果,该格式可提取类似于ChatGPT函数调用模式的JSON输出。
import json
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
torch.random.manual_seed(0)
model_name = "Salesforce/xLAM-7b-fc-r"
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype="auto", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 请使用我们提供的指令提示以获得最佳性能
task_instruction = """
You are an expert in composing functions. You are given a question and a set of possible functions.
Based on the question, you will need to make one or more function/tool calls to achieve the purpose.
If none of the functions can be used, point it out and refuse to answer.
If the given question lacks the parameters required by the function, also point it out.
""".strip()
format_instruction = """
The output MUST strictly adhere to the following JSON format, and NO other text MUST be included.
The example format is as follows. Please make sure the parameter type is correct. If no function call is needed, please make tool_calls an empty list '[]'.
{ "tool_calls": [ {"name": "func_name1", "arguments": {"argument1": "value1", "argument2": "value2"}}, ... (more tool calls as required) ] }
""".strip()
# 定义输入查询和可用工具
query = "What's the weather like in New York in fahrenheit?"
get_weather_api = {
"name": "get_weather",
"description": "Get the current weather for a location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, New York"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The unit of temperature to return"
}
},
"required": ["location"]
}
}
search_api = {
"name": "search",
"description": "Search for information on the internet",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The search query, e.g. 'latest news on AI'"
}
},
"required": ["query"]
}
}
openai_format_tools = [get_weather_api, search_api]
# 辅助函数,将OpenAI格式的工具转换为更简洁的xLAM格式
def convert_to_xlam_tool(tools):
''''''
if isinstance(tools, dict):
return {
"name": tools["name"],
"description": tools["description"],
"parameters": {k: v for k, v in tools["parameters"].get("properties", {}).items()}
}
elif isinstance(tools, list):
return [convert_to_xlam_tool(tool) for tool in tools]
else:
return tools
# 辅助函数,为我们的模型构建输入提示
def build_prompt(task_instruction: str, format_instruction: str, tools: list, query: str):
prompt = f"[BEGIN OF TASK INSTRUCTION]\n{task_instruction}\n[END OF TASK INSTRUCTION]\n\n"
prompt += f"[BEGIN OF AVAILABLE TOOLS]\n{json.dumps(xlam_format_tools)}\n[END OF AVAILABLE TOOLS]\n\n"
prompt += f"[BEGIN OF FORMAT INSTRUCTION]\n{format_instruction}\n[END OF FORMAT INSTRUCTION]\n\n"
prompt += f"[BEGIN OF QUERY]\n{query}\n[END OF QUERY]\n\n"
return prompt
# 构建输入并开始推理
xlam_format_tools = convert_to_xlam_tool(openai_format_tools)
content = build_prompt(task_instruction, format_instruction, xlam_format_tools, query)
messages=[
{ 'role': 'user', 'content': content}
]
inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
# tokenizer.eos_token_id 是 <|EOT|> 标记的ID
outputs = model.generate(inputs, max_new_tokens=512, do_sample=False, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
运行上述代码后,你应该能看到以下JSON格式的输出字符串:
{"tool_calls": [{"name": "get_weather", "arguments": {"location": "New York", "unit": "fahrenheit"}}]}
强烈建议使用我们提供的提示格式和辅助函数,以充分发挥模型的函数调用性能。
高级用法 - vLLM
我们提供了使用vllm部署模型并运行推理的示例脚本。
1. 测试提示模板
要使用聊天模板构建提示并输出适用于各种测试用例的格式化提示,请运行:
python test_prompt_template.py --model
2. 使用手动服务端点测试xLAM模型
a. 使用vLLM服务模型:
python -m vllm.entrypoints.openai.api_server --model Salesforce/xLAM-7b-fc-r --served-model-name xLAM-7b-fc-r --dtype bfloat16 --port 8001
b. 运行测试脚本:
python test_xlam_model_with_endpoint.py --model_name xLAM-7b-fc-r --port 8001 [OPTIONS]
选项:
--temperature:默认值为0.3--top_p:默认值为1.0--max_tokens:默认值为512
此测试脚本提供了一个处理程序实现,可轻松应用于自定义的函数调用应用程序。
3. 直接使用vLLM库测试xLAM模型
要直接使用vLLM库测试xLAM模型,请运行:
python test_xlam_model_with_vllm.py --model Salesforce/xLAM-7b-fc-r [OPTIONS]
选项与端点测试相同。此测试脚本也提供了一个处理程序实现,可轻松应用于自定义的函数调用应用程序。
自定义
这些示例设计灵活,可轻松集成到你自己的项目中。你可以根据具体需求和应用场景修改脚本,例如调整测试查询或API定义,以测试不同的场景或模型能力。
额外的自定义提示:
- 根据GPU容量修改服务模型时的
--dtype参数。 - 参考vLLM文档获取更详细的配置选项。
- 查看
demo.ipynb文件,了解整个工作流程的详细描述,包括如何执行API。
这些资源为将xLAM模型集成到你的应用程序中提供了坚实的基础,可实现定制化和高效部署。
📚 详细文档
模型系列
我们提供了一系列不同大小的xLAM模型,以满足各种应用需求,包括针对函数调用和通用智能体应用进行优化的模型:
| 模型名称 | 总参数数量 | 上下文长度 | 发布日期 | 类别 | 下载模型 | 下载GGUF文件 |
|---|---|---|---|---|---|---|
| xLAM-7b-r | 7.24B | 32k | 2024年9月5日 | 通用, 函数调用 | 🤗 链接 | -- |
| xLAM-8x7b-r | 46.7B | 32k | 2024年9月5日 | 通用, 函数调用 | 🤗 链接 | -- |
| xLAM-8x22b-r | 141B | 64k | 2024年9月5日 | 通用, 函数调用 | 🤗 链接 | -- |
| xLAM-1b-fc-r | 1.35B | 16k | 2024年7月17日 | 函数调用 | 🤗 链接 | 🤗 链接 |
| xLAM-7b-fc-r | 6.91B | 4k | 2024年7月17日 | 函数调用 | 🤗 链接 | 🤗 链接 |
| xLAM-v0.1-r | 46.7B | 32k | 2024年3月18日 | 通用, 函数调用 | 🤗 链接 | -- |
“fc”系列模型针对函数调用能力进行了优化,能够根据输入查询和可用API提供快速、准确和结构化的响应。这些模型基于deepseek-coder模型进行微调,体积小巧,可部署在手机或电脑等个人设备上。
我们还提供了量化的GGUF文件,用于高效部署和执行。GGUF是一种专门设计的文件格式,用于高效存储和加载大语言模型,非常适合在资源有限的本地设备上运行AI模型,支持离线功能并增强隐私保护。
仓库概述
本仓库主要聚焦于小型的xLAM-7b-fc-r模型,该模型针对函数调用进行了优化,可轻松部署在个人设备上。
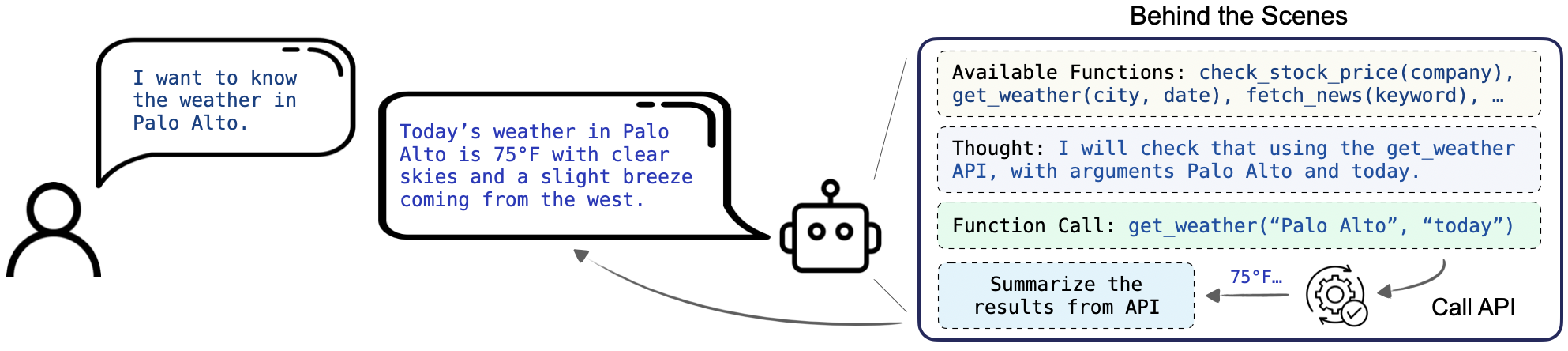
函数调用(或工具使用)是AI智能体的关键能力之一。它要求模型不仅能够理解和生成类人文本,还能根据自然语言指令执行功能性API调用。这将大语言模型的应用范围从简单的对话任务扩展到与各种数字服务和应用程序的动态交互,例如获取天气信息、管理社交媒体平台和处理金融服务等。
本指南将引导你完成xLAM-7b-fc-r与HuggingFace和vLLM的设置、使用和集成过程。我们将首先介绍基本用法,然后详细介绍示例文件夹中提供的教程和示例脚本。
框架版本
- Transformers 4.41.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
基准测试结果
我们主要在伯克利函数调用排行榜(BFCL)上测试我们的函数调用模型,该排行榜提供了一个全面的评估框架,用于评估大语言模型在各种编程语言和应用领域(如Java、JavaScript和Python)中的函数调用能力。
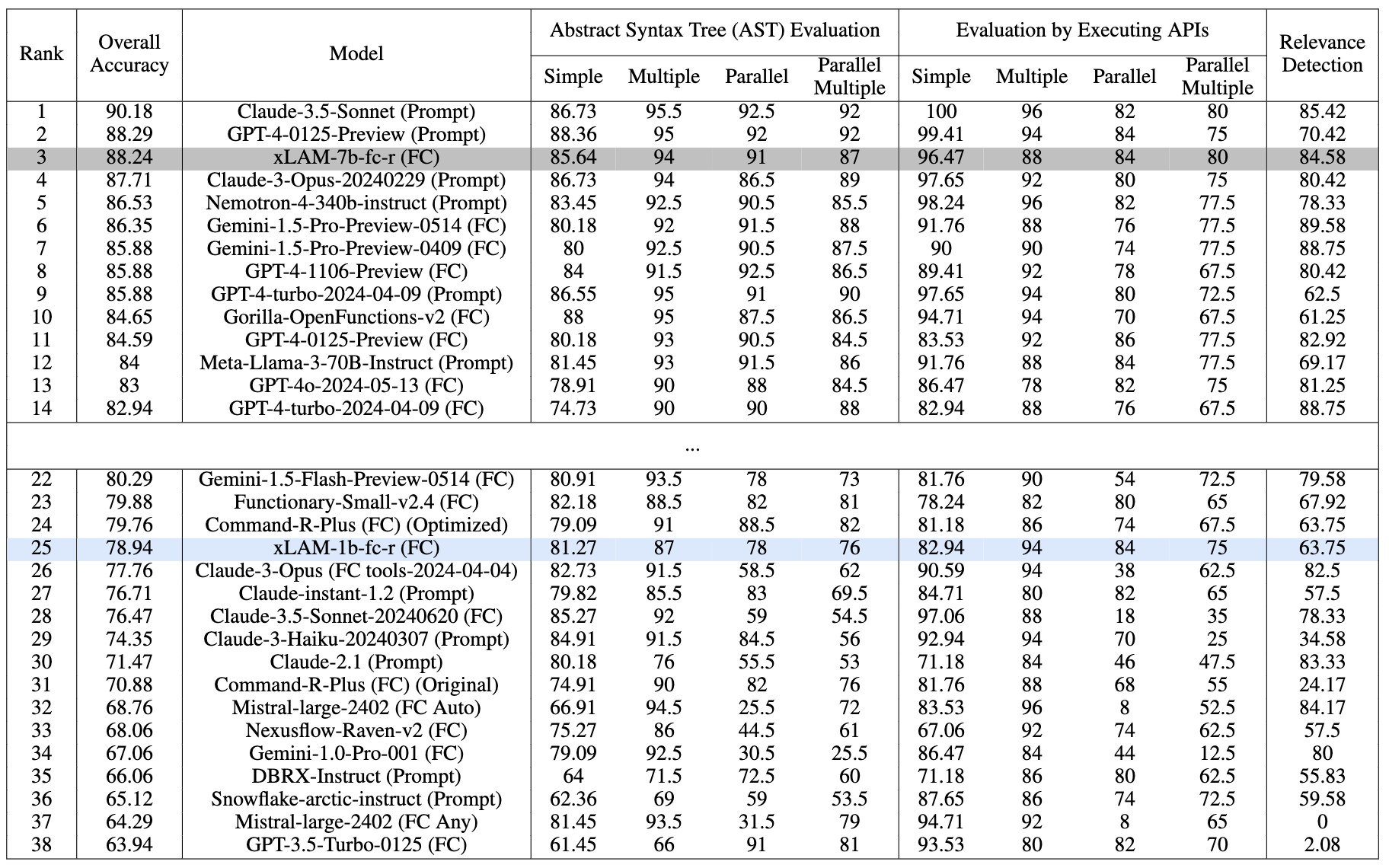
截至2024年7月18日,在BFCL基准测试中的性能比较。使用 temperature=0.001 和 top_p=1 进行评估
我们的xLAM-7b-fc-r模型在排行榜上以88.24%的总体准确率获得第3名,超越了许多强大的模型。值得注意的是,我们的xLAM-1b-fc-r模型是排行榜上唯一参数少于20亿的小型模型,但仍实现了78.94%的有竞争力的总体准确率,超越了GPT3-Turbo和许多更大的模型。
这两个模型在各个类别中都表现出平衡的性能,尽管体积小巧,但仍展现出强大的函数调用能力。
🔧 技术细节
本模型基于deepseek-coder模型进行微调,针对函数调用能力进行了优化。通过特定的训练和调整,使得模型能够根据输入查询和可用API,快速、准确地生成结构化的响应。
在性能方面,我们在伯克利函数调用排行榜(BFCL)上进行了测试,该排行榜提供了一个全面的评估框架,涵盖了多种编程语言和应用领域。我们的xLAM-7b-fc-r和xLAM-1b-fc-r模型在排行榜上表现出色,证明了其在函数调用任务中的有效性和竞争力。
此外,我们还提供了量化的GGUF文件,用于高效部署和执行。GGUF是一种专门设计的文件格式,能够高效存储和加载大语言模型,使得模型可以在资源有限的本地设备上运行,支持离线功能并增强隐私保护。
📄 许可证
xLAM-7b-fc-r模型遵循CC-BY-NC-4.0许可证进行分发,具体附加条款请参考Deepseek许可证。
📚 引用
如果您觉得本仓库对您有帮助,请引用我们的论文:
@article{zhang2024xlam,
title={xlam: A family of large action models to empower ai agent systems},
author={Zhang, Jianguo and Lan, Tian and Zhu, Ming and Liu, Zuxin and Hoang, Thai and Kokane, Shirley and Yao, Weiran and Tan, Juntao and Prabhakar, Akshara and Chen, Haolin and others},
journal={arXiv preprint arXiv:2409.03215},
year={2024}
}
@article{liu2024apigen,
title={APIGen: Automated Pipeline for Generating Verifiable and Diverse Function-Calling Datasets},
author={Liu, Zuxin and Hoang, Thai and Zhang, Jianguo and Zhu, Ming and Lan, Tian and Kokane, Shirley and Tan, Juntao and Yao, Weiran and Liu, Zhiwei and Feng, Yihao and others},
journal={arXiv preprint arXiv:2406.18518},
year={2024}
}
@article{zhang2025actionstudio,
title={ActionStudio: A Lightweight Framework for Data and Training of Action Models},
author={Zhang, Jianguo and Hoang, Thai and Zhu, Ming and Liu, Zuxin and Wang, Shiyu and Awalgaonkar, Tulika and Prabhakar, Akshara and Chen, Haolin and Yao, Weiran and Liu, Zhiwei and others},
journal={arXiv preprint arXiv:2503.22673},
year={2025}
}
⚠️ 重要提示
本版本仅用于支持学术论文的研究目的。我们的模型、数据集和代码并非专门为所有下游用途而设计或评估。强烈建议用户在部署此模型之前,评估并解决与准确性、安全性和公平性相关的潜在问题。我们鼓励用户考虑AI的常见局限性,遵守适用法律,并在选择用例时采用最佳实践,特别是在高风险场景中,错误或滥用可能会对人们的生活、权利或安全产生重大影响。有关用例的进一步指导,请参考我们的AUP和AI AUP。